Diffusion模型在图像生成领域已经具备了优越的效果,本博客之前的很多系列篇文章也分别介绍了诸如控制生成、特征保持、风格迁移、图像编辑,但是这些能力更像是插件一样依附在强大的文生图基础模型上,在我们需要某个能力的时候从”仓库“中抽一个出来然后不用再放回去。
联想到目前LLM下统一的生成范式,一个模型可以做所有预研相关的任务(如机器翻译、情感分析等),那么自然而然会联想到图像生成领域能不能有这样一个模型,能同时完成如下图所示的可控生成、编辑、特征保持等各项任务?

在这种情形下,大一统模型就应运而生,其以一个强大的backbone为基础,支持任意形式的多模态输入并同时支持以上所说的多种任务。
OmniGen
《OmniGen: Unified Image Generation》
【主页】【论文】【代码】【HuggingFace】
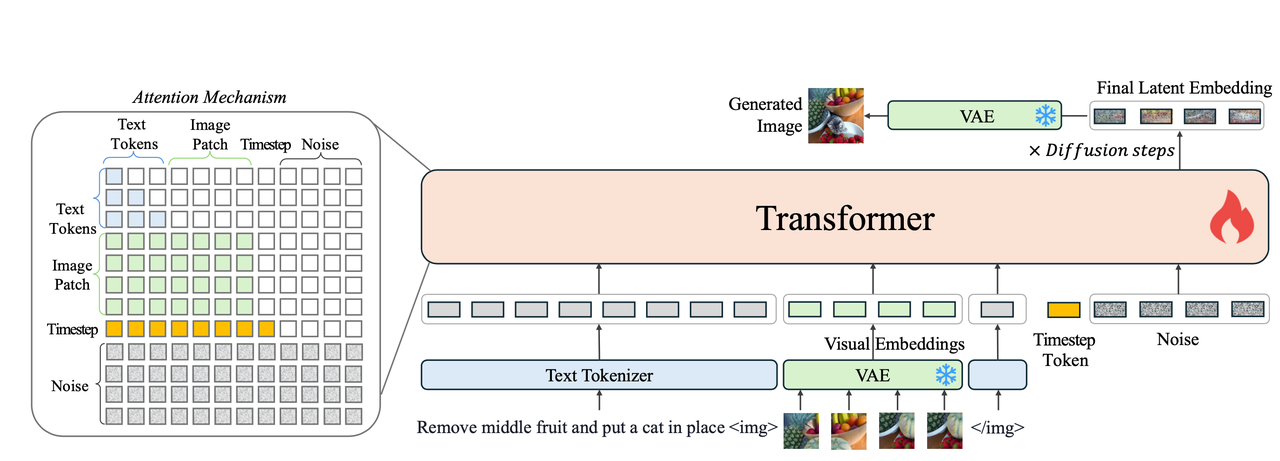
算法流程:
本算法提出了一个大一统的图像生成和编辑框架,其无需其他诸如ControlNet、IP-Adapter 之类的插件就能完成图像控制生成和编辑,也能做分割、去模糊等传统视觉任务。其主要的特点如下:
- 统一性:其不仅仅是一个text-to-image框架,同样也支持很多的下游视觉任务,如图形编辑、主体生成、视觉条件生成。此外其还能将很多传统的计算机视觉任务当做生成任务,如边缘检测、人体姿态识别等。
- 简洁性:模型框架极度简化,无需额外的text-encoder。此外,其支持通过指令形式的prompt完成复杂的生成和编辑,而不需要额外的预处理步骤(例如姿势估计、边缘检测等),大大简化了图像生成之类的工作流程。
- 知识可迁移性:受益于统一格式的学习,OmniGen能有效地在不同任务之间转移知识,即便在未见过的任务和领域也能展现出新的能力。
此外该算法还构建了数据集-名为X2I,代表“Anything to Image”,用统一的数据形式去完成多样的视觉任务。
算法细节:
模型架构:
本着统一性和简洁性的原则,OmniGen网络结构只包含两个部分:
输入形式:
模型接受文本和图像的输入,并将所有的输入token化后统一送到transformer model中,具体输入包括:
- 文本Token:使用Phi-3的tokenizer进行token化;
- 图像 Token:使用VAE提取图像特征并切割成多个patch,并使用DiT中提到的frequency-based positional embeddings代表每个图像token的位置信息;借鉴SD3的思想处理不同宽高比的图像。
- Timestep Token 和 Noise
正如流程图所示:将上面的输入直接在序列长度层面进行拼接,其中对于图像token则会使用
<img> </img>将其包裹起来后作为输入。模型推理:
从Gaussian噪声采样,并利用模型逐步预测噪声后得到latent,再送到VAE-Decoder中得到最终图像。推理步数设定在50步,同时对input condition使用KV-cache提升推理速度。
训练策略:
模型使用Rectified Flow进行模型参数的优化更新,这也是SD3中使用的方法。
回顾:
Flow Matching在噪声和数据之间直接线性插值来进行正向扩散加噪:
不同于传统DDPM最小化预测噪声损失,Flow Matching的训练损失则是回归velocity:
其中 是noisy data,t和c分别是timestep和condition
该算法可以做控制生成和编辑任务,而在图像编辑任务中通常是修改图像中的某个区域而保留其他区域不变,所以有可能会导致模型直接将原图中的区域拷贝-复制到结果图上以满足最小化损失,所以作者在mse损失的时候对不同的区域赋予不同的权重:
相当于对有变化的区域被赋予了更高的权重,从而引导模型专注于要修改的区域。
在整个训练过程中采用AdamW(其中
)在104张A800上训练,此外该算法和SD3一样在训练过程中不断增加图像分辨率,并在不同分辨率的阶段设定不同的训练参数: 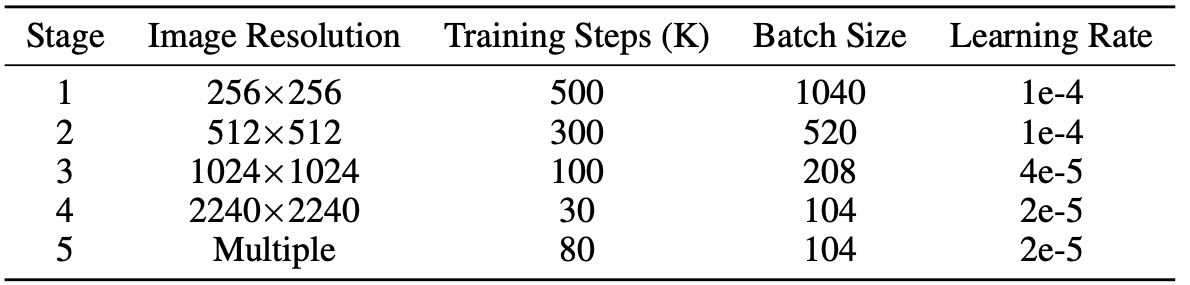
数据集-X2I:
为了满足该算法作为大一统的图像生成和编辑框架,作者构建了一个大规模的统一数据集用于各种图像任务,总数据量有0.1B,对于不同的视觉任务的数据集处理如下:
