
Diffusion学习12-大一统模型
Diffusion模型在图像生成领域已经具备了优越的效果,本博客之前的很多系列篇文章也分别介绍了诸如控制生成、特征保持、风格迁移、图像编辑,但是这些能力更像是插件一样依附在强大的文生图基础模型上,在我们需要某个能力的时候从”仓库“中抽一个出来然后不用再放回去。 联想到目前LLM下统一的生成范式,一个模型可以做所有预研相关的任务(如机器翻译、情感分析等),那么自然而然会联想到图像生成领域能不能有这样一个模型,能同时完成如下图所示的Text to Image、可控生成、编辑、特征保持等各项任务? 大一统模型能做的任务(from.UniReal) 在这种情形下,大一统模型就应运而生,其以一个强大的backbone为基础,在本身就支持T2I的同时,也允许文本之外的任意形式的多模态输入做图像编辑、可..
Read more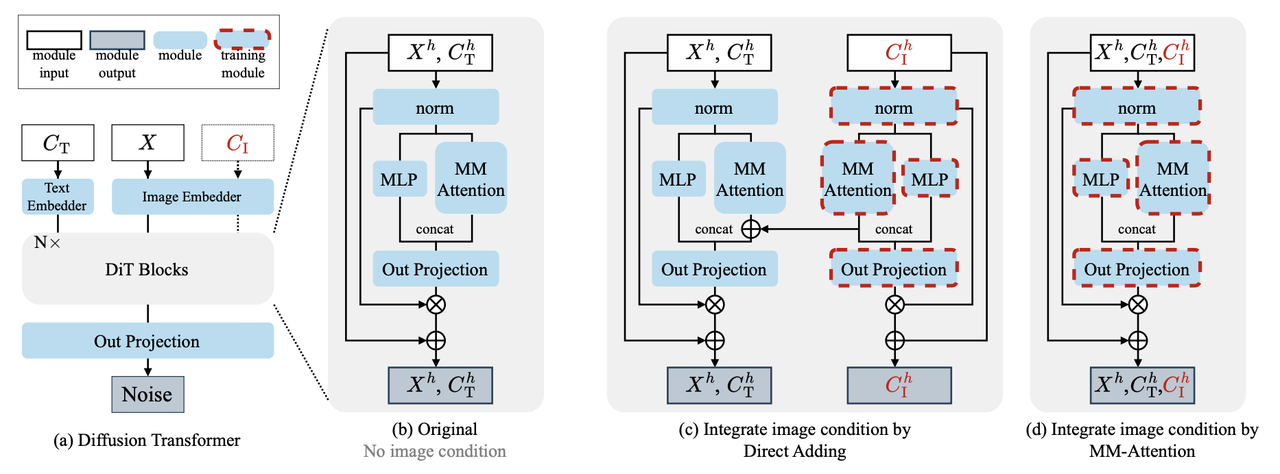
Diffusion学习11-条件生成-基于DiT
之前在这篇博客Diffusion学习6-生成可控性介绍过诸如ControlNet、T2I-Adapter这类在UNet结构上的插件,但是随着DiT结构逐渐取代UNet结构成为Diffusion生成的骨干模型,以往基于UNet结构做的图像控制插件也都发生变化,虽然在pixart-alpha系列文章提到过可以将每个DiT的Block复制为一份可学习的参数然后使用类似ControlNet的方式进行条件注入,但是这种方式其实并没有充分利用DiT框架下transformer这个大杀器的优势。于是各种基于DiT框架的控制插件就出来了。 OminiControl 《OminiControl: Minimal and Universal Control for Diffusion Transformer》 【论文】【代码】..
