图像编辑是Diffusion算法中一个重要的方向,其旨在对生成或者真实的图像进行操作以得到与原图相似却某在某些方面(如背景、主体、风格等)存在不同的效果,具体应用其包含换主体、换背景、主体移动等各种方向。

Prompt-to-Prompt
《Prompt-to-Prompt Image Editing with Cross-Attention Control》
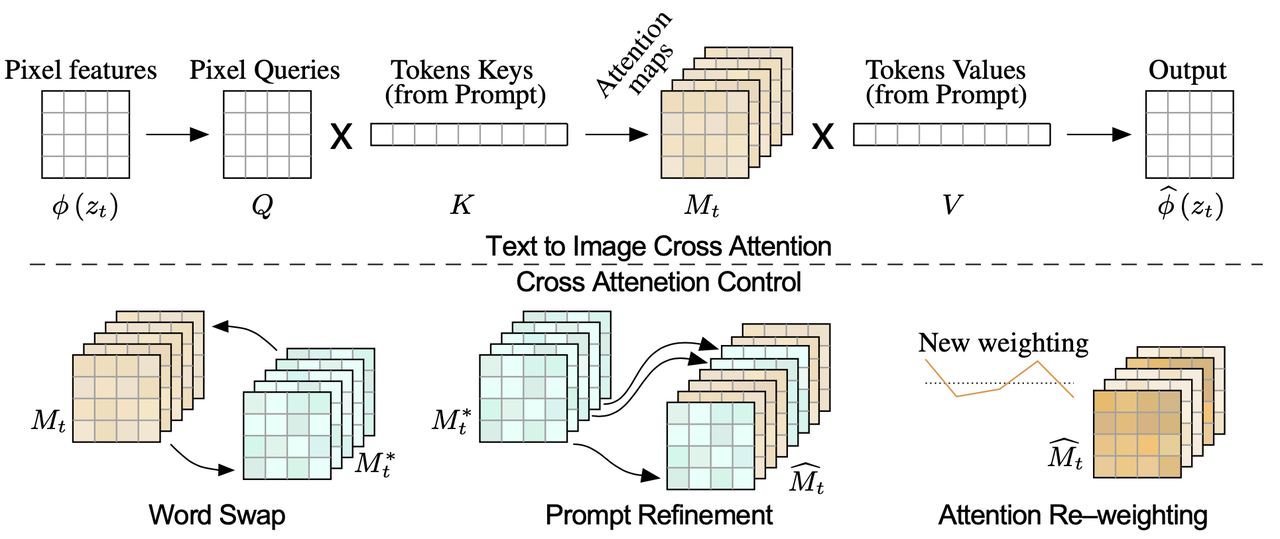
算法流程:提出一个training-free的图像编辑算法,无需任何其他数据和优化过程。作者观察到cross-attention层是控制图像空间layout与prompt中每个单词之间关系的关键元素,通过只修改prompt的方式就能完成精准的图像编辑,包括主体替换、外表修改、环境修改等
之前算法回顾:prompt中微小的变动都会导致生成结果发生很大的变化,所以之前的图像编辑任务通常会显式指定一个mask,以保证把编辑限制某个区域,但是这种方式会有点繁重。或者通过固定随机种子尝试保持基本的layout但是效果也很一般。
算法细节:
任务描述:使用prompt
和随机种子 经过文生图生成图像 ,该图像编辑的目标则是在仅修改prompt得到新prompt 后,送到文生图模型中得到编辑后的图像 ,保证与原图像有相似的layout,并且又符合新prompt的描述。 Cross-attention回顾:原文生图模型通过cross-attention的方式将prompt的信息融入到网络中,具体首先是图像特征作为Q,prompt embedding作为K计算attention map:
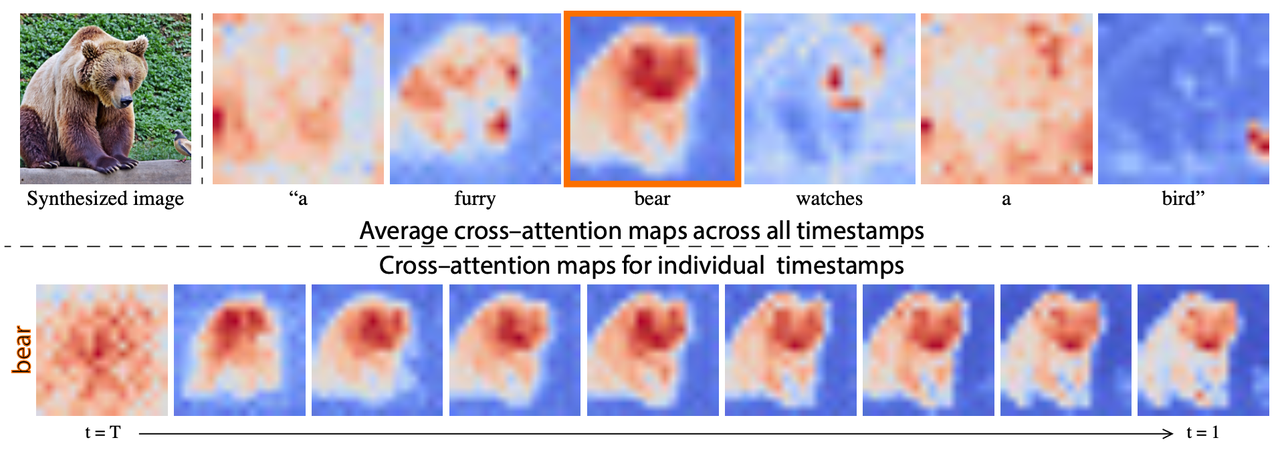
,其中M的每个元素 表示prompt embedding中第j个token对于image embedding中第i个像素块的权重,然后使用这个权重对V进行加权求和得到最终的attention map。下面的图表明了: prompt中token与图像的区域具有强相关性;
denoise的前期决定了图像的整体布局。
算法伪代码:该算法主要是通过操控diffusion过程中的cross-attention进行图像编辑,整个过程如下:

算法包括两个分支:
表示以p为prompt、在随机种子s下、第t步的原图denoise过程,返回noisy latent和attention map; 表示以 为新prompt、同样在随机种子s下、第t步的编辑图denoise过程; 表示该算法核心编辑过程的广义表达形式【后面会根据每个垂类编辑任务进行细分】:接受原图和编辑图在第t步的attention map并进行一些操作后得到新的attention map, 表示在编辑图分支过程中使用新的attention map替换原本的attention map。 如果只想修改图像中的局部区域(比如原prompt
中的主体 换成新prompt 中的 )而保留剩余的大部分区域不发生变化(比如背景),该算法则会在Diffusion过程中自动计算一个粗略的mask来限制编辑区域,具体计算过程如下: - 在denoise进行第t步时,计算原图分支在第t步之前(即T~t步时)单词