Text to Image(文生图):
从Recap-DataComp、SAM-LLaVA、ShareGPT4V、LAION-Aesthetic等各种开源数据收集数据。这些数据虽然质量参差不齐但是量很大,在训练初期用于让模型学到广泛的text-image匹配能力是够了。在训练后期(Stage3从1024分辨率开始)则使用了内部收集到的16M高质量数据进行训练,此外很多之前算法都证明使用了详细的caption有助于提升t2i效果,所以作者使用InternVL2对内部数据和LAION-Aesthetic进行打标。

Common Mixed-modal Prompts(多模态混合输入):
输入包括text和image,作者首先从image editing任务(MagicBrush和 InstructPix2Pix等)、human motion任务、虚拟换装任务和风格迁移任务中收集数据集,并处理成如下统一的形式:

具体地作者还使用MultiGen构建类似ControlNet一样的数据集并支持6种控制条件:Canny、HED、Depth、Skeleton、Bounding Box和segmentation
Subject-driven Image Generation(主体驱动生成):

GRIT数据集标注了图像中人物主体的名称,作者在此基础上构建主体驱动的生成任务,具体构建流程如下图左图所示:
先用Grounding DINO根据text生成bounding-box并进行裁剪
对裁剪下来的图像使用SAM得到主体mask
使用MS-Diffusion对重新绘制(主体类别不会发生变化)
最终使用重绘后的图像和原始图像caption作为输入,目标是输出原始图像,最终构建了6M的pair数据,该过程如下图左图所示。
此外作者还利用交叉验证的方式(即判断一组人物是否都在指定的图像中)构建了知名人物的数据集共533000组pair对数据。该过程如下图右图所示。

Computer Vision Tasks(计算机视觉任务):
构建低光照图像增强、去模糊、姿态估计、图像分割等各种传统的计算机视觉任务。作者也通过实验证明这些传统的图像任务对于生成任务也有很好的提升。

Few-shot to Image(few shot图像生成):
作者还构建了一些few shot图像生成的数据集,让模型根据输入自己学习需要做的事情(比如模仿生成深度图、模仿进行inpainting),以激发模型的上下文学习能力

局限性:
- prompt敏感:详细的文本描述会产生更高质量的图像,而过短的prompt会降低生成效果
- 文本渲染能力有限:可以处理短文本生成,但无法准确生成较长的文本。此外输入图像数量限制在最多三个,这使得模型无法处理过多的图像序列。
- 错误的细节:如面部特征偶尔出现不对称,有时也会生成不正确的手部细节。
- 其他:OmniGen无法处理完全没见过的图像类型(例如法相估计)。
支持的任务:

OmniEdit
《OmniEdit: Building Image Editing Generalist Models Through Specialist Supervision》
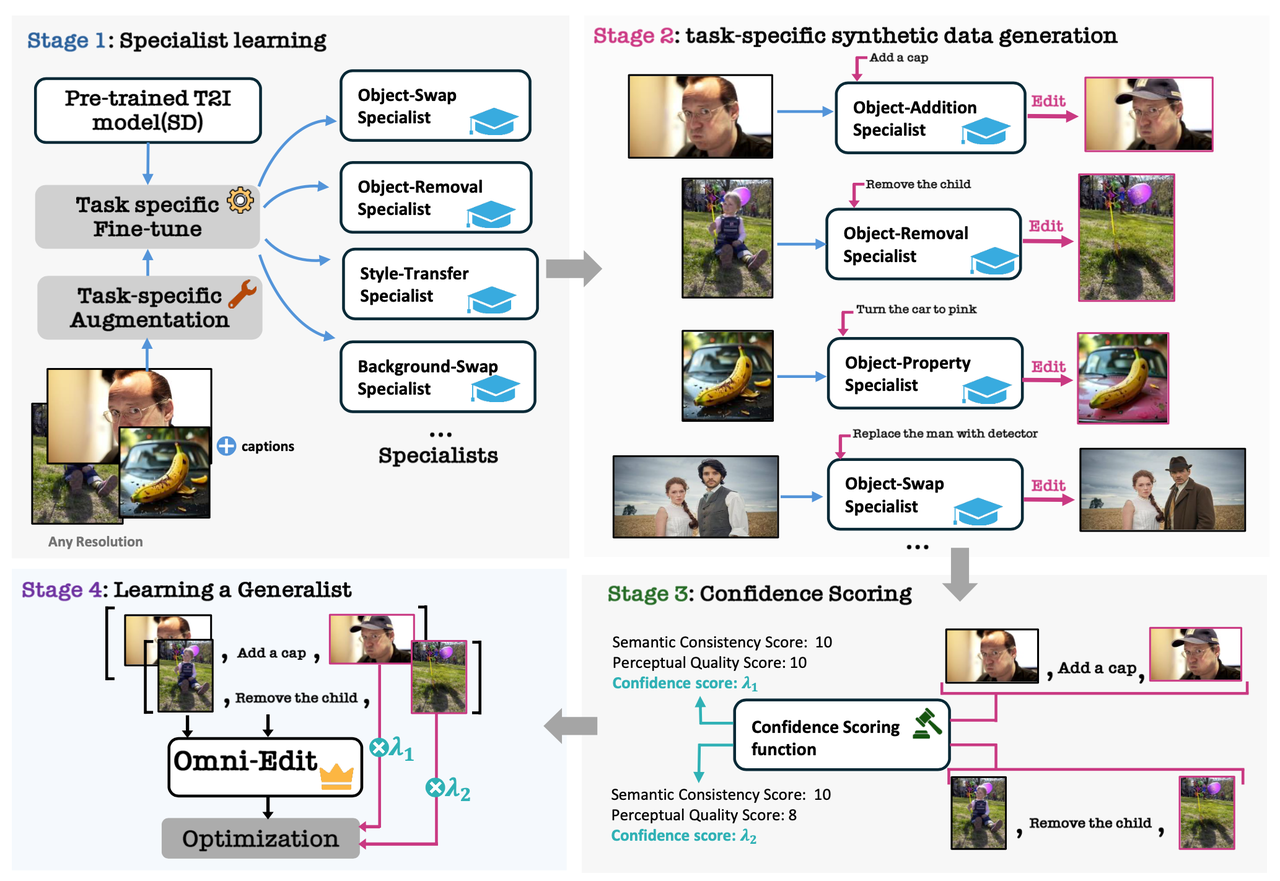
算法流程:提出了一个通用的指令编辑方法,支持主体删除、主体添加、主体替换、属性修改、背景交换、环境修改、风格迁移这7种常见的编辑任务,也支持多种宽高比图像的编辑。算法上则是使用了7种专家模型和重要性采样技术来提升编辑的效果,同时新提出了一个改进的框架EditNet进一步提升编辑水平。
之前的编辑框架的问题和解决:
- 【问题】之前基于指令编辑的开创性方法-InstructPix2Pix是利用prompt2prompt方法造假数据并进行训练的,在该数据上训练会导致明显的偏差,具体包括:
- Limited Editing Capabilities:如Prompt2Prompt方法在局部编辑(例如添加、删除或交换对象)方面表现不佳,而 SD-Inpaint 和 DALLE-2 在全局编辑(例如样式或背景更改)方面则无效。
- Poor Data Quality Control:使用诸如CLIP-score等简化的过滤方法来自动选择训练样本。然而这些指标与实际数据质量的相关性较差,导致训练数据不理想从而对模型产生负面影响。