Read more
Diffusion学习10-图像编辑
图像编辑是Diffusion算法中一个重要的方向,其旨在对生成或者真实的图像进行操作以得到与原图相似却某在某些方面(如背景、主体、风格等)存在不同的效果,具体应用其包含换主体、换背景、主体移动等各种方向。 图像编辑示例(原图来自InstructPix2Pix) Prompt-to-Prompt 《Prompt-to-Prompt Image Editing with Cross-Attention Control》 【主页】【论文】【代码】 prompt2prompt算法框架 算法流程:提出一个training-free的图像编辑算法,无需任何其他数据和优化过程。作者观察到cross-attention层是控制图像空间layout与prompt中每个单词之间关系的关键元素,通过只修改promp..
Read more
Diffusion学习9-风格迁移
一个图像的风格可以看作是图像的色彩、纹理等与内容无关的信息,而风格迁移旨在保证生成的图像具有指定的风格(不管是通过prompt指定还是通过图像指定),对于有指定内容的风格迁移,不仅要求生成结果具有指定的风格,还要保持和内容图具有相同内容(比如语义信息、layout),风格迁移的效果可以参考下面的示意图: 风格迁移示意图,原图来自InstantStyle-Plus Style Aligned 《Style Aligned Image Generation via Shared Attention》 【主页】【论文】【代码】 StyleAligned 算法流程:本算法提出了一个training-free的方法进行风格迁移,在生成的过程中通过共享图像之间的attention特征来保证生成风格一致..
Read more
Diffusion学习8-特征保持
特征保持是Diffusion下一个重要的研究领域,其在给定同主体的一张或者多张图像的情况,生成该物体不同风格、位姿、朝向的图像,同时要保证原主体特征不变【比如粗粒度的类别、颜色,细粒度的纹理细节、人脸特征等】。 特征保持示意图【原效果分别来自CustomNet和PuLID】 其实在之前博客《Diffusion学习6-生成可控性》提到的DreamBooth、LoRA、Textual Inversion等技术就是属于特征保持的算法,但是这类算法多多少少存在训练/推理耗时久、推理数据要求高等多个问题。而最近一些的特征保持算法则在训练速度、生成效果、数据要求上都得到了全方位的优化,所以这里单独开了一个篇章进行介绍。 IP-Adapter 《IP-Adapter:Text Compatible Image Pr..
Read more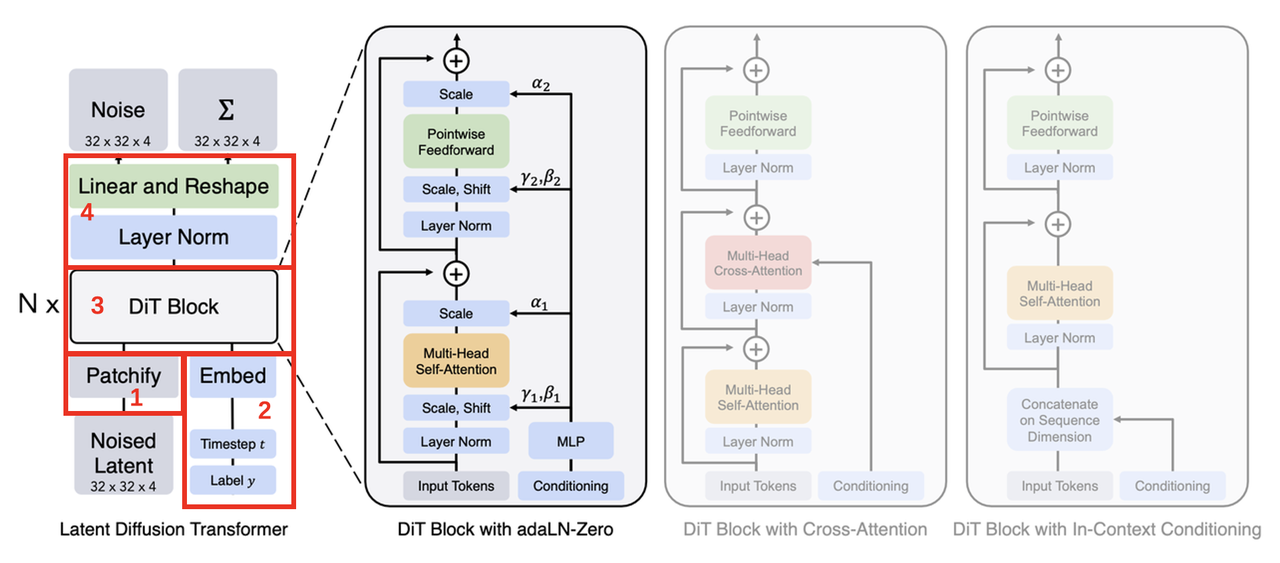
Diffusion学习7-DiT
Scalable Diffusion Models with Transformers 【主页】【论文】【代码】 DiT Block架构 当前主流的Diffusion模型大都采用U-Net模型作为主干网络,U-Net网络的输入和输出具有同样的尺寸,自然也很在适合Diffusion中用于预测与输入noisy latent相同尺寸的noise。但是自ViT后,Transformer结构也已经在多个视觉任务上被验证了其有效性,且相比较于CNN结构的U-Net可能还具有更好的效果。今天这篇论文则成功将transformer结构应用在Diffusion模型上,并且探究了其scalability能力,最终的实验也表明其最大的模型DiT-XL/2在ImageNet 256x256的类别条件生成上达到了SOTA(FI..
