Scalable Diffusion Models with Transformers
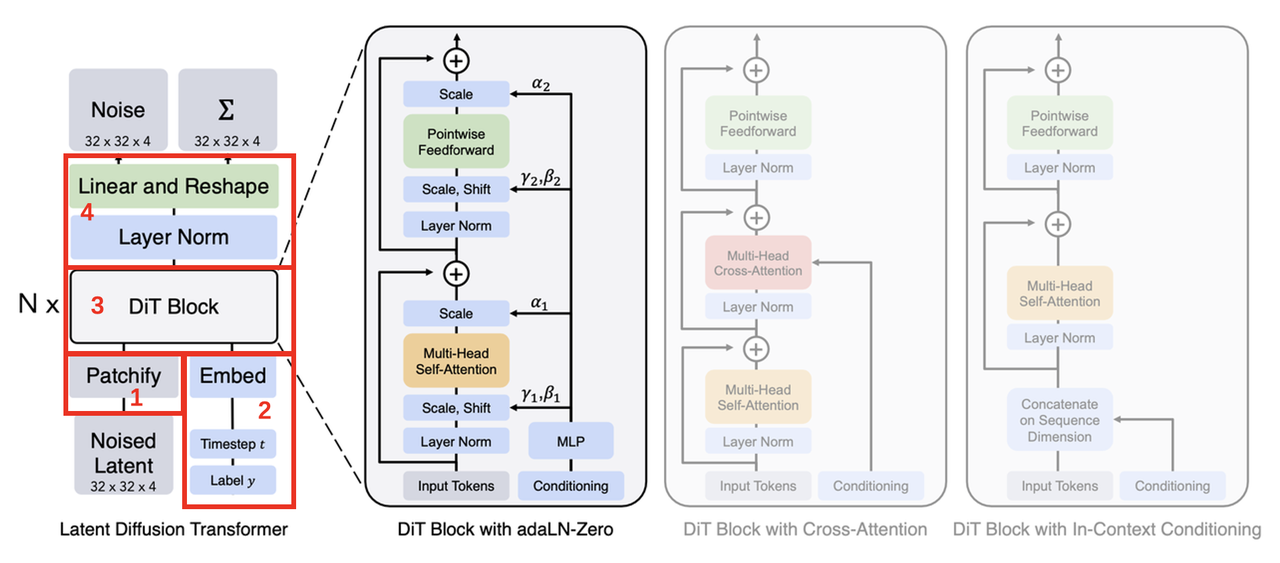
当前主流的Diffusion模型大都采用U-Net模型作为主干网络,U-Net网络的输入和输出具有同样的尺寸,自然也很在适合Diffusion中用于预测与输入noisy latent相同尺寸的noise。但是自ViT后,Transformer结构也已经在多个视觉任务上被验证了其有效性,且相比较于CNN结构的U-Net可能还具有更好的效果。今天这篇论文则成功将transformer结构应用在Diffusion模型上,并且探究了其scalability能力,最终的实验也表明其最大的模型DiT-XL/2在ImageNet 256x256的类别条件生成上达到了SOTA(FID为2.27)。
此外Sora和SD3在技术报告中都提到使用了Diffusion Transformer结构,更是一下将DiT技术引爆!