- Lack of Support for Varying Resolutions:这些模型基本都是在方形图上训练,缺少任意分辨率的支持。
- 【解决】为了解决上面提到的偏差,本文提出了以下4种方法进行解决:
- Specialist-to-Generalist Supervision:通过7种专家监督训练,覆盖7种不同的图像编辑任务。
- Importance Sampling:基于GPT-4o和InternVL2等大模型评分,并结合重要性采样提升训练数据质量。
- EditNet Architecture:新提出了EditNet架构,增强模型对多种编辑任务的理解能力。
- Support for Any Aspect Ratio:支持任意长宽比,确保模型能够处理现实世界中的各种图像。
- 【问题】之前基于指令编辑的开创性方法-InstructPix2Pix是利用prompt2prompt方法造假数据并进行训练的,在该数据上训练会导致明显的偏差,具体包括:
算法细节:
训练损失:
其中
则表示专家模型, 表示重要性采样函数,这两个后面会详解介绍。 上述这个过程可以理解为:首先从数据集 D 中采样一对原图
和编辑指令 ,然后根据指令选择相应的专家模型 来采样得到编辑结果 ,然后通过重要性采样函数得到权重后计算最终的损失。其中编辑函数 旨在依次接受noisy latent、原图、指令prompt来输出最终的编辑结果。 作为参考,作者将原T2I模型的损失和Image editing的损失分别表示为:
其中
、 、 分别是prompt、原图、编辑后结果。 构建专家模型:
作者针对图像编辑中7种常见的编辑任务分别构建构建了7个专家系统:
Object Replacement:训练了一个inpainting模型
。具体地使用GroundingDINO和SAM来分别检测和分割出原图像 中的某个主体 的mask 。使用 GPT-4o对图像进行分析然后选择合适的替换新主体 ,然后对 做膨胀后开始图像编辑: 得到的pair对即为: ,其中 即为编辑指令:“Replace with ”。 Object Removal:同主体替换一样也是使用了一个inpainting模型
作为专家模型。同样方法得到原图像 中的某个主体 的mask ,只不过caption变成了描述背景的prompt,最终编辑公式为:
得到的pair对即为:
,其中 为编辑指令:“Replace from the image ”。 Object Addition:将其视为Object Removal的逆过程,将其中的原图和编辑结果图替换下位置即可,最终得到的pair为
,其中T即为编辑指令:“Add to the image ”。 Attribute Modification:主要使用Prompt-to-Prompt 方法修改图像中某个主体的属性。具体地先从这里采样一个SD的prompt
然后用SD模型生成原始图像 ,然后用GPT4 识别 中的主体 并生成一个修改属性后的prompt ,然后利用pair的prompt对 送到Prompt-to-Prompt算法中生成pair对的图像作为属性替换前后的原图和结果图。此外作者还利用GroundingDINO和SAM来检测主体mask 并借鉴Emu Edit中的方法使用该mask来辅助编辑保证背景尽量少的被改变,提升编辑准确性。 Background Swap:使用类似Object Replacement的方法,主不过将mask取个反,即将要替换的从主体变成背景。
Environment Modification:同样使用Prompt-to-Prompt方法修改图像的背景环境(如春天变冬天),并且也检测出前景区域并保证前景尽量不被修改。
Style Transfer:使用CosXL-Edit方法作为风格迁移的专家模型,即输入
输出
Importance weighting function:
重要性采样函数
接受3个输入<原图、编辑结果图、编辑指令>,输出则是重要性权重,具体意义在于对于那些编辑的好、质量更高的数据有着更高的权重。具体地,作者使用GPT-4o来对每个数据对进行0~10范围的打分,并过滤掉低于9份的数据对: 具体在实践过程中则是针对每个编辑任务使用GPT-4o进行打分后分别获得5万的数据,然后finetune一个8B版本InternVL2来对完整的大规模数据进行打分,最终一共获得77.5万的数据。 EditNet:
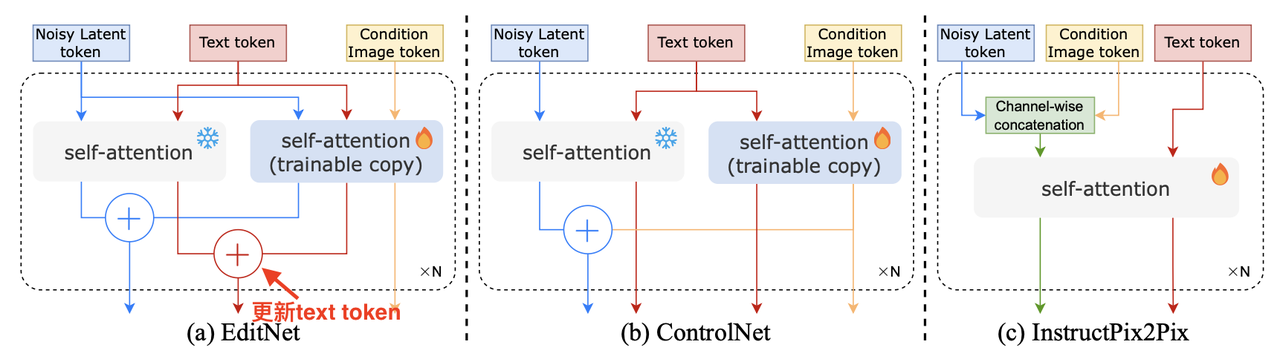
整个算法以DiT模型为BackBone并且为了让在T2I任务上训练的大模型(如SD3)能够做编辑任务,作者设计了一个EditNet,具体做法为:借鉴ControlNet的思路,对原Backbone进行部分复制得到一个控制分支,控制分支中的DiT块允许原始 DiT token、条件图像 token 和编辑提示之间的交互。
EditNet相比较ControlNet有2个优势:
ControlNet 不会更新text token,这使得其无法执行指令的编辑任务。而EditNet的控制分支在接收text toekn后会和主分支的text token输出进行合并作为后续新的text token
ControlNet 的控制分支和原分支是并行运行,原分支的内容是不会影响ControlNet的中间表征的。EditNet则会将新的text token和condition image token都合并到主分支,加强了特征融合。
实验细节:
训练数据集:以LAION-5B和OpenImageV6为准,从中收集像素不低于100万的图像,宽高比包括1:1、2:3、3:2、3:4、4:3、9:16和16:9 ,通过上面介绍的Importance weighting function方法,构造的数据集共有77.5万的数据对,每个编辑任务的数据量如下👇。
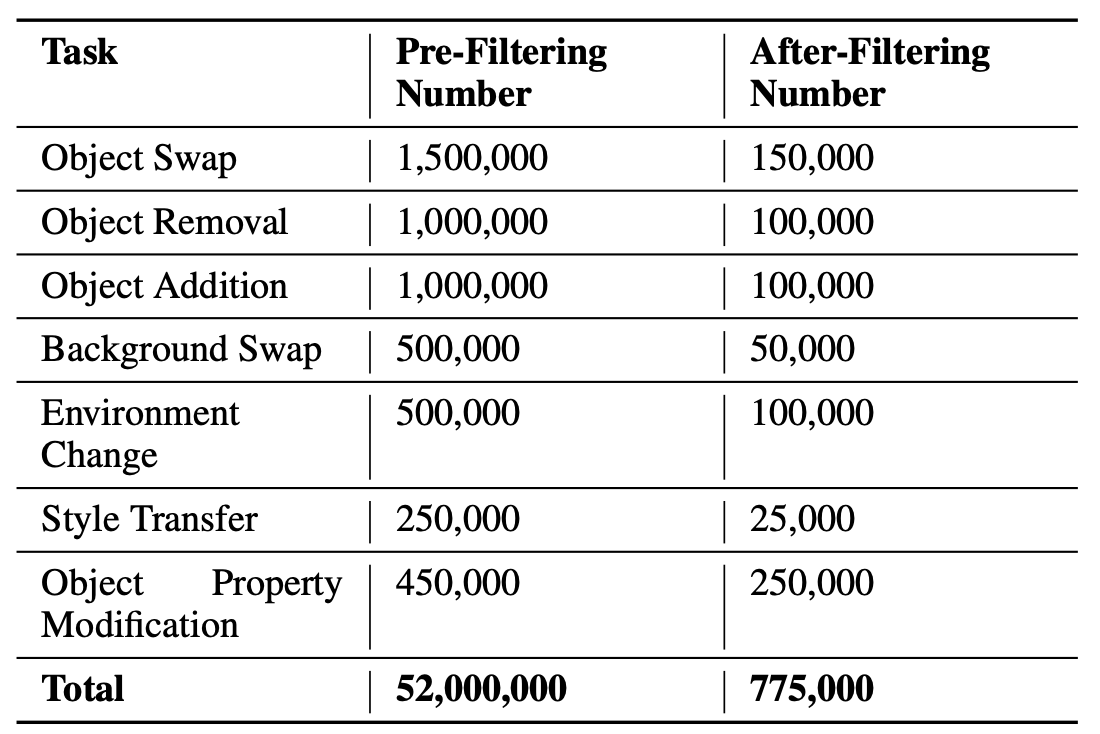
Evaluation Bench:从pexels和LAION-5B中手动共挑选出62张图像,这些图像中场景各异、物体数量也各异,然后对每张图像做以上7种编辑任务,最终共获得434个编辑结果。
其他细节:
- 以SD3 Medium为Backbone,该结构共包含24个DiT blocks并对每个block都添加一个EditNet layer
- 在共77.5万数据、8张H100卡上训练了2个epoch。
评估指标:
- 人工评估:
- Semantic Consistency(SC):编辑结果是否准确响应了编辑指令
- Perceptual Quality(PQ):对编辑结果进行打分
- 自动评估:使用多模态大模型(GPT4o and Gemini)询问上面两个同样的问题
- 人工评估:
OminiControl
《OminiControl: Minimal and Universal Control for Diffusion Transformer》
【论文】【代码】【HuggingFace】【数据集】
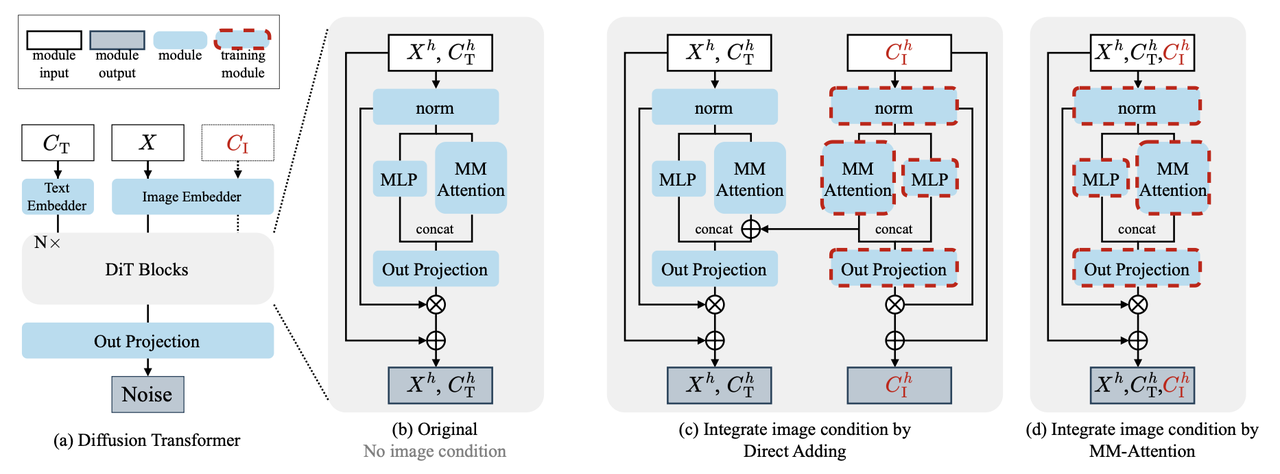
算法流程:
基于DiT框架(Flux-Dev)提出了一个高效且统一的image-conditioning生成框架,可以进行subject-driven生成和spatially-aligned任务生成(如depth、canny控制生成等强结构对齐),整个模型相比基模只需要0.1%的额外参数量。在数据集上提出了一个包含20万张的subject-consistent数据集
算法细节:
Image Condition Integration
本算法以DiT框架下的Flux-Dev为backbone,为了让原DiT模块支持image-condition生成,作者在其中的MM-Attention中拼接上condition-image的token,构成一个完整的token:
,然后以此作为完整token进行attention计算:
其中
为noisy image token, 为text tokens, 为condition image tokens Adaptive position embedding
condition image融入到DiT网络中需要仔细考虑其位置信息,以确保condition image和待生成图像之间的有效交互。此外为了同时支持类似ControlNet一样的spatially-aligned和类似IP-Adapter一样非spatially-aligned的生成。于是作者针对此设计了一个新的position embedding方法。