的attention map的平均值 - 同理计算编辑图分支在第t步之前(即T~t步时)单词
的attention map的平均值 - 对上面两个平均attention map分别二值化得到
和 ,该算法二值化以0.3为阈值。 - 因为局部编辑的范围会同时包含原图主体和编辑图主体范围,所以取上述二值化结果的并集作为粗略的编辑区域
- 对两个分支的结果进行插值
作为编辑分支的新noisy latent。
- 在denoise进行第t步时,计算原图分支在第t步之前(即T~t步时)单词
具体编辑任务:
单词替换(Word Swap ): 想要单独修改图中的某些内容,如"a big bicycle"变成"a big car",为了防止前后主体差别过大而导致下过下降,作者采用分阶段的attention替换,具体公式表达为:
即在决定图像主体布局的denoise前期使用原图的attention map 以保留原图布局,而在denoise后期使用编辑分支的新Attention map 以精细编辑图的结果。 Prompt润色(Prompt Refinement):想要对prompt中某些内容进行补充,如"a castle"变成"children drawing of a castle"。为了实现该效果,作者首先定义了一个Alignment function:
表示编辑prompt 中第j个token对应原prompt 中的token编号。然后编辑公式如下: (回顾下:attention map中的下标i表示图像token,下标j表示文本token。) Attention重新权重(Attention Re–weighting):该情况下不改变prompt,但是希望prompt中某些词的效果加重/减轻,比如"a fluffy ball"中的毛绒效果减轻/加重,那么直接调节该单词对应的attention值即可,公式如下:
算法应用:
- Text-Only Localized Editing:只通过文本可自动定位图像中要修改的内容范围并进行准确的主体置换、外表更换等,其他内容则保留
- Global editing:保留原图整体布局的情况下进行全局编辑,比如修改环境、风格
- Fader Control using Attention Re-weighting:加重/减轻图像中某些单词的影响效果,比如树叶数量、夜空亮度、
- Real Image Editing:对真实图像进行DDIM Inversion得到initial noise latent后可进行真实图像的编辑
算法局限性:
- 受限于Inversion的重构精度,可能存在重构图像扭曲失真的情况
- 受限于attention map的分辨率,可能无法做到某些很精细的编辑效果
InstructPix2Pix
《InstructPix2Pix: Learning to Follow Image Editing Instructions》
【主页】【论文】【代码】【HuggingFace】

算法流程:该方法提出了一个指令式的图像编辑方法,通过给定图片和编辑指令(即告诉模型要对图像做怎样的编辑)可以完成物体替换、外表改变等图像编辑方法。该方法使用GPT3和SD并配合Prompt2Prompt算法进行pair训练数据的收集。