网络结构
DiT中主要创新点就在于其将transformer结构替换diffusion中的U-Net结构,具体则是上图中红框展示的四个部分,下面👇🏻对这四个部分进行分别介绍。
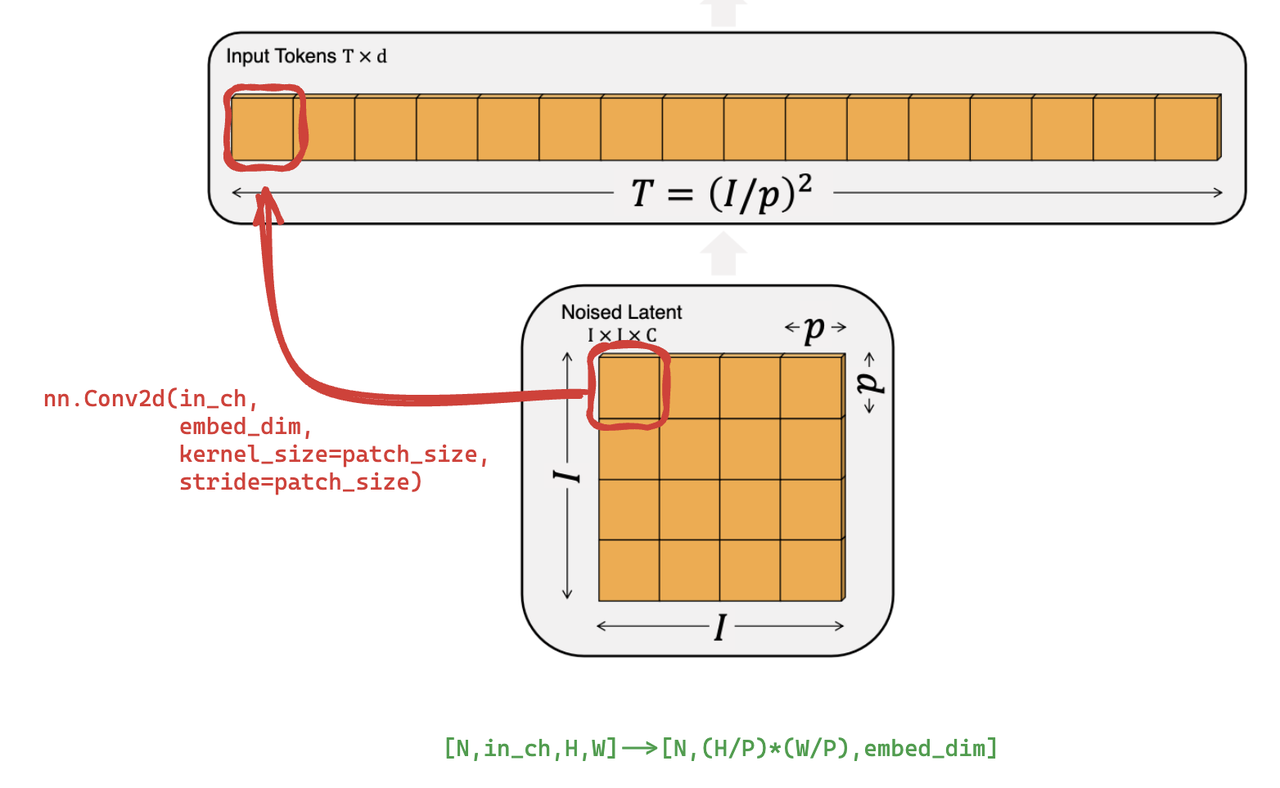
1.Patchify
Patchify操作将2D image转为Patch Embedding,主要过程则是将图像网格化,然后通过一个不重叠的卷积(kernel尺寸=stride)将网格的每个单元变成一个token,该步骤主要通过一个参数精心设计的Conv2D完成。
这个过程中,张量尺寸变化为:
在nn.Conv2D后还要加上position embedding(其实就是Transformer中的常规操作,即非learnable的sin-cosine位置编码)。
2.Timestep & Label embedding