具体做法是:用VAE将512x512的图像encode到32x32大小的latent,然后在原RoPE基础上对2维的position进行偏移,如原本的position下标
都是在0~31范围, 现在偏移后 的范围仍然在031,而 的范围则在3264。 此外为了满足spatially aligned 任务,作者将condition image的position embedding设置成和原待生成图(noisy latent)的一样,但是这个收敛想比较偏移的position embedding会慢一点。
Condition strength factor
为了能灵活调整condition image在生成过程中的控制力度,作者针对attention设计了一个权重机制:
其中 是一个 大小的矩阵,其中M和N分别是text token和image token(有noisy image latent和condition image latent两个)的长度,该矩阵的形式如下: 这里是通过torch自带的F.scaled_dot_product_attention函数就能直接实现(但是源码中好像是bias矩阵的右上和左下那块也都设置成非0了??)
attention_mask = torch.zeros(query.shape[2], key.shape[2], device=query.device, dtype=query.dtype) condition_n = cond_query.shape[2] bias = torch.log(attn.c_factor[0]) attention_mask[-condition_n:, :-condition_n] = bias attention_mask[:-condition_n, -condition_n:] = bias hidden_states = F.scaled_dot_product_attention(query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask)📢复习:原本F.scaled_dot_product_attention接受attention_mask参数,在(attention_mask元素非bool型时)就是直接加到
后,再进行softmax,具体可以看其源码。 简单来说:该矩阵能保证控制力度只影响noisy image tokens和condition image tokens,而保留了各自与text token的attention关系,控制力度效果如下:

其他:
Subjects200K datasets:基于Flux搭建了一个新颖的数据收集流程,保证subject-consistent,共收集了20万整图像,类别包含服饰、家具、交通工具、动物等。

实验细节:
- 使用FLUX.1-dev做spatially aligned任务(如canny/depth控制生成),使用FLUX.1-schnell做subject-driven 任务
- 基于LoRA进行训练,rank=4(具体是在原mlp计算noisy latent的qkv时候加了个lora mlp,然后原mlp和lora mlp对noisy latent计算后相加得到noisy latent的新qkv,同样操作再对condition latent计算得到condition的qkv)
- batch_size=1,gradient accumulation步为8,在2张H100上训练,spatially aligned任务训练了5万步,subject-driven 任务训练了1.5万步
- 评估指标:使用FID、SSIM、MAN-IQA、MUSIQ 评估生成质量,使用CLIP Score评估semantic consistency。使用MSE评估控制生成。使用GPT-4o从5个维度(identity preservation、material quality、color fidelity、natural appearance、modification accuracy )评估subject-driven任务
- 应用:场景变换、虚拟试衣
UniReal
《UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics》
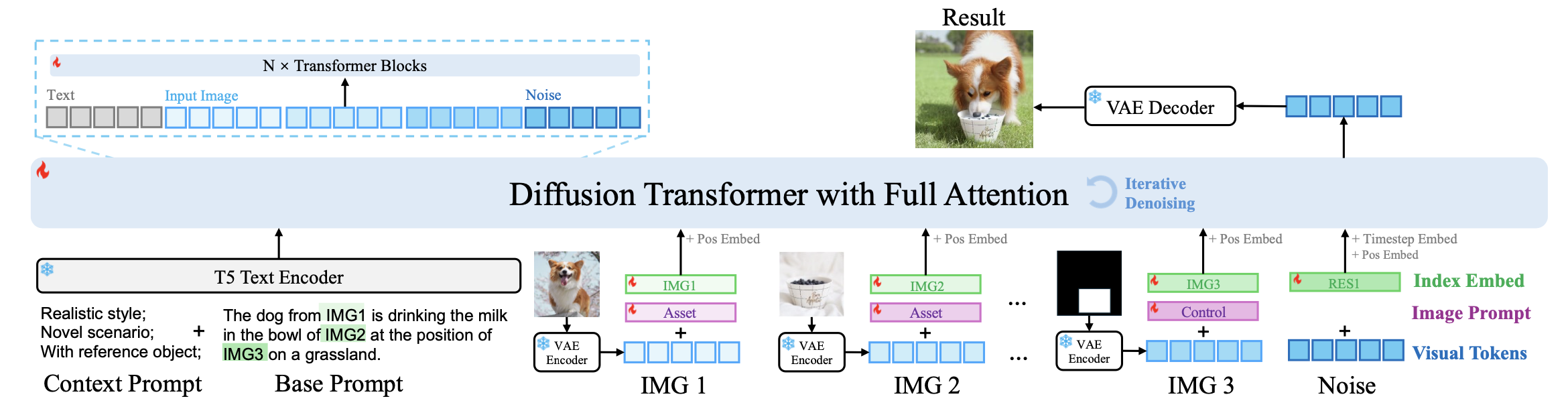
算法流程:受到视频生成模型的启发,本文提出了一种统一的方法,将图像级的任务视为不连续的视频帧生成。将不同数量的输入和输出图像视为帧,从而实现对图像generation、editing、customization、composition等任务的无缝支持。该算法从大规模的视频数据中学习真实世界变化,在处理阴影、反射、姿势变化和物体交互等高阶场景下展示了很好的效果。
算法细节:
网络结构:
整个算法以Diffusion Transformer为backbone,可以接受多个输入图像和输出多个结果(模仿视频生成,但是这里一般只会输出一个图像结果)。整个网络的运行过程如下:
图像Token收集:
用VAE对输入的若干个图像编码得到latent,此外因为这些图像对生成结果都起着不同的作用(如主体参考、位置控制等),所以作者专门设计了一种图像标识(Image Prompt)用于区分图像。该标识是一种learnable category embeddings ,然后添加到image token上。
作者将输入图像分为三个类别:a. 目标图像canvas:要编辑的图像,其中的内容倾向于不动;b.参考图像asset:指IP图像,包含要插入或保留的对象或视觉元素(pose可能会变但是id不变);c.布局或形状control :如mask/edge/depth之类的控制图像。
图文关联:
任务标识(Context Prompt):该算法是一个统一的图像生成方法,可以做编辑、ip保持等各种图像任务,为了消除各个任务之间的模糊边界,作者在常规的prompt之外还添加了一个Context Prompt用于标识本次生成要做的任务(如"realistic/synthetic data", "static/dynamic senario", "with reference object"等)
Index Embeddings:输入的每个图像在prompt中都有对应,使用类似"IMG1"、"IMG2"...之类的标识进行对应,并在image token后添加一个index embedding表明其在prompt中的对应关系。
对输出的图像(可能不止一个)也会有类似"RES1"、"RES2"...之类的进行对应
Token拼接:
将生成所需要的所有token直接在序列长度的维度上进行拼接,这些要拼接的token包括:
- Context Prompt和Base Prompt经过t5后的text embedding;
- 各个输入图像依次经过VAE、image prompt、Index Embedding后的image token再加上Position Embedding;
- 经过Index Embedding后的noisy image token,再加上Position Embedding和Timestep Embedding.
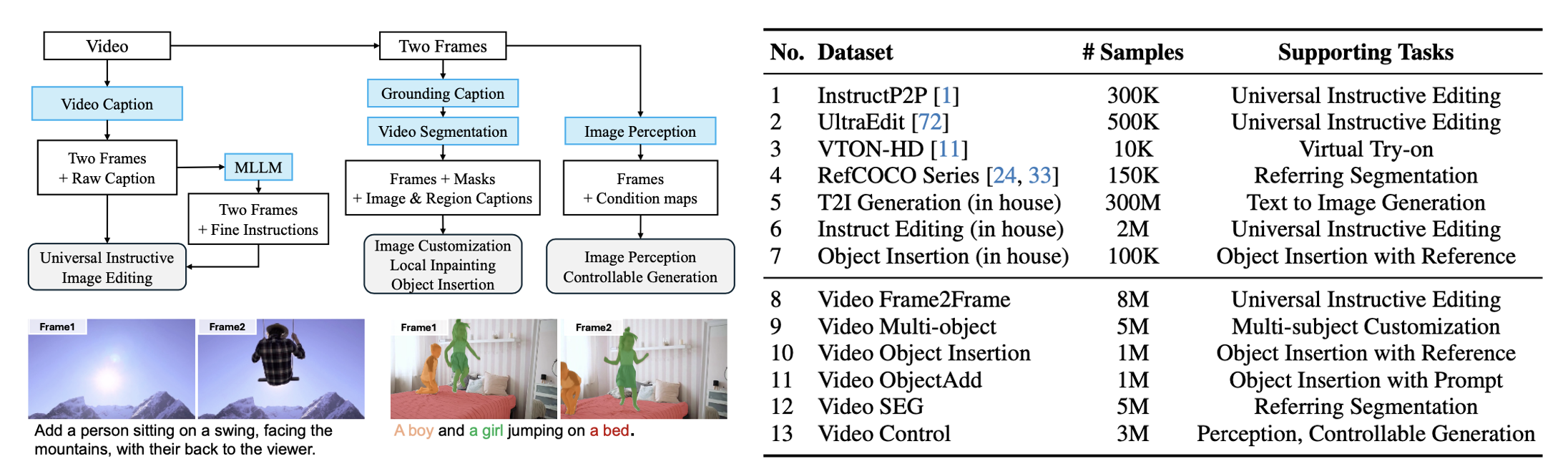
数据集构造:
从视频数据集出发,利用Caption模型、SAM模型现成的模型进行训练数据构造,因为论文中讲的感觉也不是很详细,这里也不做展开说了,整个大概流程和最终得到的数据量如下:
实验细节:
- transformer模型有5B大小,先在256x256分辨率的图像上预训练然后再在所有图像上全量训练(仍然是256分辨率),然后逐渐扩大分辨率到512和1024训练
- 使用flow match进行损失训练
其他:
局限:虽然该算法理论上支持任意数量的输入和输出图像,但随着图像数量超过五个,稳定性会降低,计算也会变得密集。通常,对于大多数应用程序,3-4个输入图像就足够了。
可支持的任务:

One Diffusion
《One Diffusion to Generate Them All》
【主页】【论文】【代码】【HuggingFace】
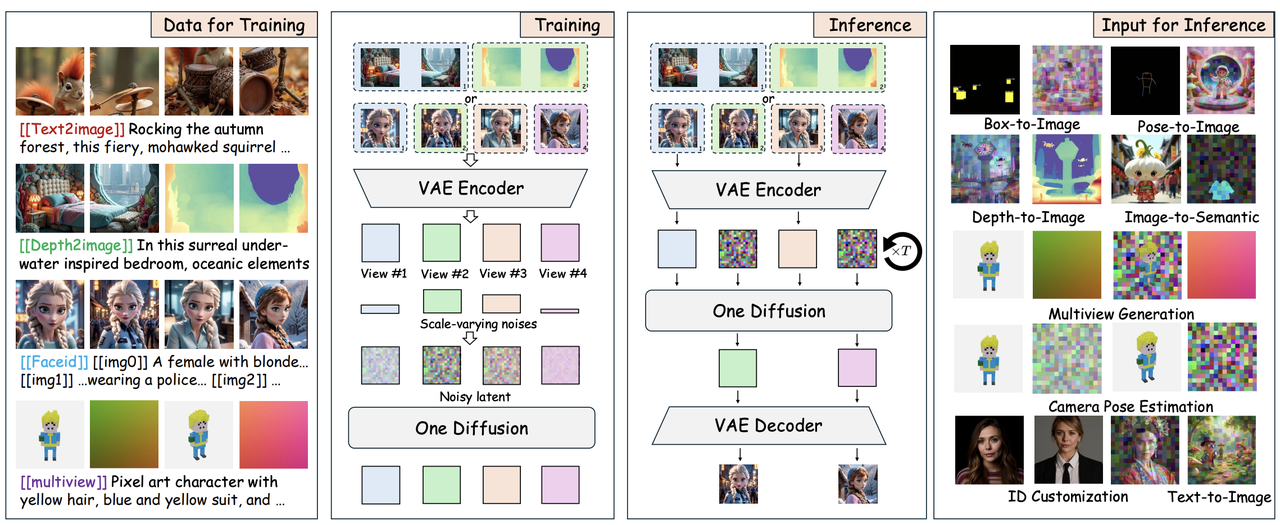
算法流程:提出了一个统一的图像生成和编辑框架,允许任意数量的条件输入,支持文生图、canny等条件生成、upscaling、语义分割检测、深度预测、ID生成、多视角生成等多个任务。同时针对各个任务也构造了一个数据集-One-Gen Datasets。算法结构将多个输入当作"View"在通道维度拼接后统一送到dit网络中。