其中指令 Prompt只需要描述需要编辑的地方就行,而无需描述整个编辑后图像(比如物体替换时只需要告诉模型把什么换成什么就行,而不需要描述背景、风格之类的),这种指令更加精简和准确。
算法细节:
数据构造:
产生pair对的captions:作者对GPT3进行finetune,使其能够接受一个input caption并输出一个指令式caption和output caption。比如输入一个“photograph of a girl riding a horse”,模型则输出指令caption-“have her ride a dragon” 和编辑caption-“photograph of a girl riding a dragon”。作者基于LAION-Aesthetics V2 6.5+数据集收集700个prompt并手动改写得到对应的指令caption和编辑 caption,并使用这700组数据finetune了GPT-3 Davinci模型,最终构造了454445组【输入 captions,编辑指令,输出caption】数据。训练数据集和构造的数据集示意如下:
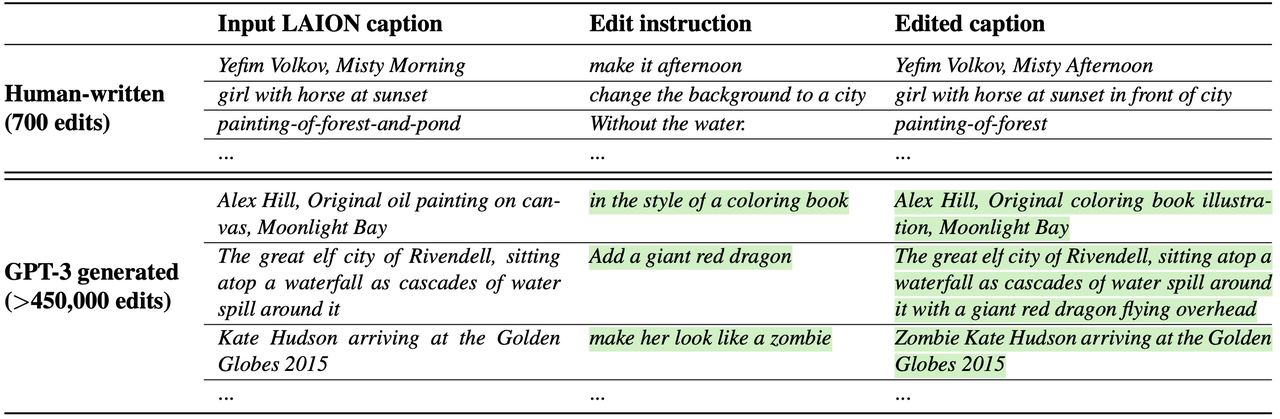
【上图绿色底表明是生成的结果】
从成对的caption构造成对的图像:上述已经得到了成对的caption【即“输入 captions和输出caption”】用于描述编辑前后的图像,这两个caption描述基本相似的内容但是在主体、风格等上可能会有细小的差别。如果直接使用文生图模型得到对应的图像,即便prompt中很小的差别也会导致生成结果完全没有任何相关性,所以作者使用了Prompt2Prompt技术保证两张图像的一致性。同时为了保证不同幅度都具有比较好的编辑效果(比如移动物体、改变形状等大幅度的编辑),作者在Prompt2Prompt过程通过操控共享attention权重的denoising步数来控制生成结果的相似性。具体地:对每组caption采用不同程度的attention共享比例生成100组pair图像,然后使用CLIP相关的指标,在CLIP空间衡量两个图像之间的变化与两个图像caption之间变化的一致性,通过该指标过滤一波图像提升最终pair图像的质量和一致性。
回顾:prompt2prompt接受一个图像和其对应的caption,然后和一个编辑caption ,该caption和图像的caption基本接近,然后通过training-free 的方式,通过操控cross-attention保证模型输出的图像和满足编辑caption又和原图接近。
具体在生成过程中有两个分支:原图重构分支和目标图编辑分支,两个分支在前期共享attention权重,并在某个denoise 步骤时开始分化使用不同的attention权重。
模型训练:
预训练:从SD模型为pretrain,但是在U-Net的第一个卷积层添加额外的channel以拼接noisy latent