对于扩散模型来说,还需要在网络中嵌入额外的条件信息,比如timesteps以及class
label(如果是文生图就是text
embedding,但是DiT这里并没有涉及,只是用的class
label),将标量的时间戳和imagenet 类别标签变成

3.DiT block design
Adaptive layer norm (adaLN) block
采用AdaLN方法,将之前time embedding和class
embedding相加后,通过一个MLP来回归scale和shift两个参数(尺寸均为
下图左框流程下的张量尺寸都是
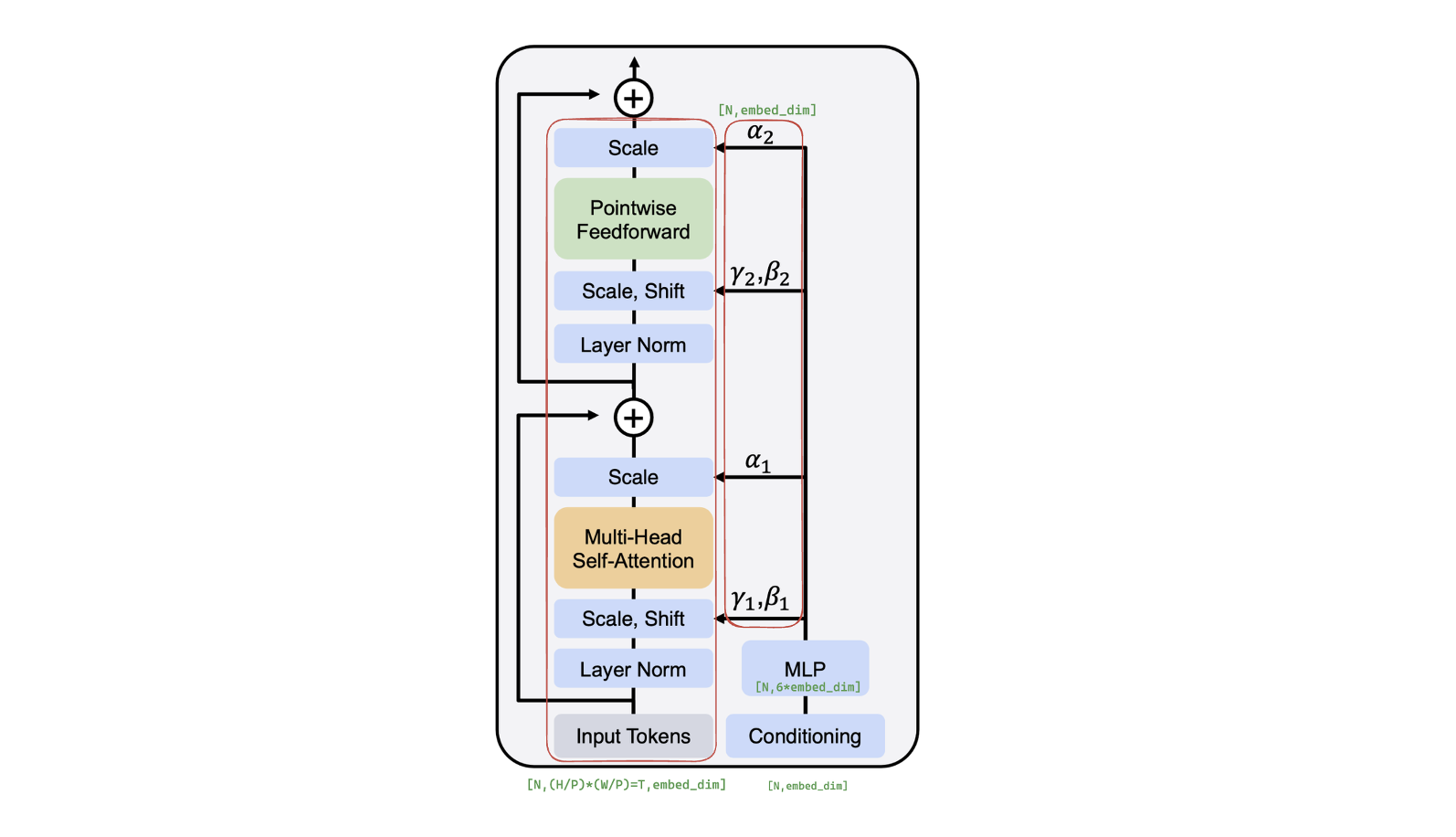
代码实现如下:
class DiTBlock(nn.Module):
"""
A DiT block with adaptive layer norm zero (adaLN-Zero) conditioning.
