之前在这篇博客Diffusion学习6-生成可控性介绍过诸如ControlNet、T2I-Adapter这类在UNet结构上的插件,但是随着DiT结构逐渐取代UNet结构成为Diffusion生成的骨干模型,以往基于UNet结构做的图像控制插件也都发生变化,虽然在pixart-alpha系列文章提到过可以将每个DiT的Block复制为一份可学习的参数然后使用类似ControlNet的方式进行条件注入,但是这种方式其实并没有充分利用DiT框架下transformer这个大杀器的优势。于是各种基于DiT框架的控制插件就出来了。
OminiControl
《OminiControl: Minimal and Universal Control for Diffusion Transformer》
【论文】【代码】【HuggingFace】【数据集】
算法流程:
- 基于DiT框架(Flux-Dev)提出了一个高效的image-conditioning生成框架,且只需要0.1%的额外参数量
- 使用一个统一的框架解决大量的image conditioning 任务,如subject-driven生成和spatially-aligned(如depth、canny等)生成
- 提出了一个包含20万张的subject-consistent数据集
算法细节:
Image Condition Integration
本算法以DiT框架下的Flux-Dev为backbone,为了让原DiT模块支持image-condition生成,作者在其中的MM-Attention中拼接上condition-image的token,构成一个完整的token:
,然后以此作为完整token进行attention计算: 其中 为noisy image token, 为text tokens, 为condition image tokens Adaptive position embedding
condition image融入到DiT网络中需要仔细考虑其位置信息,以确保condition image和待生成图像之间的有效交互。此外为了同时支持类似ControlNet一样的spatially-aligned和类似IP-Adapter一样非spatially-aligned的生成。于是作者针对此设计了一个新的position embedding方法。
具体做法是:用VAE将512x512的图像encode到32x32大小的latent,然后根据控制条件的类型制定不同position embedding策略:
- 对于非空间对齐的控制条件(如subject-driven、风格迁移等):基于RoPE方法,在原noisy latent的二维position 坐标上对2维的position进行偏移,如原本的position下标(i, j)都是在0~31范围, 现在偏移后i的范围仍然在031,而j的范围则在3264。
- 对于空间对齐的控制条件(如canny、Depth等):设置成和noisy latent的一样position坐标。但是这个收敛相比较上面偏移的position embedding会慢一点。
Condition strength factor
为了能灵活调整condition image在生成过程中的控制力度,作者针对attention设计了一个权重机制
其中 是一个 大小的矩阵,其中M和N分别是text token和image token(有noisy image latent和condition image latent两个)的长度,该矩阵的形式如下: 这里是通过torch自带的F.scaled_dot_product_attention函数就能直接实现(但是源码中好像是bias矩阵的右上和左下那块也都设置成非0了??)
attention_mask = torch.zeros(query.shape[2], key.shape[2], device=query.device, dtype=query.dtype) condition_n = cond_query.shape[2] bias = torch.log(attn.c_factor[0]) attention_mask[-condition_n:, :-condition_n] = bias attention_mask[:-condition_n, -condition_n:] = bias hidden_states = F.scaled_dot_product_attention(query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask)📢复习:原本F.scaled_dot_product_attention接受attention_mask参数,在(attention_mask元素非bool型时)就是直接加到
后,再进行softmax,具体可以看其源码。 简单来说:该矩阵能保证控制力度只影响noisy image tokens和condition image tokens,而保留了各自与text token的attention关系,控制力度效果如下:

其他:
Subjects200K datasets:基于Flux搭建了一个新颖的数据收集流程,保证subject-consistent,共收集了20万整图像,类别包含服饰、家具、交通工具、动物等。

实验细节:
- 用FLUX.1-dev做spatially aligned任务(如canny/depth控制生成),用FLUX.1-schnell做subject-driven 任务
- 基于LoRA训练,rank=4(具体是在原mlp计算noisy latent的qkv时候加了个lora mlp,然后原mlp和lora mlp对noisy latent计算后相加得到noisy latent的新qkv,同样操作再对condition latent计算得到condition的qkv)
- batch_size=1,gradient accumulation步为8,在2张H100上训练,spatially aligned任务训练了5万步,subject-driven 任务训练了1.5万步
- 评估指标:使用FID、SSIM、MAN-IQA、MUSIQ 评估生成质量,使用CLIP Score评估semantic consistency。使用MSE评估控制生成。使用GPT-4o从5个维度(identity preservation、material quality、color fidelity、natural appearance、modification accuracy )评估subject-driven任务
- 应用:场景变换、虚拟试衣
OminiControl2
《OminiControl2: Efficient Conditioning for Diffusion Transformers》
算法流程:因为attention机制的计算复杂度与序列长度呈二次方增长,所以前一版本OminiControl在image-condition genration时image token太长会导致计算量激增、耗时过长。本算法提出了该算法的升级版本并提出了两个创新性的改进:Compact token representation 、Conditional Feature reuse mechanism。这些改进使得condition相关的计算开销降低了 90% 以上,在多条件生成的场景中实现了 5.9 倍的整体加速。
💡回顾:OminiControl 核心是将来自各种condition token与noise token连接起来,形成一个长序列。然后将这个长序列使用MM-Attention处理,从而实现多模态输入的联合建模。至关重要的是,OminiControl 通过重用Diffusion的预训练 VAE 将condition图像直接编码到潜在空间,从而避免了架构复杂性。这种方法只需额外少量的lora训练参数,显著减少了总参数数量,从而降低了总参数量。这些设计选择使 OminiControl 能够轻松扩展,以最小的开销支持各种condition类型(包括空间对齐的canny控制或者非空间对齐的ip控制生成)。
算法细节:
整个模型框架还是OminiControl,使用token拼接的方式将条件信息注入到DiT中:
。主要创新是提出了下面两个策略来解决多条件情况下,计算量激增的问题: Compact token representation
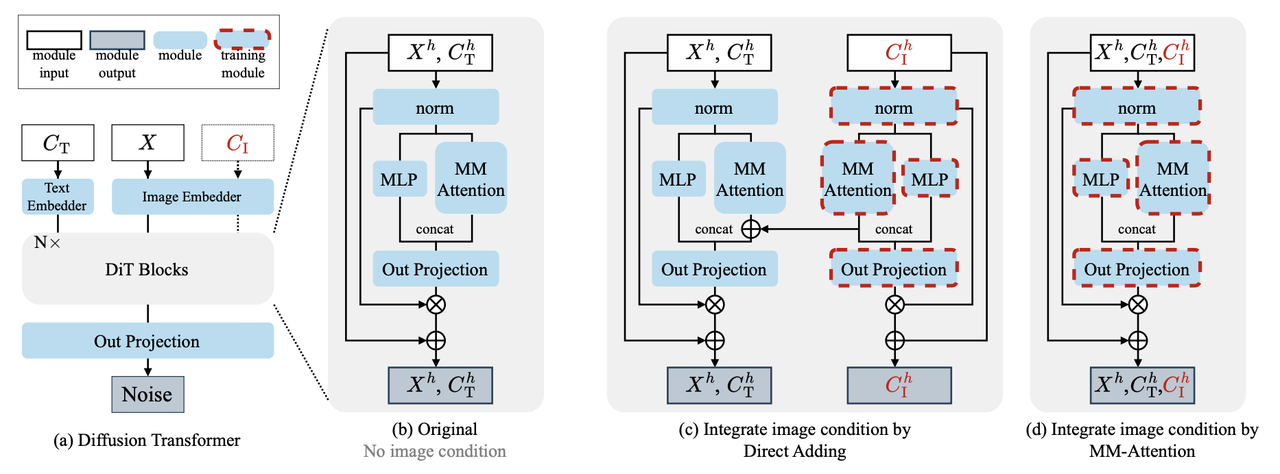
因为attention计算量与token的序列长度成二次方增长,所以最朴素的想法就是直接减少token的个数,可以在VAE-编码之前直接降低condition图的分辨率,比如长、宽的缩小比例为
,且在原本缩小前获得的condition token长度为 ,那么缩小后的condition token长度仅有 。 但是如果直接缩放,那么就会导致condition token与生成结果的token长度不一致,尤其在spatially-aligned的任务中,这种不一致就会导致结果中的一些结构不一致、控制精度下降。为了缓解这个问题,作者额外使用了一个position 修正函数:
即对缩小后condition token的position坐标进行 的缩放。这种映射能确保每个压缩后的token都能引导到生成token中相应的区域,从而保持条件保真度。 除了上面的condition分辨率压缩,作者还使用了一个token剪枝策略,即从condition图中消除无信息量的token。而消除的标准则由具体的condition类型来决定。例如,在canny条件的引导生成中,无边缘区域(canny值接近于零)的token会被消除,因为它们提供的引导信息很少。保留的token的位置信息保持不变,从而在剪枝后保持空间对应关系。
上面的整个过程就可以表示成如下示例:
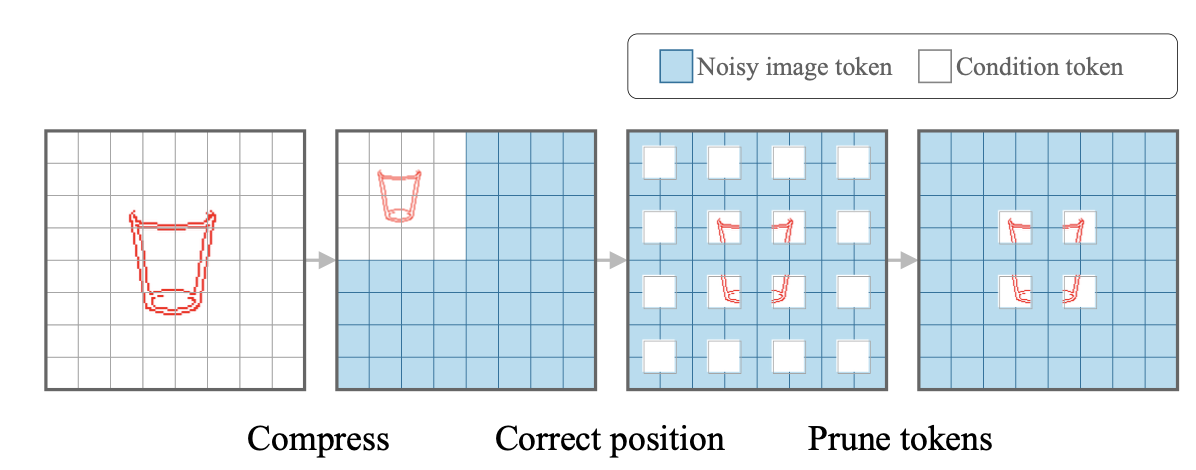
此外作者还针对inpainting任务也专门设计了一个token合并策略,即只在inpainting的区域使用noise,其他位置则直接使用condition对应的token。这样token长度就直接从2N变成N。这种策略好像也比较常见,一般inpainting任务都基本会将noise与condition做插值。)
Feature reuse in DiT
导致 DiT 模型计算复杂度增加的另一个关键因素是在多个denoise步骤中重复处理了condition token。
作者首先计算在不断denoise的过程中noise token与condition token的变化趋势(即分别各自计算不同timestep之间的余弦相似度),下图的实验结果显示虽然noise token在denoise过程中变化较大,但是condition token基本没什么变化。