和待编辑图像的latent ,额外添加的卷积权重设置为0,其他权重均从原SD模型为初始化。整个训练的损失函数如下: 其中 是对编辑结果进行encode和加噪后的noisy latent, 是原始待编辑图像的encode结果, 是edit instruction(注意这里用的是编辑指令文本,而非编辑结果图的caption) 双条件的Classifier-free Guidance for Two Conditionings:相比原CFG只有一个prompt条件,本算法多了一个图像条件,即待编辑图像的latent-
,于是作者设计了一个双条件的CFG: 在训练过程中, 和 各有5%的概率置空,同时还有5%的概率两者同时置空。
训练和推理细节:
- 以SD1.5的EMA权重作为pretrain并进行finetune,额外添加的权重使用权0初始化
- 在8张40G的A100上训练了1万步,约25.5小时,batch_size=1024,学习率1e-4且未使用learning rate warm up
- 图像分辨率为256x256,随机对图像水平翻转并resize到256~288大小后,再crop到256大小
- 虽然在256分辨率上训练,但是仍然可以在denoise_step=100的时候生成512大小的图像
- 在A100上编辑一张图像需要9秒钟
算法应用:
- 主体替换(replacing objects)
- 改变季节和天气(changing seasons and weather)
- 换背景(replacing backgrounds)
- 修改材质属性(modifying material at- tributes)
- 艺术风格转换(converting artistic medium)
Masactrl
《Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing》
【主页】【论文】【代码】【HuggingFace】
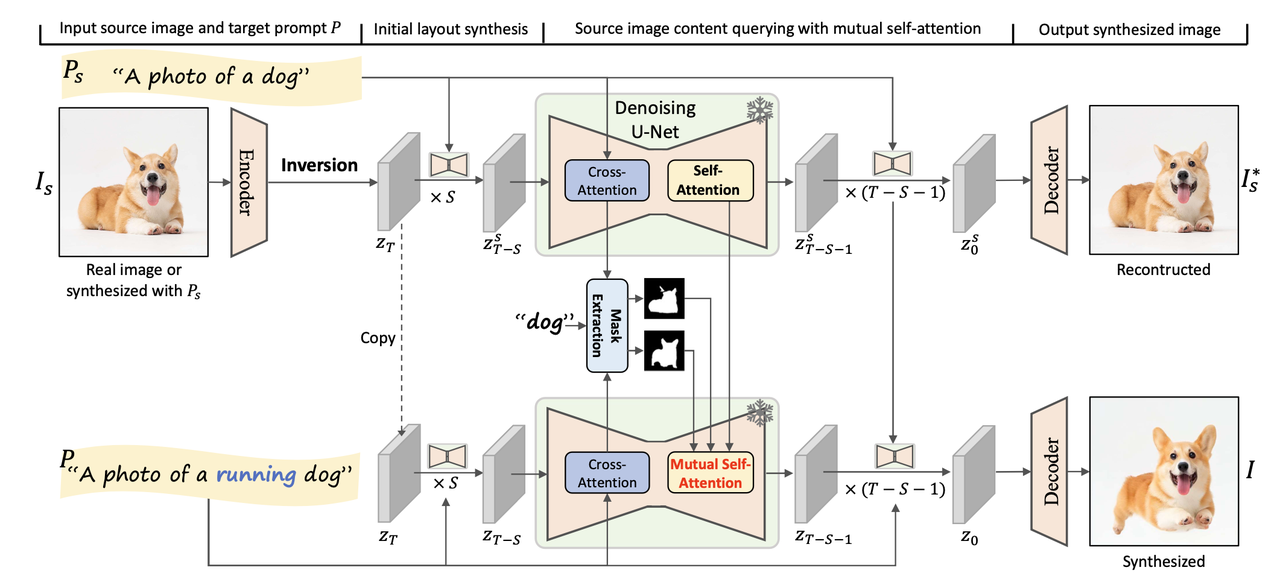
算法流程:
- 该方法是一个Tuning-Free完全无需训练的图像编辑算法,总体思路和 prompt2prompt比较接近,且同样只需要prompt且无需额外指定Mask就能进行图像编辑。其会在Diffuison去噪过程中自动找到原图要编辑的地方进行修改(比如笑脸变哭脸),并且能保证原图的identity的一致性。
- 提出了Mutual self-attention,即提取原图加噪后的latent在denoise过程中的attention特征的Key和Value,在配合编辑prompt进行Denoise时,使用其Key和Value来指导编辑过程。
算法细节:
问题具体描述:
- 输入:一张待编辑图像
、该图像的描述语句 、在 的基础上进行修改得到目标prompt - 输出:一张编辑后的图像
- 要求:编辑图像
和 具有相同的主体特征(比如纹理、identity 等),且又符合编辑prompt 的描述 - 举例:一张坐着的狗狗的照片、原
="A photo of a dog"、目标 ="A photo of a running dog",然后输出一只奔跑的狗狗,而且该狗狗的颜色、纹理、类别等特征都和原照片一致
- 输入:一张待编辑图像
为什么不用Mask就能找到要编辑的区域?