DiT的核心模块:其实就是一个Mullti-Head Attention + 各种缩放偏移
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return xIn-context conditioning
将两个embeddings看成两个tokens合并后直接拼在图像tokens后,这种处理方式有点类似ViT中的cls token,实现起来比较简单,也不基本上不额外引入计算量。
Cross-attention block
将两个embeddings拼接成一个序列,然后在transformer block中插入一个cross attention,条件embeddings作为cross attention的key和value(同SD将条件作为key和value);这种方式也是目前文生图模型所采用的方式,它需要额外引入15%的Gflops。
PS:【官方代码】代码中对于上面后面两种DiT Blocks的设计暂时没体现,具体结构可以参考本文档最上面的图。
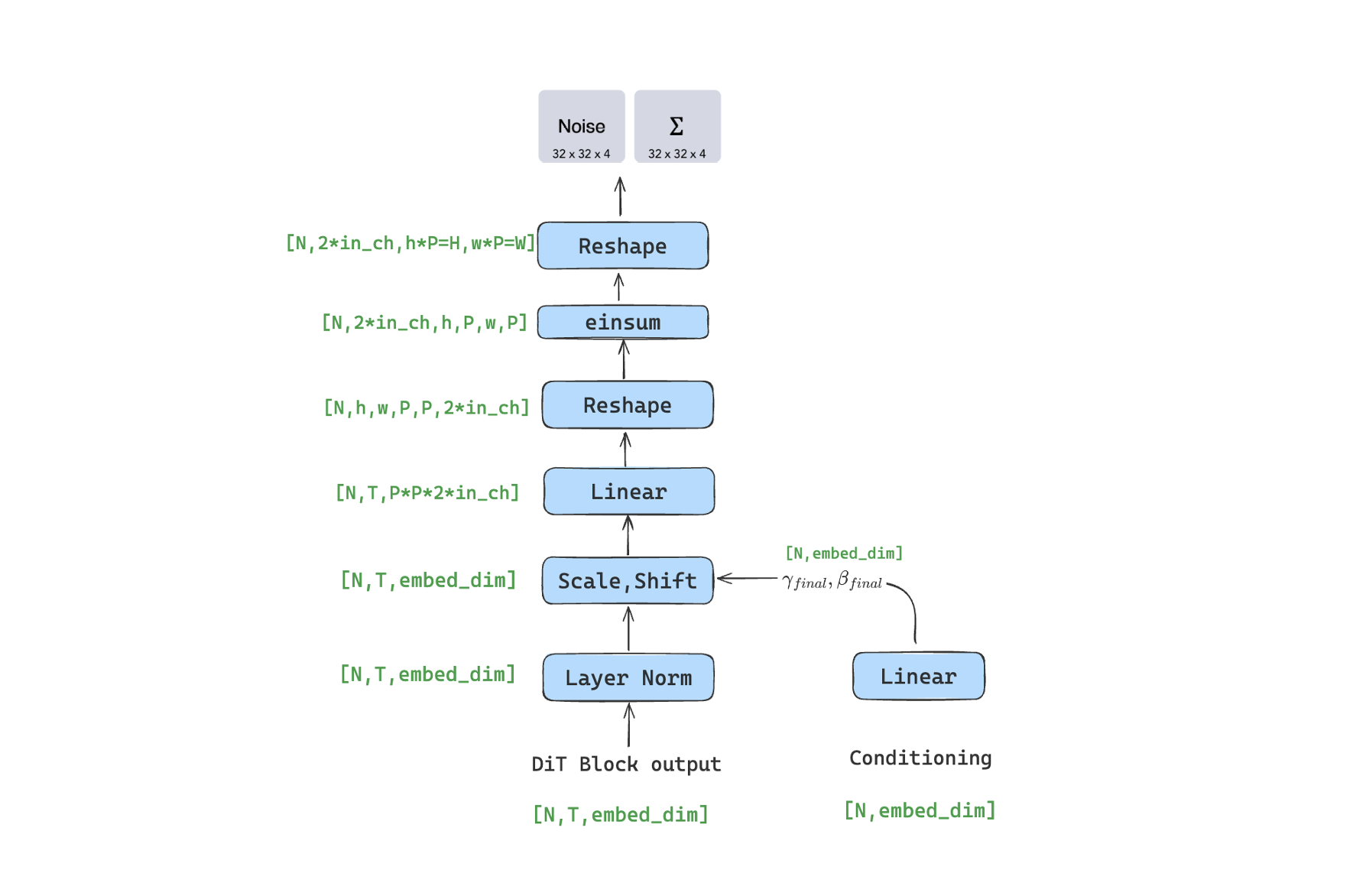
4.Final Layer+Reshape
这里一系列的尺寸变化和reshape操作,将image token转为2D Image形式。
此外DiT沿用OpenAI的Improved DDPM思路,即相比原始DDPM一个重要的变化是:不再采用固定的方差,而是采用网络来预测方差(所以最终网络输出的通道数double了,一半用来预测噪音,一半用来预测方差系数)。
Zero-Initializing