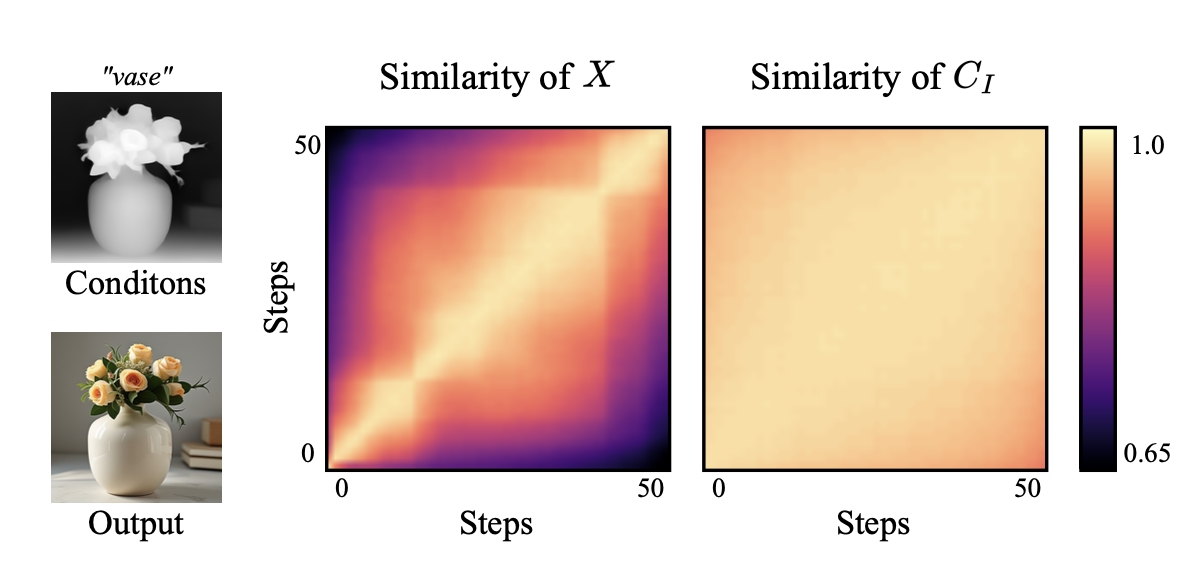
上面的结果表明在每一步都计算一次condition token是冗余的,大可以只计算一次condition token,并在所有去噪步骤中重复使用。
基于上面的发现,作者首先进行了简单的简单的缓存策略:仅仅在第一个推理步骤中仅计算一次condition token,然后在后续步骤中重用这些特征。但这种方法却并不奏效,表明虽然condition token在不同timestep间的一致性很高,但在去噪过程中仍会发生细微的动态变化。所以如果直接简单让condition token保持完全静态,会造成了训练-推理差异,从而降低了输出质量。
上面问题发生的具体原因是在MM-Attention机制下,noisy token和condition token会相互影响,这种影响就会导致condition token在不同timestep之间会发生轻微变化,为了解决上面问题,保证condition token在每个timestep之间都是一样的,作者设计了一个非对称的attention mask。
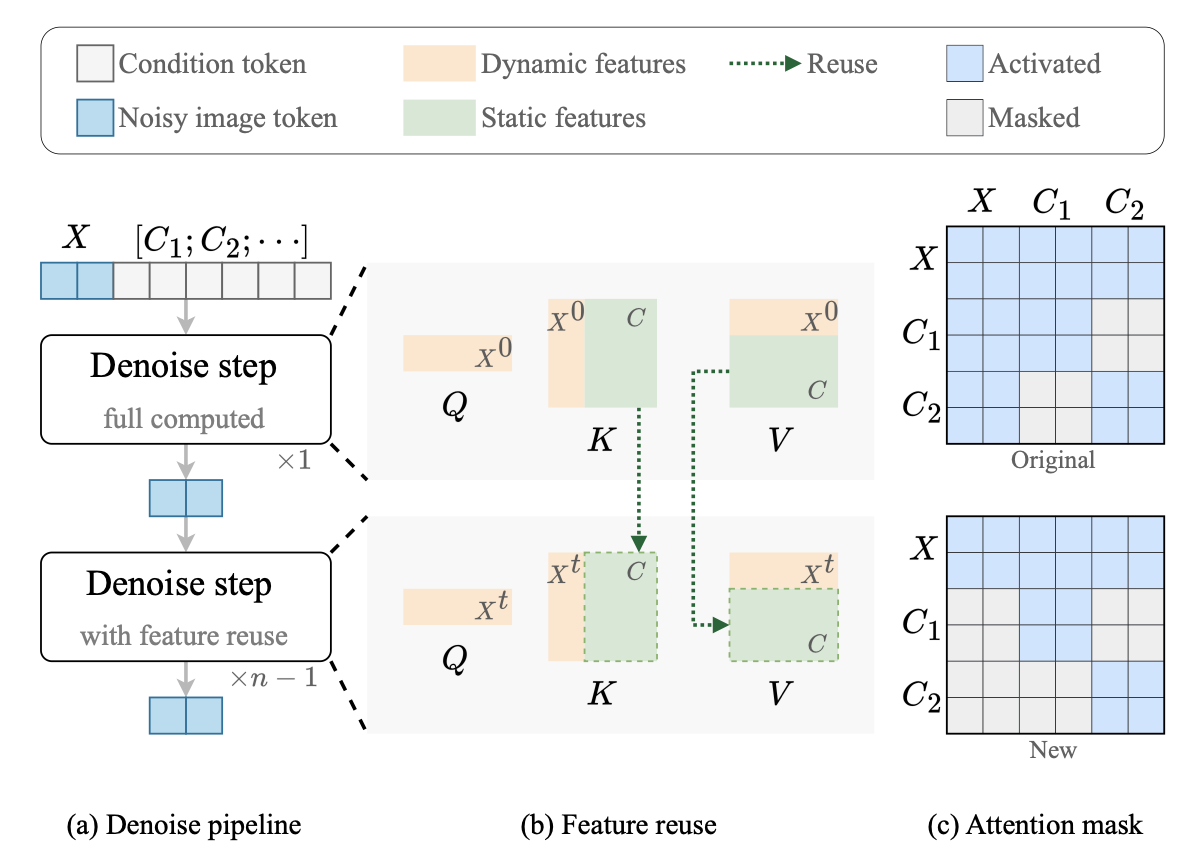
具体做法是:仅在第一步执行完整计算,在之后的去噪步骤中重复使用condition token的KV特征,而在attention mask的非对称设计(即上图最右下角的矩阵)保证condition token会影响noise token,但是noise token不会影响condition token。
作者还进行了简短的计算量分析,表明最终计算量的减少随着timestep和压缩率增加而不断减小,具体过程可以去看论文。
实验细节:
- 以FLUX.1 为backbone,使用LoRA进行finetune,lora rank=4,每个task在单卡H100上训练25K步。
- batch size=1 , gradient accumulation step=4
- 空间特征压缩率为2,保证condition token数量变成原来的1/4。
UNO
《Less-to-More Generalization: Unlocking More Controllability by In-Context Generation》
【主页】【论文】【代码】【HuggingFace】
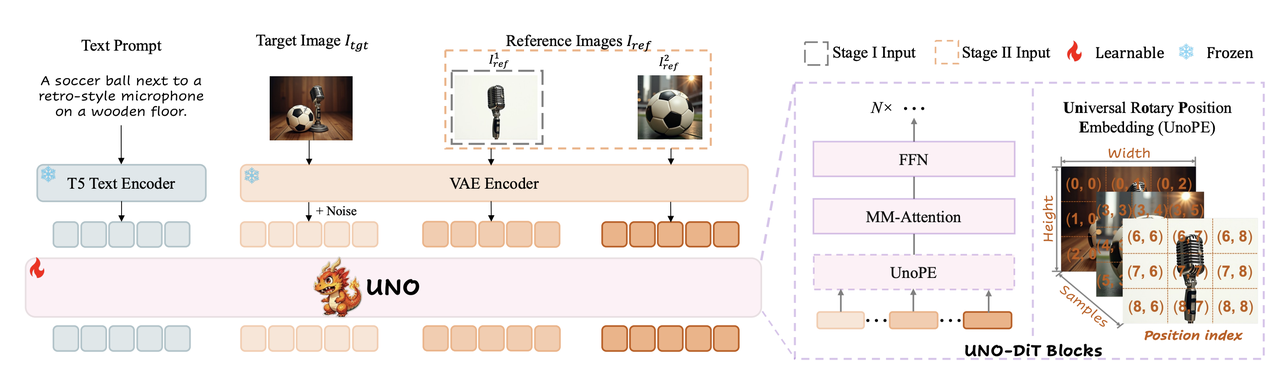
算法流程:提出了一个基于T2I模型的多主体控制生成方法,在单主体和多主体驱动生成中都能实现高度一致性。在数据构造上利用DiT固有的in-context生成能力,开发了模型-数据协同进化的范式,以构造高度一致性的多主体数据。在模型架构上提出了渐进式训练方法,即训练机制使用两阶段的训练:先训练单主体控制再训练多主体控制。此外还专门设计了新的position embedding方法(UnoPE)保证多主体生成效果。。
算法细节-数据(Synthetic Data Curation Framework):
设计了一个高分辨率、高一致性数据合成流程来收集高分辨率和高一致性的单/多主体图像。主要是使用了精心设计的prompt并利用了 DiT 的模型固有的in-context generation能力进行pair数据制作。
同时开发了一种基于VLM的过滤机制来评估生成的图像pair对的质量(高DINO分数和 CLIP-I分数),保证最终图像生成模型在主体上的高一致性。
💡回顾:原OminiControl只能生成512x512分辨率大小的单主体图像
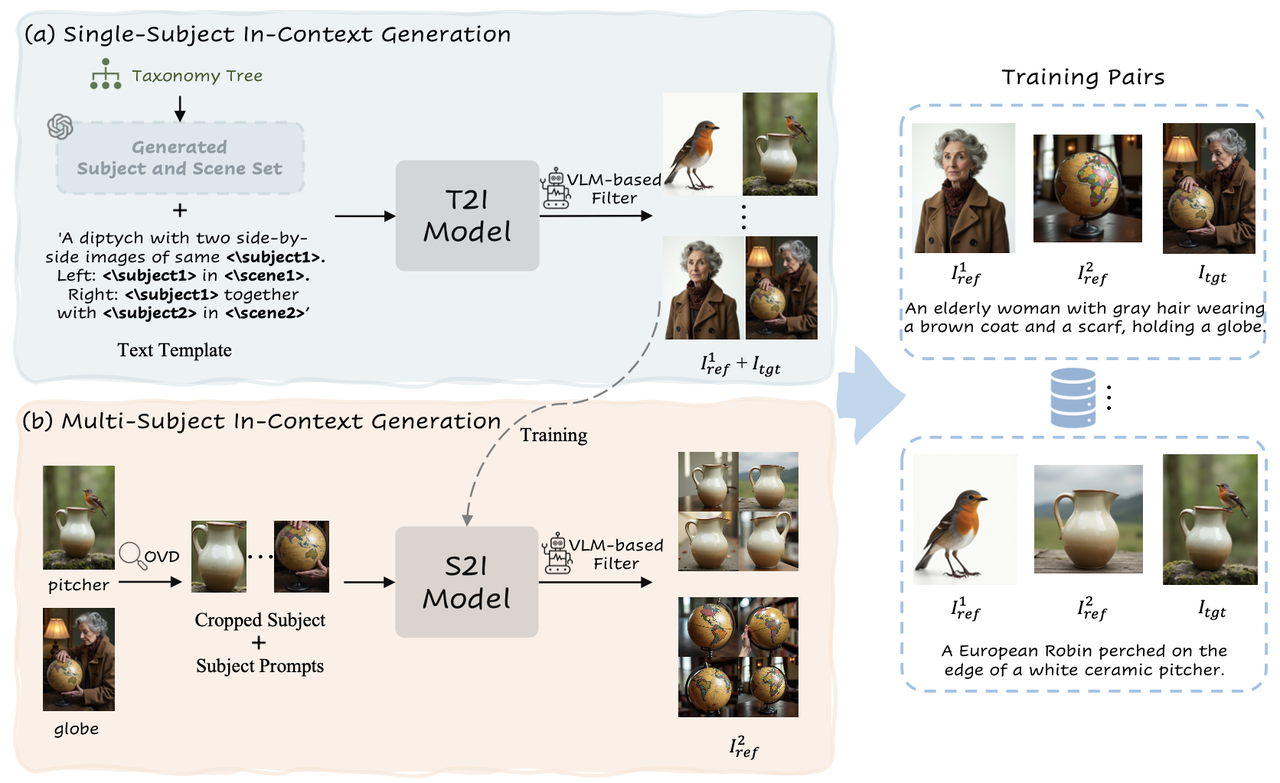
具体数据构造流程分为两个步骤:
Single-Subject In-Context Generation
该步骤主要目的在于构建单主体图像pair对,并借助VLM等工具过滤掉一致性低的数据提升整体数据质量。
构建分类树:依据Object365构造了包含365个主体大类的分类树,在每个大类下又涵盖年龄、职业和着装风格差异等更细粒度的类别。
生成prompt:借助LLM来生成大量主体、场景相关设置。通过将这些输出与预定义的文本模板合并,就得到了数百万个文本prompt。其中文本模版如下:
'A diptych with two side-by- side images of same <\subject1>. Left: <\subject1> in <\scene1>. Right: <\subject1> together with <\subject2> in <\scene2>’ 即构造左右双联画的形式:左边是单个物体在某个场景1,右边是该物体加上另一个物体在场景2 之所以加上另一个物体是为了后面的多主体构造。生成图像:直接使用Flux模型并借助其in-context能力生成一致性的双联画图像。
图像过滤-DINOv2:将双联画对拆分为参考图像
和目标图像 ,然后计算两幅图像之间的 DINOv2分数并借此滤除掉一致性明显较低的图像。 图像过滤-VLM:利用 VLM 提供评估不同更细粒度方面(如外观、细节和属性)的score list,公式示意如下:
其中 表示文本输入, 表示VLM自动输出的评估一致性的维度,score表示score list的平均分数用来表示最终图像pair之间的一致性。
Multi-Subject In-Context Generation.