- 去噪的前期决定了图像的整体布局
- self-attention的query特征在语义上具有相似性,算法可以自动从另一个特征中进行query【也是本文的重点】
Mutual self-attention在denoise的过程中使用原图的attention特征进行引导,具体地:在合适的Denoise步数和合适的Unet层位置,将编辑前图像特征的Key和Value拉过来,替换编辑后latent在denoise过程中self-attention的Key和Value,让atttention机制自己去找到合适的原图特征作为参考进行编辑。
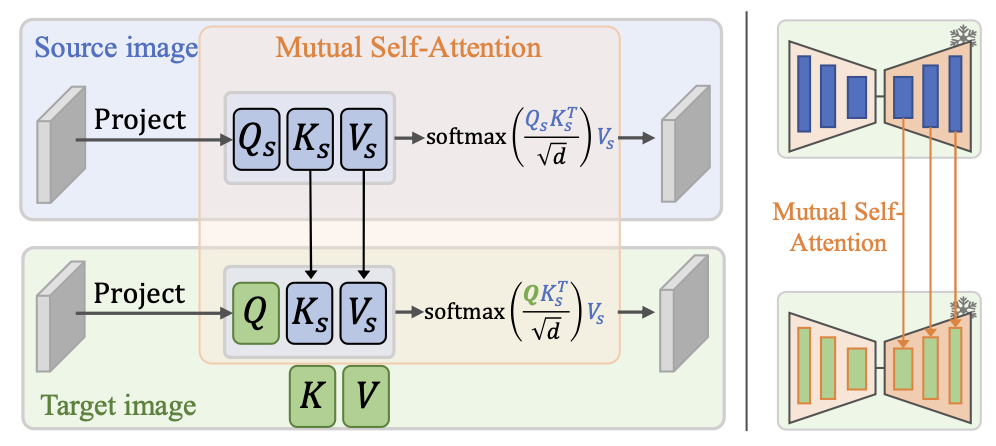 需要注意的是,并非在所有time
step、所有layer的self-attention都执行K和V的替换,因为去噪前期决定了图像的整体布局,此时结果图的布局信息混乱还没完全形成,如果过早的替换原图的K和V会导致信息混乱【即模型不知道到底是按照原图进行编辑还是按照prompt进行编辑?】,所以仅仅在后半部分的denoise过程且只替换UNet-Decoder中的self-attention。
需要注意的是,并非在所有time
step、所有layer的self-attention都执行K和V的替换,因为去噪前期决定了图像的整体布局,此时结果图的布局信息混乱还没完全形成,如果过早的替换原图的K和V会导致信息混乱【即模型不知道到底是按照原图进行编辑还是按照prompt进行编辑?】,所以仅仅在后半部分的denoise过程且只替换UNet-Decoder中的self-attention。论文原话:
Therefore, we propose to control the mutual self- attention *only in the decoder part of the U-Net after several denoising steps.*具体的算法过程如下:

Mask-Guided Mutual Self-Attention
为了避免在背景和前景有相似的纹理特征的情况下,mutual self-attention在query特征出现“混淆”。作者又改进得到了Mask-Guided Mutual Self-Attention,即通过attention map来自动计算mask,以显式地区分前景和背景,保证前景/背景只会从原本的前景/背景区域进行query。【注意该mask并非是用户输入的,而是在Diffusion过程中自动生成的。】具体过程如下:
在前向过程中计算对应于原prompt
和目标prompt 的UNet的cross-attention map 对所有heads中出来的attention map计算平均,最终得到
大小的attention map 该attention map与每个token相关,如下图所示:越亮表示越相关。
分别得到原图和目标图中与前景相关的mask:
和 通过以下公式计算最终的Attention map

实验细节:
- 使用SD1.4作为基模,同时也验证了在Anything-V4 模型上的有效性。
- 该算法可配合ControlNet或T2I-Adapter等插件同时使用,这时候不仅要提供编辑前后的prompt,也要提供编辑前后的控制图(比如线稿、depth等)。
- DDIM去燥步数为50,CFG=7.5
- 从第4步后,第10层attention之后开始attention特征替换
- 使用其在线推理链接测试,在A10上差不多要40多秒。
- 推理时候:
- 真实图片的noisy diffusion latent通过DDIM Inversion而来,且此时原始prompt置空
- 而通过噪声生成的图片则直接有noisy diffusion latent。
MimicBrush
《MimicBrush: Zero-shot Image Editing with Reference Imitation》
【主页】【论文】【代码】【HuggingFace】
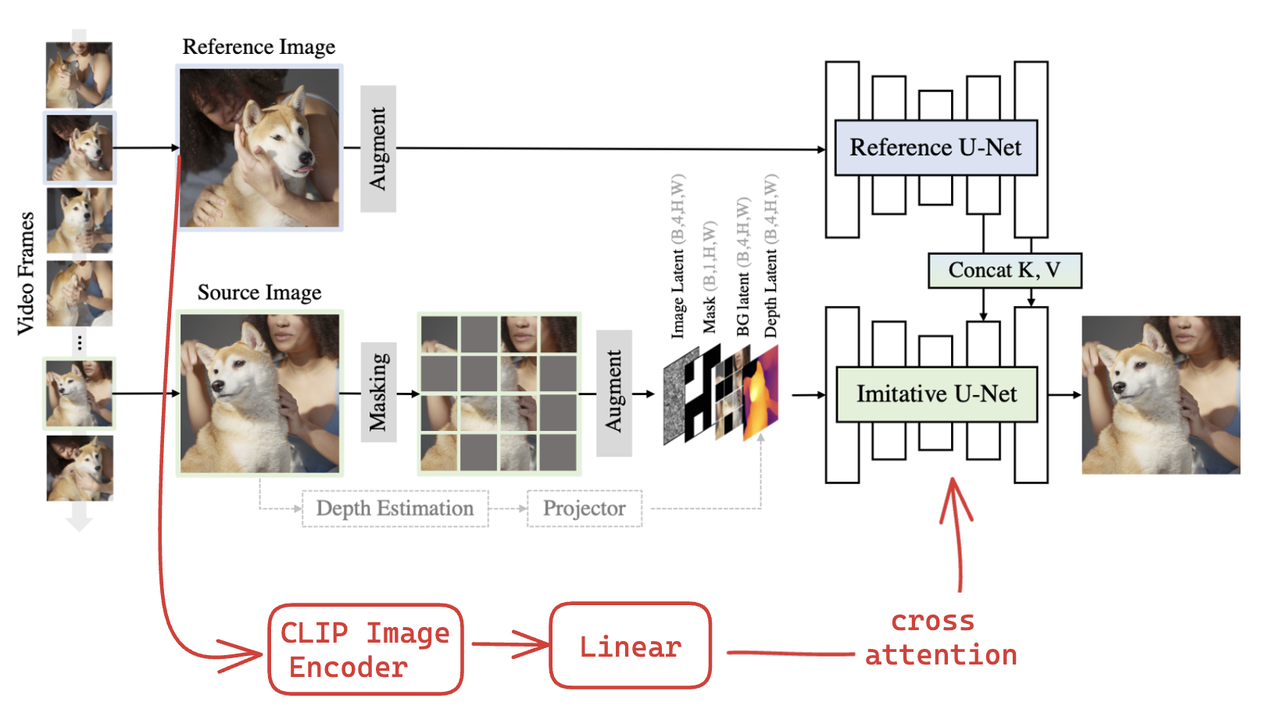
算法流程:该算法提出了一种基于参考图对原图进行Inpainting的方法,参考图相比较prompt能够提供更加丰富且难以精确描述的信息,此外该算法不需要额外指定具体从参考图哪个部分进行引导,网络会自动找到与原图中指定修复区域具有相同语义的部分(比如同是鞋底或头发等)【有点像MasaCtrl】进行参考生成。
解决的痛点:目前的Inpainting方法多是以下两种方法控制生成内容:
通过prompt:该方法对于诸如风格、纹理等难以精确描述,生成结果肯定就会与预期有偏差【下图a】
通过参考图+参考mask:用户额外指定参考图中的位置(比如用参考图的头发去控制生成原图头发)【下图b】
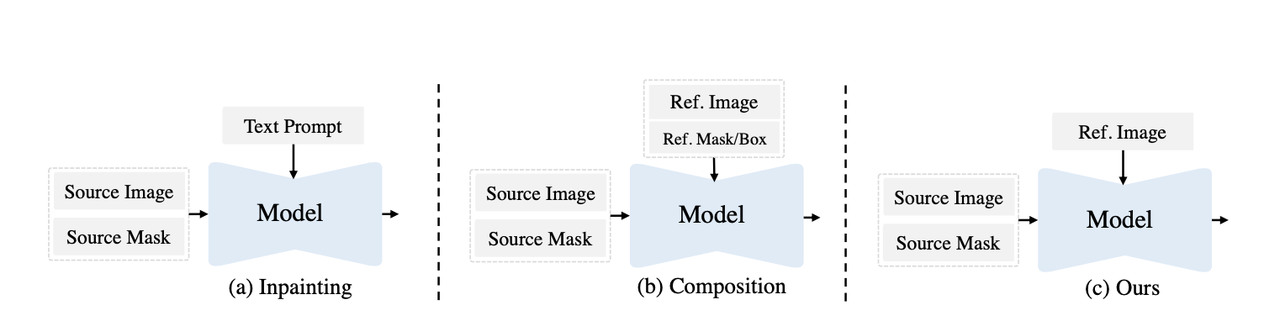
为了解决上述两种方法的痛点,该算法提出了如上图c所示的方法:一种只需要提供参考图而无需额外mask的情况下就能对原图中指定位置mask区域进行inpainting,该算法会自动找到在参考图中与原图mask区域相关的部分进行参考。