和ResNet、ControlNet的思想一致,将额外补充的部分(比如ResNet的残差分支,ControlNet的控制Encoder)初始化为0,有助于模型收敛,这样在网络初始化时transformer block的残差模块就是一个identity函数。具体进行0初始化的部分包括:
- DiT Block中输出各种偏移/缩放量的MLP参数
- 最后Final Layer中的两个Linear层参数
其他细节
采用模型推理前向时候的计算量作为模型规模的评定,之前的模型参数量与输入图像的分辨率无关,而分辨率又是影响效果的重要因素,所以采用计算量能更好地找到模型尺寸和生成效果的相关。
虽然DiT发现adaLN配合Zero 初始化的设计(在论文中又被叫做adaLN-Zero block )效果是最好的,但是这种方式只适合这种只有类别信息的简单条件嵌入,因为只需要引入一个class embedding;但是对于文生图来说,其条件往往是序列的text embeddings,采用cross-attention方案可能是更合适的。
DiT采用的AutoEncoder是SD所使用的KL-f8,对于256x256x3的图像,其压缩得到的latent大小为32x32x4
扩散过程的nosie scheduler采用简单的linear scheduler(timesteps=1000,beta_start=0.0001,beta_end=0.02)
原生DiT暂时只支持方图的生成。
因为偏移和缩放量初始化为0,所以为了保证原特征值,在进行调制的时候如下所示
def modulate(x, shift, scale): return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