Read more
Diffusion学习6-生成可控性
Diffusion相比较起前辈GAN,在生成质量上已经得到了大幅度的提升,之前的文章介绍过虽然通过prompt配合上classifier-free guidance技术能够从一定程度达到控制生成内容的目的,但是如何更加精确控制diffuison结果,例如定制化生成指定的目标对象,控制生成目标的姿态、形状、颜色等,也成为后续研究的重点,当然这些控制性生成目前也已经能够达到下图所示的非常好的效果了,本篇文章也将重点介绍些这些控制diffusion生成的大杀器。 Diffusion可控性生成效果示意效果,原图来自huggingface/lllyasviel DreamBooth 《DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subje..
Read more
Diffusion学习5-高质量文生图模型
高质量Diffusion模型生成结果(原图来自DALLE-2) DALLE系列 DALLE 《Zero-Shot Text-to-Image Generation》 【主页】【论文】【代码-非官方】 DALL·E的名字是为了向艺术家萨尔瓦多·达利和皮克斯的机器人WALL-E致敬 DALLE-2 《Hierarchical Text-Conditional Image Generation with CLIP Latents》 【主页】【论文】 DALLE-3 《Improving Image Generation with Better Captions》 【主页】【论文】 GLIDE 《GLIDE: Towards Photorealistic Image Generation and Editin..
Read more
Diffusion学习4-效果和性能提升
下述效果的具体代码见: qzq2514/Diffusion 效果提升 这里简单实验和讨论了在训练DDPM过程中使用的损失函数(L1或L2损失),并且实验了Improved DDPM 中提到的Cosine Beta Schedule带来的效果提升。 Cosine Beta Schedule 首先回顾下DDPM在前向过程中的一个重要公式-利用重采样技巧从直接得到,即Diffusion学习2-理论推导中的公式(3): 而且在原DDPM论文中使用的线性Beta采样,即: torch.linspace(start=0.0001, end=0.02, steps=100) Improved DDPM则进一步分析了这种Beta设计的缺点,取出论文中的图3和图5: Linear和Cosine的Beta方式对..
Read more
Diffusion学习3-代码实践
先放一张在人脸数据集上训练好后去噪的可视化过程 DDPM可视化去噪 各数据集参数配置及效果 训练: CUDA_VISIBLE_DEVICES=0 python train_solver.py --data_name "Flower102" 在config.yaml中各个数据集使用默认的Training Setting,每个数据集特有的配置见config.yaml下的Train_Data. 生成效果 生成效果如下: 数据集 去噪过程可视化 最终去噪效果 插值 Mnist Fashion_Mnist Cifar10 Flower102 StyleGAN2人脸 上述训练数据集和已经训练好的模型放在这里. 去噪过程可视化中,如果在..
Read more