算法细节:
该算法的模型结构包含两个UNet(Imitative UNet和Reference U-Net)和一个深度估计模型:
Imitative UNet :
输入: 从SD1.5的9通道Inpainting模型进行初始化,在此基础额外添加了一个4通道的depth map共13个通道的特征作为输入UNet的输入。该depth map从unmasked的原图提取,主要用来提供shape信息,但是在推理过程中该depth可以不提供。
替换成ImageEmbedding:原始SD模型接受CLIP的text embedding送到corss-attention中,本算法会替换成CLIP的Image embedding,通过一个Linear层注入UNet中(有点类似IP-Adapter和AnyDoor)。【原算法pipline为了简洁性并未体现这一点,我补充上去了】
在训练过程中,该Imitative UNet和Image embedding的Linear层都是可学习的。
Reference U-Net:
Depth model:
使用Depth Anything提取unmasked原图的深度信息,用于提供shape信息。在冻住该模型的情况下,额外添加了一个trainable projector 将3通道的depth转成4通道作为imitative U-Net输入的一部分。在训练过程中,50%的概率丢弃depth信息(设置为纯0),保证在推理阶段该depth作为一个输入可选项。
实验细节:
数据集:
使用视频数据集作为训练集合,因为两个视频帧之间具有很多相似的属性(比如风格、人物ID等)。此外会使用SSIM去除相似度过大或者过小的frame对,保证语义相似性和视觉多样性。
使用color jitter、rotation、resizing、flipping等进行数据增强,提升视觉多样性。
使用SIFT match技术找到原图和参考图中语义对应的区域,并重点对这些区域进行mask。
论文的核心任务是使用在编辑原图某些区域时,使用参考图中具有相同语义的区域j(比如都是鞋底、都是头发等),所以这要求我们在对原图mask操作的时候不能随机,因为如果随机到参考图上没有的语义区域(比如想修改原图的帽子,但是参考图中人物根本不带帽子),那么参考可能就无意义。
实验参数:
- 图像分辨率 512x512
- 8卡A100,batch_size=64
- 在mask过程中,75%概率mask掉经过SIFT匹配的区域,50%概率mask掉其他区域