实验
参数量和patch_size对效果影响
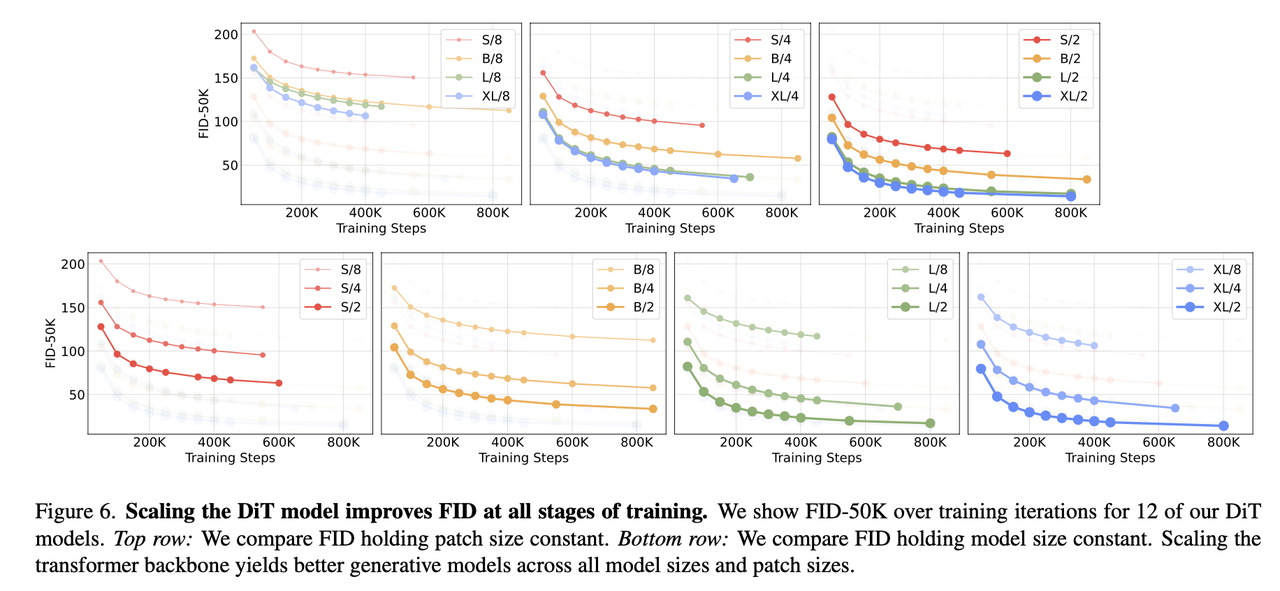
可以看到无论是固定patch size增大模型参数,还是固定模型参数降低patch size,均能够提升生成质量,这两个的共性都是增大了计算量。
控制生成
原生DiT通过ImageNet的类别标签进行控制生成,具体地其将类别标签和timesteps分别embedding后直接相加去预测shift和scale,和仅仅使用类别这是远远不够的,常见的控制方法比如文本控制生成(如text 2image),语义条件(如ControlNet)能达到更高细粒度的控制。
文本控制生成
PixArt-α在原生DiT Blocks的Self-Attention层和Feed-Forward层之间添加了一个Cross-Attention,并将T5提取到的文本embedding送入到该Cross-Attention中达到文本的控制:
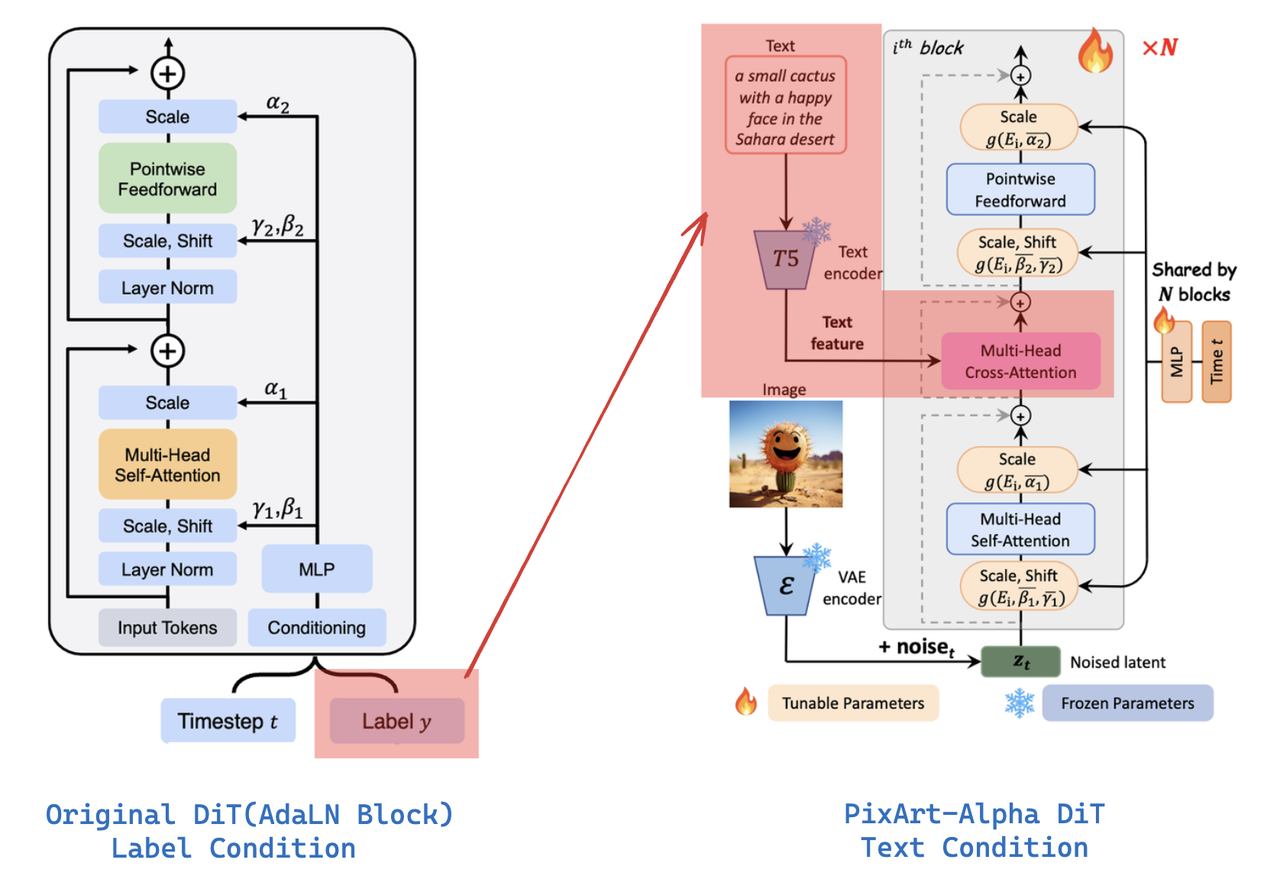
抛开MLP预测shift和scale,上述右图这个是有点类似于原生DiT Block中的Cross-attention block,主不过原生DiT Block是直接将Conditioning(由Timesteps和Label合并后的embedding)送到cross attention,而这里只将text embedding 送到cross attention,而timestep仍然要经过一个MLP预测shift和scale。
细粒度语义控制生成-ControlNet