该步骤主要是在前一个步骤的基础上扩展得到多主体的图像数据,具体包括以下细节:
模型训练:使用前阶段的单主体数据训练一个Subject-to-Image(S2I)模型,该模型以prompt和单主体图(假设其中主体为subject1)为condition为输入,输出该单主体保持的图像。
其他主体检测:使用开放词汇检测器 (OVD) 来识别
中主体subject1之外的主体(假设称为subject2) 其他主体图生成:将
中关于subject2部分的图像剪裁出来送到S2I模型生成该主体的其他图像(比如不同视角的)称为 。得益于Flux强大的in-context能力,生成的 中的subject2和 中的subject2能具有比较高的一致性。 作者认为如果仅仅将
图中关于subject2的区域裁剪后作为 ,可能会引入复制粘贴问题。所以最好还是根据该subject2重新生成其他视角/姿态的图像。
算法细节-模型架构(Customization Model Framework-UNO ):
Progressive cross-modal alignment
模型总体采用类似OminiControl的方法,通过lora的方式将条件图与原始的text token
和noisty latent 在attention层面拼接,公式表达如下: 其中 表示多个参考图。(当然OminiControl只有一个参考图)。 但是鉴于原始Flux 的T2I模型的输入仅包含text token
和noisty latent ,如果同时引入多个无噪声的参考图像标记可能会破坏原始的收敛分布,可能会导致训练不稳定或结果不理想,所以作者设计了一个渐进式生成流程,具体是一开始先训练单条件控制生成模型,并以此作为pre-train再逐步添加多个条件(论文里其实就是2个条件)的控制。 Universal rotary position embedding(UnoPE)
为T2I模型添加多条件控制时,一个重要的考虑因素是位置编码。为了保证多个控制条件与原先的text token和image token有效的交互,作者设计了一个专门的position embedding方法。论文中提到的公式是如下面:
在image token长度为9的情况下,简单理解就是:noisy latent 的PE是从(0,0)到(2,2),然后参考图1的PE就是(3,3)到(5,5),参考图2的PE就是(6,6)到(8,8),以此类推。 作者号称这里提出的 UnoPE 可以进一步防止模型学习参考图像的原始空间分布,从而专注于从文本特征中获取布局信息。这使得模型在保持良好的文本可控性的同时,提高了在主题相似度方面的表现。同时也能有效地缓解算法在多主体控制时可能的属性混淆问题。
💡回顾:原本FLUX使用旋转位置编码(RoPE) 需要为text token和image token分配位置索引 (i,j),从而影响多模态token之间的交互。具体地,text token被分配到一个一致的位置索引 (0, 0),而noisy latent token则被分配位置索引 (i,j),其中 i ∈ [0,w−1] 和 j ∈ [0,h−1]。其中,h 和 w 分别表示noisy latent的高度和宽度。
其他:
实验细节:
- 以FLUX.1 dev 为backbone,学习率1e-5,batch_size=16
- 第一阶段使用230K的单条件pair对训练了5000步,第二阶段使用15K的多条件控制pair对训练了5000步。
- 所有训练在8张A100上进行,lora rank=512
- 构造的数据集的分辨率在1024×1024、1024×768、768×1024中。
评估指标:
- 主体相似度:使用CLIP-I和DINO score计算生成图像与参考图像之间的余弦相似度测量表示。
- 文本保真度:计算text clip embedding和image clip embedding之间的余弦相似度。
消融实验:
- 仅仅将
图中关于subject2的区域裁剪后作为 ,会导致复制粘贴现象。 - 不分阶段的渐进式训练,而是直接进行多条件控制训练,主体保持效果会下降。
- 不使用UnoPE而是直接使用和noisy latent相同的position embedding会导致基本没有主体效果。
- 仅仅将
应用场景:ID保持、虚拟试穿、风格化生成。
局限性:
数据集目前包含有限的编辑和风格化数据。虽然 UNO 是一个统一且可定制的框架,具有足够的泛化能力,但合成数据类型可能会在一定程度上限制其能力。
EasyControl
【主页】【论文】【代码】【HuggingFace】
《EasyControl: Adding Efficient and Flexible Control for Diffusion Transformer》
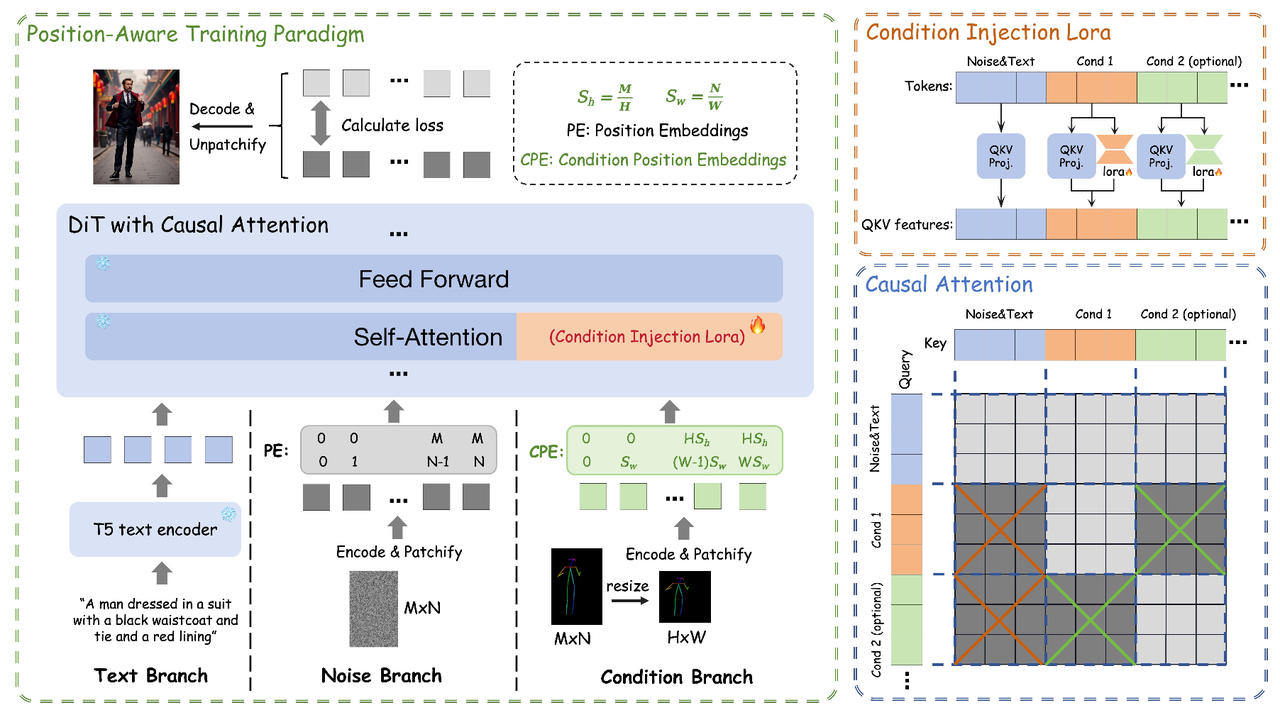
算法流程:提出了一个基于DiT模型的高效且轻量级的控制生成算法,其有三个关键的创新点:轻量级的LoRA控制模块;Position-Aware 的训练策略;配合KV缓存使用的Causal Attention机制。在效果上该方法能够在zero-shot情况下达到较好的多条件控制效果,能够处理复杂的多条件场景,同时扩展到不同的分辨率和宽高比。
存在问题:
- 推理耗时:目前基于DiT模型的控制生成,多是在token层面的拼接,这会导致推理的时间复杂度和模型参数量都与condition的输入长度成平方正比的,严重增加了推理时间,限制了实际应用场景的扩展。
- 多条件控制的冲突:现有方法在单条件训练范式下,难以实现多条件的稳定协同生成。不同条件信号在latent空间中的冲突导致生成质量下降,尤其是在零zero-shot的多条件组合场景中,模型缺乏有效的跨条件交互机制。
- 开源适配性差:之前拼接方式对开源社区的插件(如风格化lora等)适应性差
算法细节:
该算法基于DiT模型进行条件控制生成,主要通过3个核心算法模块实现:
Condition Injection LoRA Module
本质上就是一个LoRA模块,其核心创新在于condition信号的隔离注入。该模块通过额外的一个LoRA分支将控制条件token注入到DiT模型中,原文本和噪声分支权重不变,保留原大模型强大的先验能力。
以上 是condition特征, 是LoRA的升维和降维矩阵, 是condition特征经过原本和noisy latent一样的attenion映射矩阵得到的attenion特征。 相当于原noisy latent和condition都经过相同的attenion映射矩阵得到各自的QKV,只是condition会再经过额外的一个lora矩阵作为偏移量添加到其原来的QKV上。
Causal Attention
将传统的注意力机制替换为因果注意力机制(Causal Attention),并结合了KV Cache技术
提升推理效率,具体来说:
Causal Attention:是一个非对称的attention机制,其保证在nosiy latent、text、多个condition进行MM-SelfAttention的时候进行有选择的attention交互,具体形式原则如下:
nosiy latent和text的token可以query到其他所有token
每个condition只能query到自己,不能query到其他任何token
根据此设计attention的mask
并加到Q和K计算后的结果上: 即M矩阵中能query的地方设置为0,不能的设置为负无穷。通过操纵attention mask来决定attention的作用区域,其实和OminiControl的想法很像 KV Cache技术:上述Causal Attention保证条件分支的计算与去噪时间步无关(只计算一次且不会随着时间戳更新),所以在扩散初始时(即t = 0)处,先计算并持久化保存所有condition特征的K和V,并在后续时间步长
中重复使用这些键值对,从而显著节省计算资源。具体算法流程图如下: 
Position-Aware Training Paradigm
为了提升分辨率灵活性和计算效率,作者提出将condition图的分辨率归一化以缩短输入序列长度,具体做法是将condition图缩放到固定的512x152尺寸,然后再过一遍VAE-Encoder和Patchify操作获取Condition Tokens 再拼接到noisy latent和text token上进行后续的MMSeflAttention。
上述直接对condtition进行缩放,在subject conditions(比如IP保持任务上)上没问题,但是对于需要严格空间位置对齐(比如canny控制生成)的任务则会导致空间位置发生错乱,所以作者对于这两种任务分别采用了不同的策略
严格空间对齐任务:
作者提出Position-Aware Interpolation方法,其实就是在position进行对应的缩放:
假定原condition图分辨率为
,缩放后尺寸变成 ,则宽高维度上的缩放比例为: ,所以在缩放后图像 位置上的patch块,对应于原图的位置为 。该position-Aware插值方法能保证condition和noisy latent的空间一致性。即使在低分辨率控制信号下,该机制也使模型能够有效地学习任意长宽比和多分辨率表示。 非严格空间对齐任务:
采用和OminiControl同样的方法:Position Encoding Offset ,即condition tokens的position embedding做一个简单的平移:
其中 是原condition图像在高度维度单元长度, 用来确保spatial condition和subject conditions 存在严格区分(前者空间严格对齐不发生偏移,后者不需要空间对齐,则正好偏移一个图像高度的距离)
实验细节:
以FLUX.1 dev 为backbone,且该骨干网络是冻住的只训练lora模块,单条件下额外添加的lora参数只有15M。
使用flow-matching 为训练损失
使用4个80G的A100,batch_size=1,lr=1e-4训练了10万步
对于多条件控制,使用各自的lora模块提取各自的condition tokens后全部直接与noisy latent和text token进行拼接,然后进行MMSelfAttention。
数据集:对于严格空间对齐任务,使用MultiGen-20M数据集;对于主体控制,使用Subjects200K数据集;对于人脸控制使用LAION-Face数据集和自收集的多视角人脸数据集
评估指标:
- 可控性(Controllability):对canny边缘作条件的生成任务,计算生成和原始图像边缘的 F1 Score;对于depth作条件的生成任务,计算生成结果的depth和原始depth之间的MSE。
- 文本一致性(Text Consistency):使用 CLIP-Score来评估生成的图像与输入文本之间的一致性。
- 生成质量(Generative Quality):使用 FID和 MANIQA来评估生成图像的多样性和质量。
- ID保持(Identity Preservation):对于subject condition ,使用 CLIP-I和 DINO-I来评估ID保持。具体而言,CLIP-I 使用 CLIP Image-Encoder提取生成图像和参考图像的image embedding然后计算余弦相似度;同样DINO-I使用DINO encoder提取特征计算余弦相似度。
局限性:
- 多条件冲突:在输入冲突的多条件场景中(比如不合理的pose和场景canny),可能会生成重叠层。
- 超高分辨率限制:无法无限地提升生成的分辨率。当分辨率变得非常高时,控制输出的能力就会下降。
作者用该方法专门训练了一个Ghibli风格化的控制模型
DreamO
《DreamO: A Unified Framework for Image Customization》
【主页】【论文】【代码】【HuggingFace】
- 算法流程:
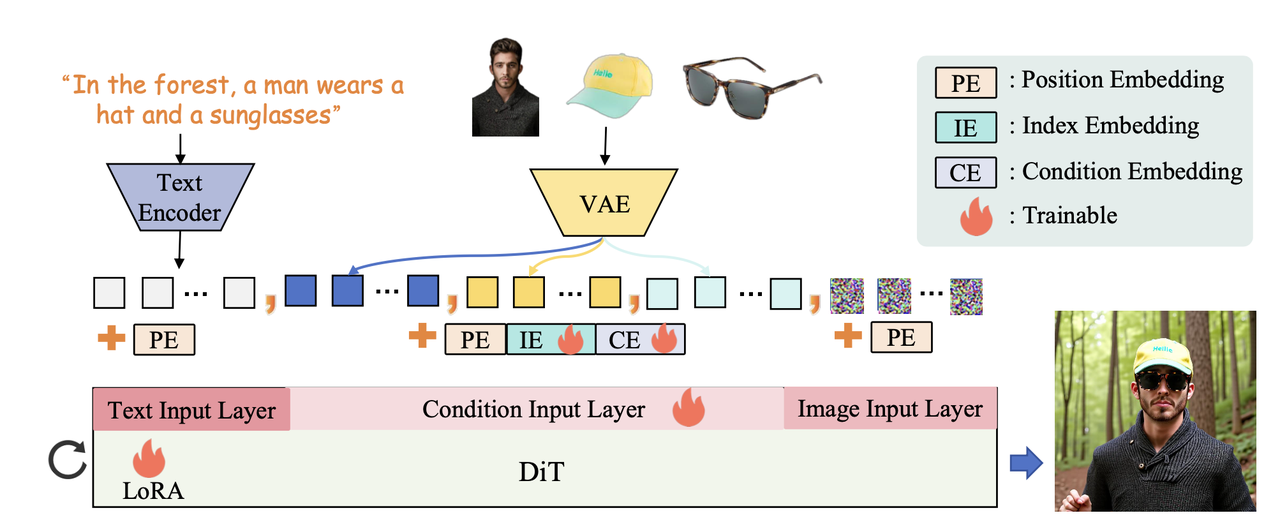
提出了DreamO,一个统一的图像定制框架。通过在pre-train的 DiT 模型上训练少量额外参数来实现各种复杂且多条件的customization任务。在模型架构上并引入了特征路由约束(feature routing constraint ),以便从参考图像中精确查询相关信息;设计了一种占位符策略(placeholder strategy),将特定的占位符与特定位置的条件关联,从而能够控制生成结果中条件的位置;采用了一种渐进式训练策略(progressive training strategy ),所提出的 DreamO 能够高效地高质量地执行各种图像定制任务,并灵活地集成不同类型的控制条件。在数据层面构建了一个包含各种定制任务的大规模训练数据集。
算法细节-模型架构:
几种embedding:
算法对过了VAE后得到的condition token添加了好几种emebdding:
- Position Embedding:受到OminiControl中非重叠position embedding的启发,该算法采用对角线扩展position embedding。
和UNO一样:比如在image token长度为9的情况下,简单理解就是:参考图1的PE索引是从(0,0)到(2,2),然后参考图2的PE索引就是(3,3)到(5,5),参考图3的PE索引就是(6,6)到(8,8),以此类推...
- Learnable Condition Embedding:为了区分latent空间中的condition latent和noisy latent,在输入阶段将leanrable的条件嵌入 (CE) 添加到condition latent中。
- Learnable Index Embedding:为了支持多条件场景,引入了Unireal中提出的leanrable索引嵌入 (IE) ,并根据其关联的条件索引添加到每个条件潜在特征中。作者遵循 OminiControl的设计,将LoRA模块集成到 Flux 中作为可训练参数,使模型能够更好地适应条件任务。
Routing Constraint:
路由约束是为了保证从参考图像中精确查询到相关信息以控制生成。首先有下面的公式:
其中 表示第i个condition token, 表示noisy latent token,结果 表示第i个图像和noisy latent之间的dense similarity,(具体地,二维矩阵 在 位置的值表示condition的第m个token对noisy latent中第n个token的关联度)然后沿着 维度取平均得到 表示第i个condition图像与生成图像中每个区域的相似度/关联度。 据此作者设计了一个路由损失:
该损失主要用在subject-driven任务中,其中i,j分别表示第i个主体在DiT第j层特征索引, 表示目标图中第i个主体的subject mask 。该损失其实就是相当于让subject-driven任务下生成的主体mask更接近target图的subject mask。 
从上图可以看到有了该损失,生成的subeject特征更加明显,在主体区域的激活效果更好。
Placeholder Strategy:
除了上述image-2-image的路由约束之外,作者还设计了placeholder-2-image的路由约束,以建立文本描述和condition输入之间的对应关系。
具体而言,对于第 i 个条件则在相应的实例名称后附加一个占位符 [ref#i],比如"A women from [ref#1] and a woman from [ref#2] is walking in the park. "。在多条件任务的训练过程中,计算condition token和placeholder token之间的相似度。该路由约束确保
[ref#i]的条件图像标记与其自身的相似度为 1,而其与其他占placeholder的相似度为 0。损失如下: 其中 表示 文本 [ref#i]的特征。是一个二值矩阵,当占placeholder与条件图像匹配时,其值为 1,否则为 0。从下面结果图可以看出来有了该策略后可以更好保证生成结果中condition因素与prompt对应。 
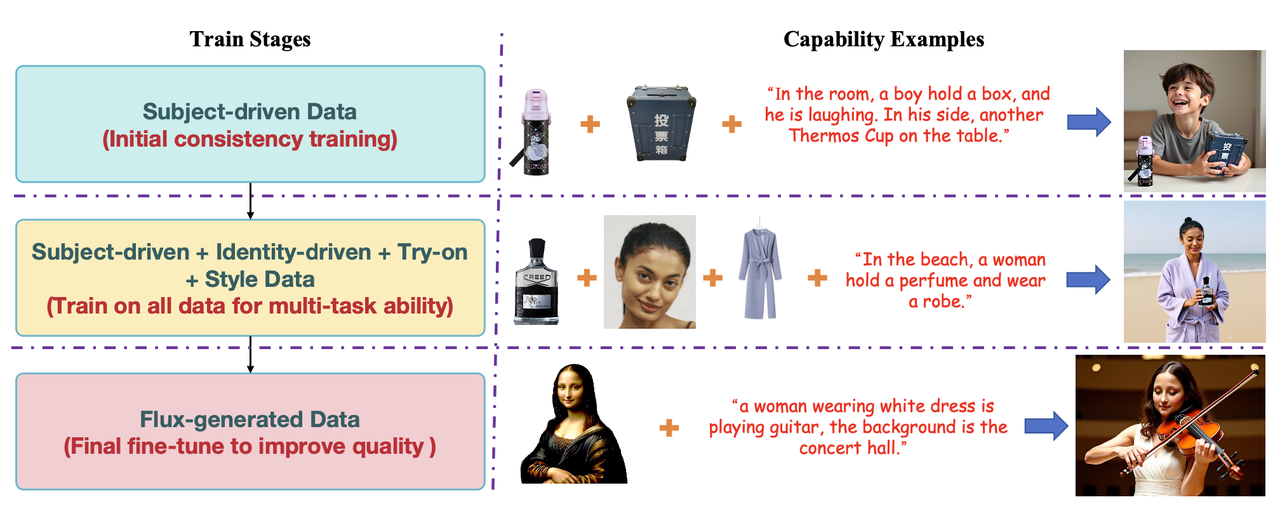
Progressive Training Process:
直接在所有数据上进行一次性训练会导致收敛困难,为了设计了一种渐进式训练策略。总共分为3个阶段:
阶段1:使用subject-driven 数据初始化训练模型,保证模型具有一致性保持的能力。
阶段2:使用Subject-driven、Identity-driven 、Try-on 、Style Data数据训练模型保证多任务能力。
阶段3:使用Flux 生成了大约 4 万个训练样本。并在训练过程中使用原始图像作为参考,引导模型进行自我重构。此外训练过程中丢弃了 95% 的参考图像 token以避免复制粘贴效应。
三个阶段的示意图如下:
算法细节-数据收集:
Identity Paired Data :使用PuLID制作高质量的ID成对图像。具体来说,对于肖像的风格的人脸图像,使用为 PuLID-SDXL ;对于照片级逼真的场景,使用 PuLID-FLUX 生成两张相同身份的图像,然后将它们作为相互参考。
Subject-driven Data:使用开源的 Subject200K数据集和X2I-subject数据集作为训练数据,并补充了一些字符相关的数据集。对于多人像ID的数据,使用类似MoiveGen的方法从视频数据集中采集。
Try-on Data:一部分直接从网络收集(这部分直接以模特和服装的配对图像形式呈现)。另一部分数据则首先爬取高质量的模特图像,然后分割提取其中的服装区域。
Style-driven Data:对于该任务旨在解决两类风格迁移任务:(1)风格图+内容prompt(2)风格图+内容图。前者直接使用类似InstyleStyle的方法构造,后者则在前者的基础上使用Flux-Canny算法生成内容相同的自然图像。流程如下所示:
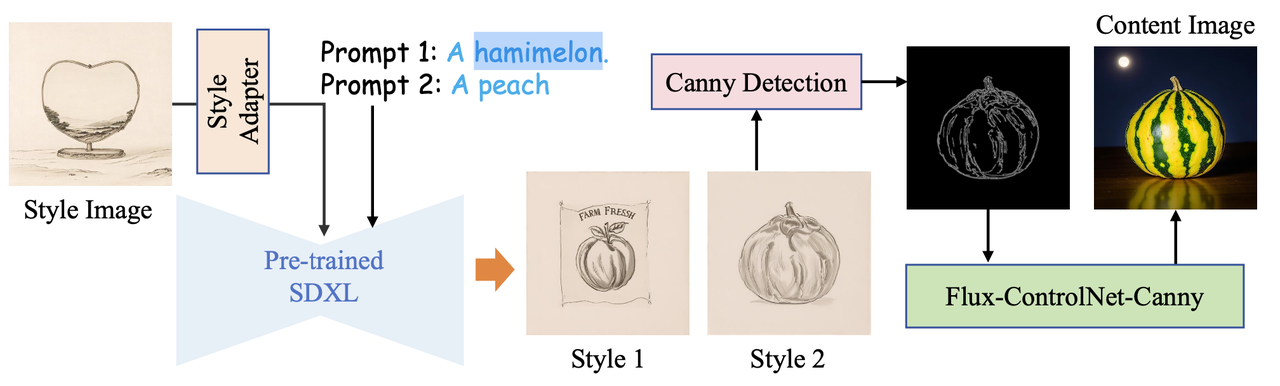
其中
(Style1, Style2,prompt2)构成了第一类风格迁移的数据。再加上Content Image作为内容引导就构成了第二类风格迁移数据。Routing Mask Extraction:
为了获取
所需的主体mask,使用InternVL提取主体caption再配合一些prompt交互式分割方法(如LISA)得到subject mask。 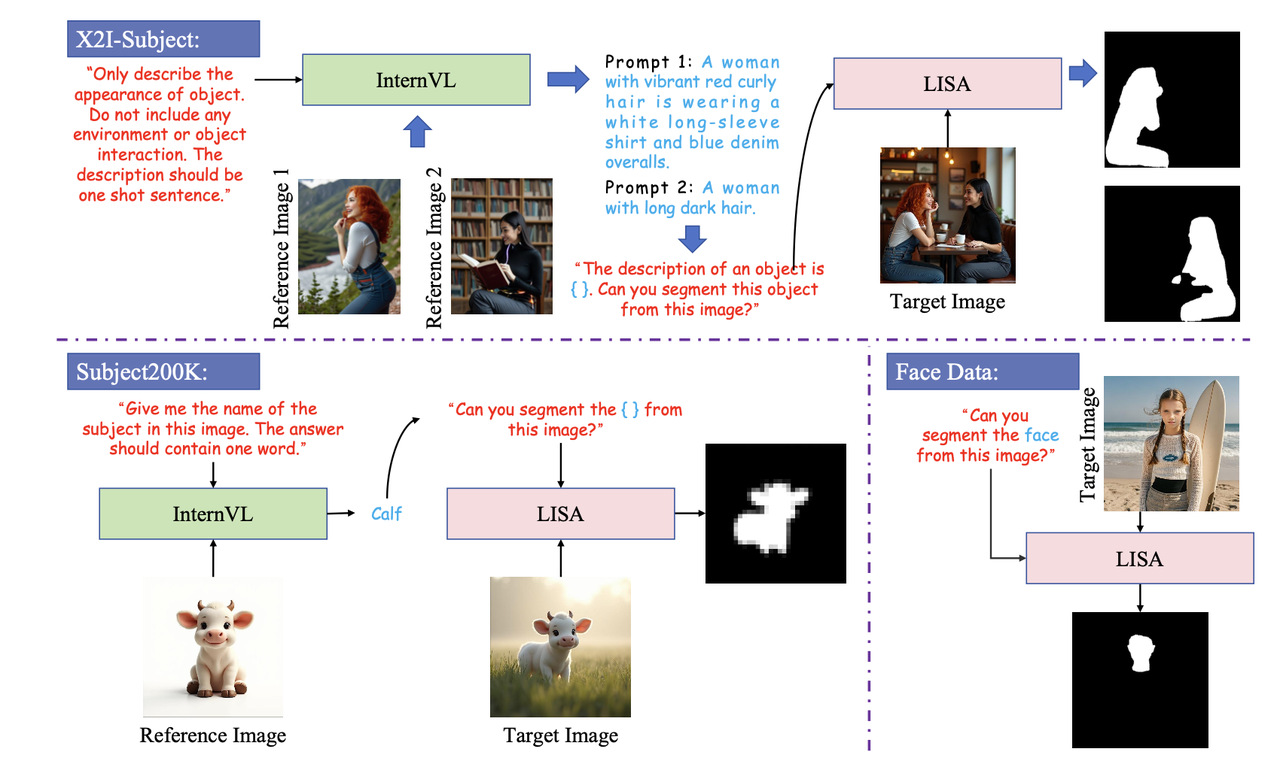
实验细节:
以Flux-1.0-dev为backbone,LoRA rank设置为128(参数量约为707M)
使用Adam优化器,学习率为4e-5,在8张A100上训练,batch size设置为8,三个阶段的训练步数分别为20K,90K,3K步。
算法细节中两个损失
、 再配合原diffusion的 Flow Matching损失 ,求和得到总优化损失:
MUSAR
《MUSAR: Exploring Multi-Subject Customization from Single-Subject Dataset via Attention Routing》
【论文】

算法流程:本算法提出了MUSAR,一个多主体参考的控制生成方法,旨在解决多主体控制生成中面临两个关键挑战:1.多样化、多主体的训练数据的难以获得,2.不同主体之间的属性纠缠。在算法上,引入了去偏差双联画学习(debiased diptych learning)突破了数据限制。其次,动态注意路由机制(dynamic attention routing mechanism)消除了多主体之间的纠缠,也提升了在参考主体数量增加时的可泛化性。
当前问题:
目前大多数基于 DiT 的控制生成方法采用统一的条件策略,联合处理text embedding、noisy latent和 VAE 编码的condition token。这种统一的设计通过完整的attention机制实现了更有效的交互,在单主体生成任务中表现出色。但是这种架构在多对象生成中面临着天然的局限性,因为全局attention机制会引入对象之间的特征干扰,从而导致属性纠缠和身份降级。
算法细节:
回顾下DiT下的T2I模型:
noisy image tokens
和prompt tokens 在序列维度进行拼接 然后进行Multi-Modal Attention: 其中 表示attention flow matrix 用于调节跨模态输入之间的交互。其每一项 控制token对之间的attention强度,其中 表示允许第 i 个和第 j个token之间进行完整的cross attention,而 则完全阻止它们的交互。 而在 FLUX.1 中,M 被初始化为全零矩阵,从而实现对所有图像-文本token之间无约束的双向attention。
De-biased Diptych Learning:
Diptych Learning:
作者使用DiT模型固有的双联画学习能力,从单主体数据集来构造多主体数据集。
具体做法是从单主体数据集中随机选择不同的主体对作为条件参考,然后将它们的结果图像左右拼起来作为双联目标图像。在构造prompt时,condition prompt直接源自原始的单主题描述,并添加“another”修饰语以消除相同类型主体的歧义;目标图像prompt使用结构化的双列模板生成,其中condition prompt自动插入到相应的左/右列描述中。下面是构造的一个多主体的例子:

使用VAE再提取每个condition图特征
和对应condition prompt特征 ,然后把这些特征与原来text token 和noisy token 拼接得到: 其中 表示第i个条件的text token和image token拼接后的长度;c表示condition图的数量;对应地,在原MMA公式中的 尺寸就变成 。 注意这里虽然condition图可以是任意多个,但是在训练的时候c=2。
Diptych Biases Mitigation:
上述方法虽然有效实现了多主体学习,但无意中也引入了两种偏差:(1)prompt bias:使用双联画形式的prompt可能会破坏原本T2I模型的先验;(2)layout bias :统一的双联画排版会导致模型对这种特定的空间模式产生强烈的固有偏好。 为了缓解这些偏差,作者引入了下面图示的两种关键策略:
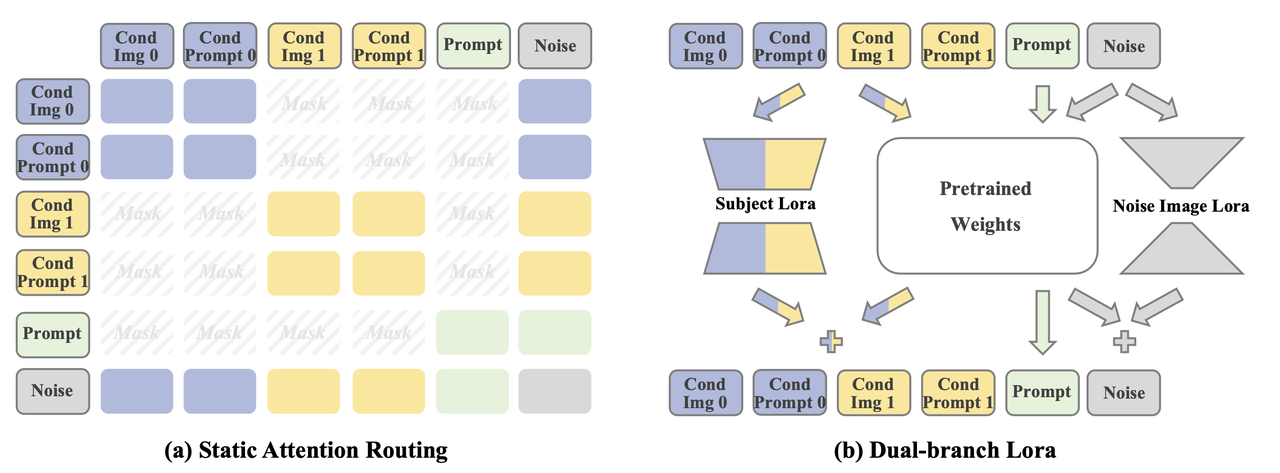
现在分别介绍这两种策略:
Static Attention Routing
针对MMA公式中的M矩阵进行操作,对指定的token pair对进行隔离,具体包括两个操作:
Prompt-Condition Decoupling:禁用prompt与所有condition特征之间的attention关系,即
确保模型专注于保留单个物体的特征。 Inter-Condition Isolation:严格区分不同的条件输入,保证每个条件之间是相互隔离的。即:
其中 且
上面两个公式简单理解就是:noisy latent token代表最终生成结果,其可以与所有token进行交互,而每个condition和text prompt均只能与自己进行交互。
Dual-branch LoRA
对每个输入进行差异化处理:
- 对于prompt:冻结相应的权重而不进行 LoRA 微调,因为表现出固有的模板偏差可能会强化双列图像先验。
- 对于noisy latent token和condition输入:设计了一个双分支 LoRA,结合 low-rank noisy image LoRA 来抑制从目标图像中学习布局偏差,以及一个high-rank subject LoRA 来有效地学习多主题保存。这种非对称秩设计创建了平衡的特征学习,可同时抑制空间过度拟合并增强主体表征学习。
上面简单理解就是:condition信息会额外经过一个rank较大的lora添加到其原本经过pre-trained 权重后的特征上;而noisy latent会额外经过一个rank较小的lora再添加其到原本经过pre-trained 权重后的特征上;prompt则不额外设置lora。
Dynamic Attention Routing:
虽然Diptych Learning和Static Attention Routing减少了主体间的特征纠缠,但对于语义相似的主体(例如同一类别的主体),仍然存在严重的纠缠。
为了解决该问题,作者提出了如下图所示的动态路由机制,保证每个noisy token在attention期间仅关注其关联的主体token,从而显著缓解属性纠缠:
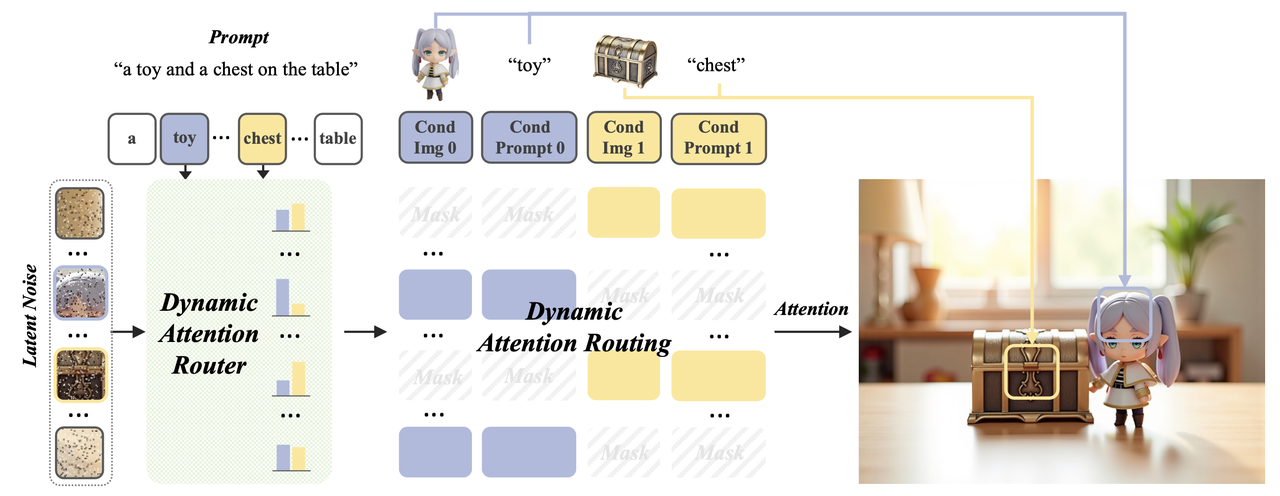
整个步骤如下:
先计算noisy token与prompt token之间的相似性矩阵
: 其中 、 分别表示从noisy token提取的attention query特征、从prompt token提取的attention key特征 通过对每个condition的相关token取平均值,代表noise与condition之间的亲和度得分,具体地,第i个noise token 和第k个condition之间的亲和度分数为:
其中 分别表示与prompt token对应的第k个条件的token起始点和长度,最终得到的 。 基于上述得到的
,对其使用argmax 函数,将每个noisy token分配给与其其最相关的condition,同时屏蔽对所有其他condition的attention,即对标准Attention公式中的attention mask进行重新赋值:
总的来说,动态路由就是对noisy latent中每个主体区域部分找到与其最关联的condition信息,并通过attention mask的方式进行信息交互限制。(这部分中有一些细节还没有搞得特别懂,比如
是怎么获得的?可能都需要看源码进一步理解。)
实验细节:
以 FLUX.1-dev 为backbone,使用双分支 LoRA进行微调,且noisy image LoRA的rank为4,subject LoRA的rank为128
使用Subject200K构建训练集,仅保留质量评级最高(得分 = 5)的样本,最终获得 111,761 个高保真单主体的pair样本。
训练过程分为三个阶段:
- 初始阶段(20K步):通过专门的单主体训练建立基础能力,并开发强大的主体特定自适应能力。
- 第二阶段(10K步):实施策略性混合方案,将 80% 的随机配对的双联画数据与 20% 的单主体样本相结合,培养必要的跨主体生成能力,以保证有效的多主体定制能力。
- 第三阶段(10K步):用同类别双联构造取代随机配对,迫使模型掌握细粒度的类内区分,同时减轻属性纠缠。
- 所有实验均在 8 个 NVIDIA A100 GPU 上进行,batch size为 8,lr为 1e-5,训练分辨率为 512×512。
模型评估:
评估测试集:对于单主体评估,使用 DreamBench中的 750 个完整测试样本;对于多主题场景,通过配对 DreamBench 中的主体来构建测试用例,创建了包含 80 个多主体测试样本的完整数据集。
评估指标:
Image fidelity(图像保真度):使用 CLIP和 DINO计算生成图像与参考图像之间的余弦相似度,分别简称为 CLIP-I 和 DINO。
Multi-subject evaluation(多主体评估):计算每幅生成图像与所有对应参考图像之间的平均相似度。
Text fidelity(文本保真度):使用 CLIP 模型计算生成图像与文本提示之间的余弦相似度,简称为 CLIP-T。
消融实验:
消融模块 具体做法 导致结果 Diptych data 不使用双联画数据进行训练,而仅依赖单主题数据进行训练 生成的结果表现出较差的多主体一致性 Diptych Biases Mitigation 不使用Static Attention Routing和Dual-Branch LoRA(即支持prompt和condition之间交互,且使用一组 LoRA 微调所有参数) 容易从双联画数据提示中学习到偏差,导致在推理过程中强行生成双联画结果,而丢失了prompt中内容 Dynamic Attention Routing 不使用Dynamic Attention Routing,每个区域能够同时关注多个主题。 会出现严重的跨主体混淆,不同主体之间的错误属性纠缠
UniCombine
《UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer》
【论文】【代码】【HuggingFace】【数据集】
算法流程:
提出了一个基于 DiT 的多条件可控生成框架,能够处理任何条件组合,包括但不限于prompts, spatial maps和 subject images。具体地,使用OminiControl提供的几种条件控制lora,并利用新提出的conditional MMDiT 注意力机制来组合这些预训练好的LoRA 模块,构建了training-free版本的多条件控制,此外为了修正该版本下可能存在效果不佳问题,还提出了training版本,即在denoise分支又训练了一个lora来提升生成效果。
还基于Subject200K进行Spatial特征(实例mask图、深度图、Canny图)提取构造了SubjectSpatial200K数据集。
算法细节:
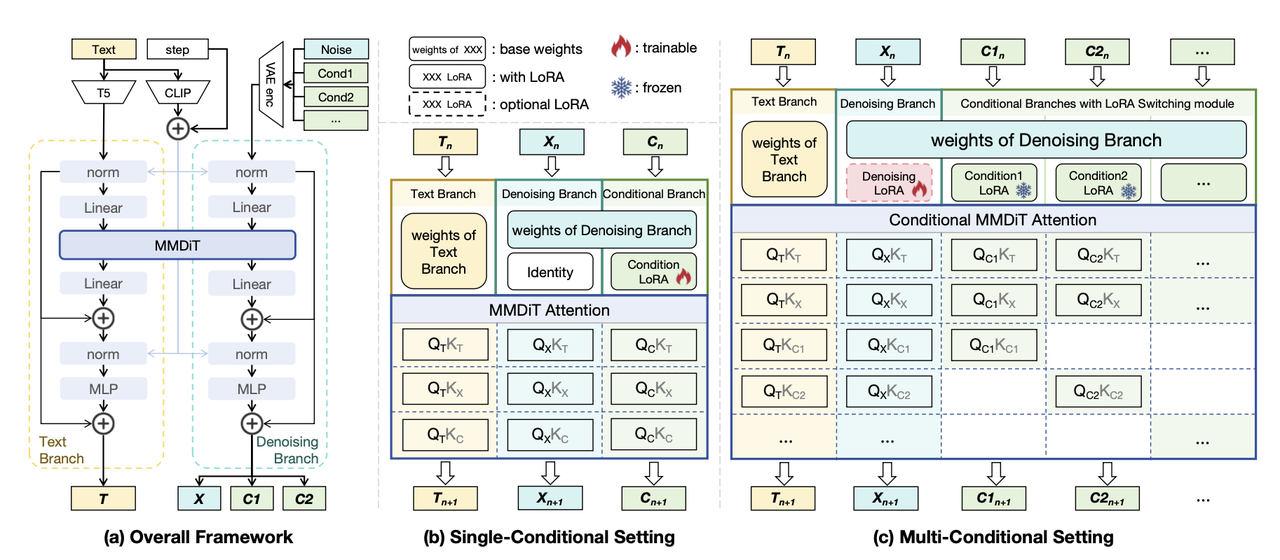
整个算法继承于OminiControl的基本思想:即采用token拼接的方式进行条件注入。并将仅支持单条件控制的OminiControl作为其一个特殊情况。为了支持多条件控制,在此基础上提出了三个新模块:
LoRA Switching 模块:
首先对每种控制条件利用OminiControl进行单条件下lora训练获得对应的Condition-LoRA,然后进行多条件控制的时候将这些lora加载到backbone上,具体做法是,作者设置了一个LoRA Switching 模块,用其对输入条件组合中的每一个条件分别确定应使用哪一个Lora(每个条件会对应输出一个one-hot形式的编码表示选择哪个lora进行激活),随后使用不同的Condition-LoRA 模块来分别处理不同类型的的condition,就得到了所有condition的embedding。该模块可以处理不同的条件组合,更加灵活高效。
论文中这里没有明确指出这里具体是怎么输出one-hot向量的,是基于训练的还是基于规则的?
Conditional MMDiT Attention机制:
在通过LoRA Switching 模块获得了每个condition的embedding后,不能直接送到网络的MMDiT模块进行attention计算,因为两个原因:1)计算量随着condition的数量成
增加,过多的条件和过大的分辨率都会造成计算量大幅增加;2)不同condition之间会相互干扰。为此作者提出了Conditional MMDiT Attention 机制 (CMMDiT Attention) ,简单来说就是禁止不同condition之间做attention计算,即condition 在做query的时候,除了与text embedding的key和noisy latent embedding的key之外,只与自己的key做 计算,这中设置阻止了特征交换并避免了不同条件之间的信息纠缠。同时也将计算量从 降低到 。 其实就是其他多条件控制算法都常用的策略,避免不同conditon之间做attention,比如EasyControl的Causal Attenion和MUSAR的Static Attention Routing。
Training-free策略:
该算法能够无缝集成并有效复用预训练的 Condition-LoRA 模块权重,从而以training-free的方式应对多条件挑战,论文中拆分了attention的计算过程,从两个角度分析了这个原因
noisy latent embedding、text embedding、第i个condition embedding分别计作X、T、Ci:- 当
在 CMMDiT 中用作query时【即流程图(c)部分的Conditional MMDiT Attention下面矩阵的右边3列】:遵循与单条件设置的 MMDiT 相同的注意力计算范式,即只与 、 和本身计算attention矩阵:
这种一致的计算范式使得条件分支能够在多条件设置和单条件设置之间具有相同的特征提取能力。
- 当
和 在 CMMDiT 中用作query时【即流程图(c)部分的Conditional MMDiT Attention下面矩阵的左边2列】:允许从所有的 中提取和整合信息:
这种分而治之的计算范式使text分支和denoise分支能够有效地融合条件特征。
- 当
Training-based Strategy :
在Training-free策略下,仅仅依靠softmax运算来平衡多个condition embedding之间的attention分数可能会导致没那么理想的特征融合结果,使得training-free版本在某些情况下效果不佳。为此作者在denoise分支中引入了一个可训练的Denoising-LoRA模块来纠正attention分数的分布。在训练期间冻住所有Condition-LoRA模块以保留条件提取能力,仅在特定任务的多条件数据集上训练Denoising-LoRA模块。
数据集:
作者基于Subject200K数据集构造了一个SubjectSpatial200K数据集,旨在训练和测试多条件可控生成模型。该数据集包含以下信息:
- Subject Grounding Annotation:在 Subjects200K 数据集上利用开放词汇目标检测模型 Mamba-YOLO-World,根据所有目标的类别描述检测其边界框,并随后导出相应的mask信息。
- Spatial Map Annotation:我们在 Subjects200K 数据集上利用Depth-Anything模型和OpenCV库来导出深度图和 Canny 图。
实验细节:
- 使用FLUX.1-schnell作为backbone,训练分辨率为512x512
- 使用OminiControl预训练好的条件控制lora作为Condition-LoRA。
- 在训练Denoising-LoRA时,rank=4,lr=1e-4.
- 在16张A100上训练了3万步。
消融实验:
Conditional MMDiT Attention:能提升主体生成一致性。
Trainable LoRA:在Denoising分支添加lora比在text分支添加lora更能提升准确性和一致性。
Training Strategy:同时在Flux的Dual-stream Blocks和Single-Stream Blocks 添加Denoising-LoRA比只在Dual-stream Blocks添加,效果要更好。
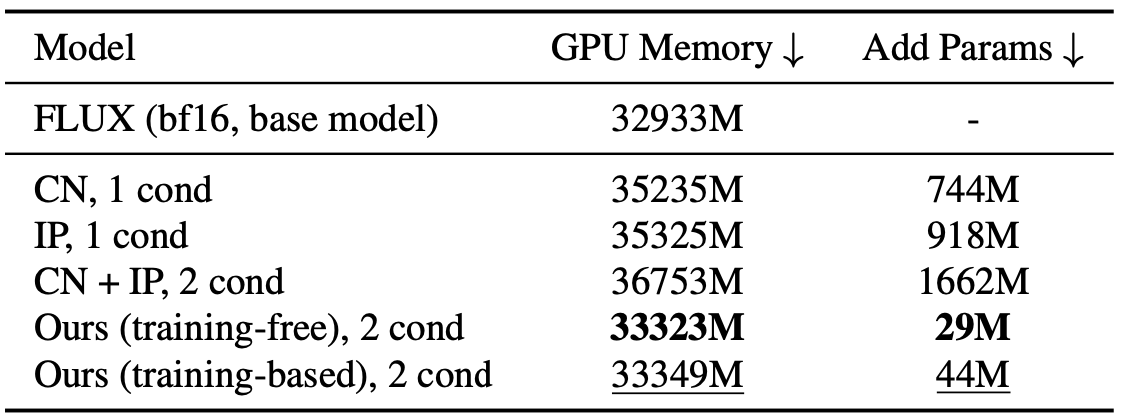
参数量:HuggingFace社区中Flux的控制插件,如ControlNet和IP-adapter通常为了减少内存,只在Dual-stream Blocks添加额外训练参数。为此作者还比较了下不同插件下的GPU Memory和添加的参数量👇
总结
目前DiT框架下条件控制大都是类似OminiControl方式,在token层面进行拼接,通过MMAttention的方式注入到backbone网络中,在多条件控制下会通过操作Attention Mase的方式避免条件之间的信息泄漏。