算法细节:
算法训练(上图左半部份):
算法将若干控制条件和目标图像都称作"view"(不同任务有不同数量的views,比如T2I中有一个view,即noisy linput;如depth等条件控制或图生图有2个views;如多视角生成或ID生成有超过2个的views),支持任意views作为输入,并将条件图和target图构成一个整体,使用vae编码后得到latent
送入到DiT中,输出的也是 大小。 对每个"view"
给定一个服从lognorm分布的时间变量 和一个服从正态分布的噪声 ,以此进行扩散的前向过程: ,本算法使用Flow matching 计算损失,所以计算velocity field为 ,集成所有view的velocity得到 后得到本算法的joint flow-matching损失: 算法推理(上图右半部份):
算法支持生成任意数量的view(比如
),并以剩下的views(如 )作为条件去控制生成,具体做法是:将 初始化为高斯噪声,在每个timestep去预测time- dependent vector field: ,将条件view的时间变量设置为 ,将带生成图像的时间变量设置为 : 数据集:
构建了一个支持该算法的多任务训练数据-One-Gen Datasets ,包括:
Text-to-Image数据集:包括PixelProse、JourneyDB的几个开源数据集和内部的10M张数据集(使用LLaVA-NeXT和Molmo打标)。
Image-to-Image数据集:
- 对于deblurring、inpainting、canny条件生成、upscaling等任务:使用对应预处理器得到对应的pair对,共获得1M组数据。
对其他复杂的任务,先使用Midjourney, Stable Diffusion、Flux-dev等模型生成图像,然后根据任务不同再做对应处理:
对于Semantic Map and Detection:用LLaVA-NeXT 提取实体,再用SAM粉个实体并得到bounding boxes,最终构造350K的三元组数据集【semantic map, bounding box, 原图】
对于Depth Map:使用DepthAnything-v2对生成和真实的数据集进行打标,得到500K组数据
对于Human Poses:使用ViTPose进行pose预测
ID Customization数据集:通过公开可用的图像收集了游戏和电影中的名人和角色。筛选确保每个人物至少有四张图,最终得到大约 60K 个任务共 1.3M张图片,再使用 LLaVA-NeXT 打标
Multiview Generation数据集:使用DL3DV-10K、Objaverse和CO3D进行构造
实验细节:
可支持的任务:
在进行每个生成任务时,要指定对应的task label
- Text-to-Image(1个view):使用
[[text2image]] - Image-to-Image(2个view):比如对图像进行语义分割出嘴巴位置,并使用黄色mask表示,task
label表示为
"[[semantic2image]] <#FFFF00 yellow mask: mouse> photo of a ... " - ID Customization
(2~4个views):对每个输入的id图像使用
[[imgX]]表示,task label使用[[faceid]] - Multiview Generation (4-12 views):使用ray
embeddings代表每个camera pose,task
label使用
[[multiview]]

- Text-to-Image(1个view):使用
DreamOmni
《DreamOmni: Unified Image Generation and Editing》
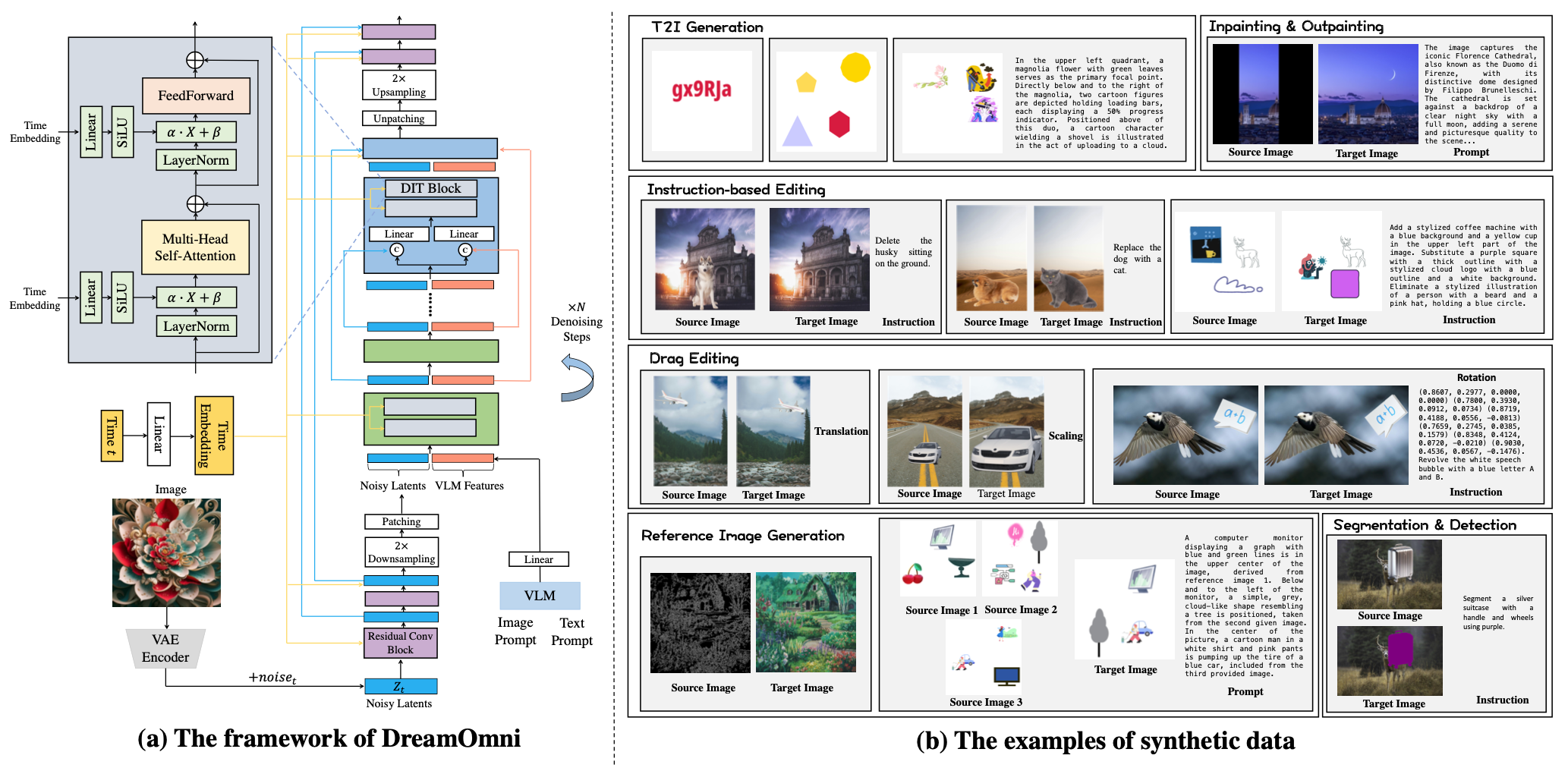
算法流程:作者提出了一个统一的图像生成和编辑框架,引入VLM特征提升生成效果,其余无过多的框架创新。此外还提出了一个使用贴纸类数据进行快速且大量构造数据的pipeline。