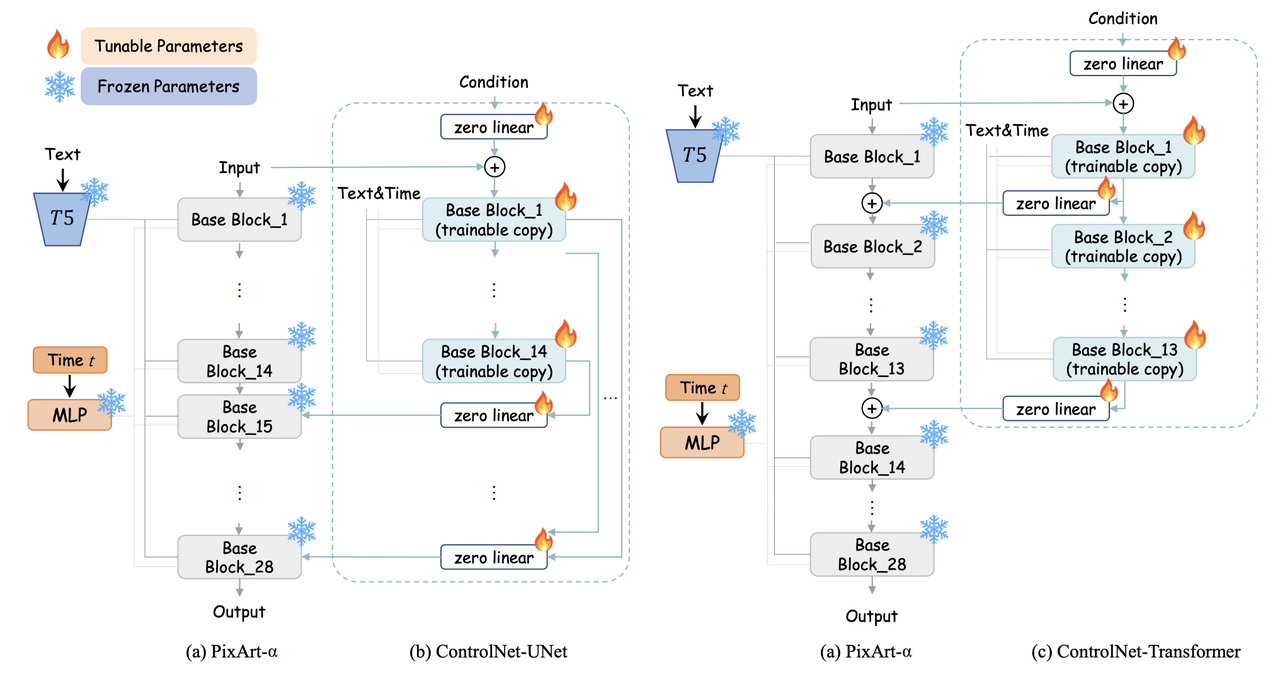
在PixArt-α论文中提到了一句,其将每个DiT Block复制为一份可学习的参数,并在其之前和之后分别添加了一个零初始化的linear层。

具体在PixArt-δ论文中做了详细介绍,首先要知道原始ControlNet拷贝了SD-UNet的Encoder并跳跃连接到Decoder部分,但是Transformers缺少明确的“Encoder”和“Decoder”概念,对此作者进行了两种尝试:
- ControlNet-UNet:类似原生的ControlNet,强行将前一半的DiT Blocks归为"Encoder",将后一半的DiT Blocks归为"Decoder",然后拷贝前一半的Blocks并设置为参数可训练,通过zero-init的linear层后再依次连接到后面对应的Blocks
- ControlNet-Transformer:将前N个DiT Blocks拷贝后设置参数可训练,然后将第i个trainable的block的输出送到zero-init的linear层后,直接和原始第i个冻住的block相加后作为第i+1个冻住的block的输入。
以上两种设计架构示意图如下:
总结
DiT将Transformer和Diffusion这两个强大的技术进行融合,同时也通过实验进一步验证了transformer的scalability,其效果随着模型参数和计算量的增加,效果也会有明显的提升,对于目前大模型和大数据下的Diffusion模型简直就是绝配,相信以后Transformer+Diffusion也将是AIGC下的大趋势。