算法细节:
网络架构:
- 不同于以往T2I模型使用T5或者CLIP提取text特征,本算法则将VLM特征(从image prompt和text prompt提取)与noisy latent特征(图像经过vae-encoder后加噪得到)连接起来,并将其输入到DIT Block中。
- 作者发现在T2I模型下,DiT结构之所以优于UNet,是因为DiT将大部分计算分配给2×降采样的潜在值,而Unet将更大比例的计算分配给4×降采样潜在值。所以这里作者将noisy latent2倍下采样后进行patch化得到图像token
- 此外作者还观察到:在UNet框架中使用长连接可以显著加速模型的训练收敛,而不会影响性能。所以算法沿着通道维度连接早期和晚期特征(即结构图中的residual conv block),并应用线性层来组合这两个特征
数据构造:
作者发现有效编辑的关键在于帮助模型理解编辑操作的含义,而不是学习特定的概念,因为该能力在T2I训练中已经具备了,所以基于此发现作者提出了一个基于贴纸组合的高效数据制作pipeline。数据类型具体可以分为6大类:
用于提升模型基本的T2I响应准确性:在画布上随机排列不同数量的贴纸、文本和几何形状,并根据它们的精确坐标获得它们的数量、位置、关系和颜色的精确描述。
用于instruction-based editing:包括物体的添加、删除、替换
用于drag editing:物体的平移、缩放、旋转。使用统一的格式【x,y,dx,dy】作为提示输入来表示这次drag中的点,其中x和y表示源图像中待拖动点的坐标,dx和dy表示平移向量。最终通过将这些坐标除以图像的宽度或高度来对其进行归一化。
这样的话,在推理的时候prompt岂不是要写一堆精确的数字?
用于inpainting and outpainting :对图像随机mask,在训练过程中,除了将masked图像及其相应的mask输入到VLM进行编码外,还以50%的概率包含图像caption
用于reference image generation:又包括subject-driven generation和image-conditioned generation(类似controlnet)
用于Segmentation & detection :随机选择一个背景图像和前景图像进行组合,用前景的mask构造target图。
最终数据量:T2I数据共125M,包括LAION 数据 (103M) 和利用上述方法构造的22M数据,这些图像使用InternVL2 打标;其他5个任务分别有12M的数据
实验细节:
- 单图像输入(比如指令编辑和inpainting):图像要送到vae-encoder和vlm同时提取特征。虽然也可以只输入到VLM,但是加上vae特征能够保留背景的一些细节上
- 多图像输入(比如上图右侧最后一行中间,用3张引导图生成结果图):所有输入图像连同prompt都送到VLM中,得到一个整体的embedding(尺寸BxLxC),此时vae-encoder不接受输入了,直接将vlm特征拼接纯噪声送到dit中。
- 模型参数:
使用FLUX-schnell的VAE,使用2.5B参数的DiT作为backbone,使用7B的Qwen2-VL提取VLM特征
使用Rectified Flow计算损失
在64张A100训练,并类似SDXL使用了多bucket尺寸训练
分3个阶段训练:
256分辨率上,batch_size=1024,学习率1e−4,训练377K步
512分辨率上,batch_size=1024,学习率5e−5,训练189K步
1024分辨率上,batch_size=256 ,学习率2e−5,训练140K步,数据使用12M的高质量T2I数据和其他5类数据各1M
- 可支持的任务:

总结
大一统图像模型以简洁的架构完成各项图像任务,抛弃了专门设计的各种插件。同时能够利用到各个任务各自的数据,形成一个“大一统”数据集进行训练,各种图像任务之间相互促进增强保证最终大一统模型的完整性和优越性。
在模型架构上,各种大一统模型的设计也是趋向于统一:使用强大的基于transformer机制构建backbone,并对所有要输入的图像直接在各种层面进行拼接(如token序列上),这种“简单粗暴”但是有效的方式也保证了模型设计的简洁性。