- 使用Reference UNet作为Classifier-free guidance控制,并且10%的概率丢弃,cfg=5。
BrushNet
《BrushNet: A Plug-and-Play Image Inpainting Model with Decomposed Dual-Branch Diffusion》
【主页】【论文】【代码】【HuggingFace】
文章先对之前常见的几种Inpainting模型进行了比较详细的分析
方案名称 方案细节 输入(图示如下) 
优势+劣势 代表方案 Sampling strategy modification 使用一个预训练好的diffusion模型,在去噪的过程中对masked区域重采样,而且固定住unmasked的区域。其实就是一个对 和 不断插值的过程: 和预训练好的Diffusion模型同样输入(通常是UNet直接接收4通道noisy latent) 该方法无需训练任何参数,即插即用。
效果很一般,很容易出现前后景不协调情况BLD、RePaint、Latentpaint Dedicated inpainting models 对预训练模型进行修改和finetune,比如添加额外的通道来支持image和mask 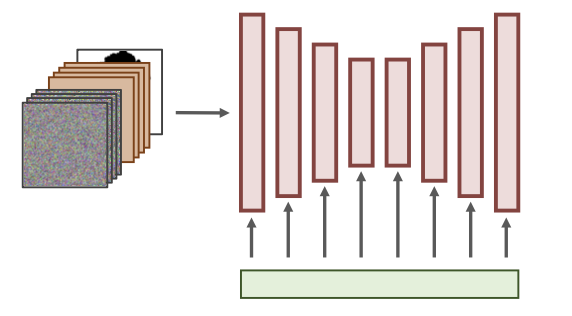 UNet接收noisy latent(4通道), masked
image latent(4通道), mask(1通道)
UNet接收noisy latent(4通道), masked
image latent(4通道), mask(1通道)效果相比上述方案有提升无法快速有效迁移到其他预训练模型中 SD-Inpainting 、
HD-Painter 、
PowerPaint
SmartBrushControlNet-Based inpainting 额外添加一个可训练的ControlNet Encoder,冻住原本的基座模型的权重 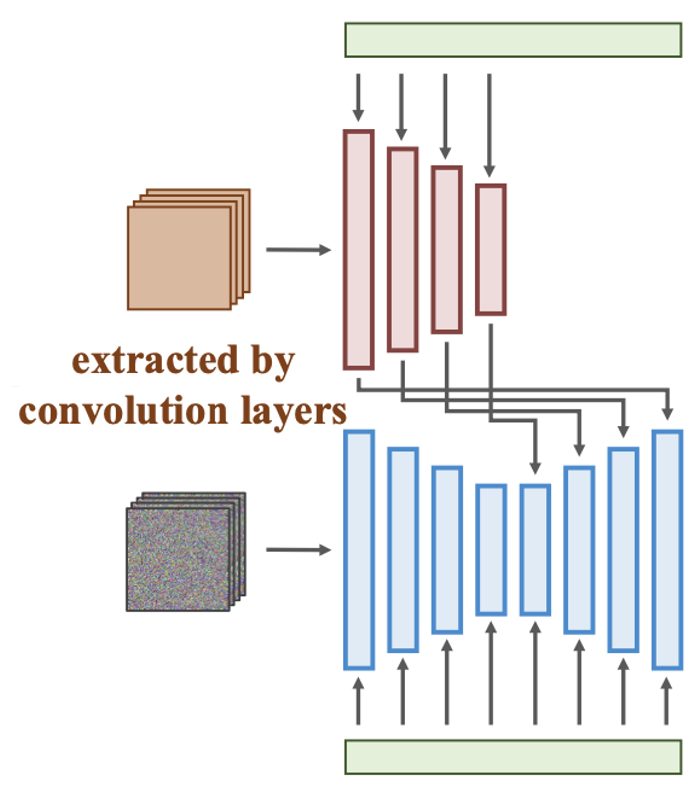 Unet接收noisy
latent,ControlNet接收Masked latent
Unet接收noisy
latent,ControlNet接收Masked latent额外训练插件,即插即用,但是原ControlNet并非转为Inpainting设计,缺乏对Masked Image的感知能力,导致最终效果也比较一般。 ControlNet-Inpainting
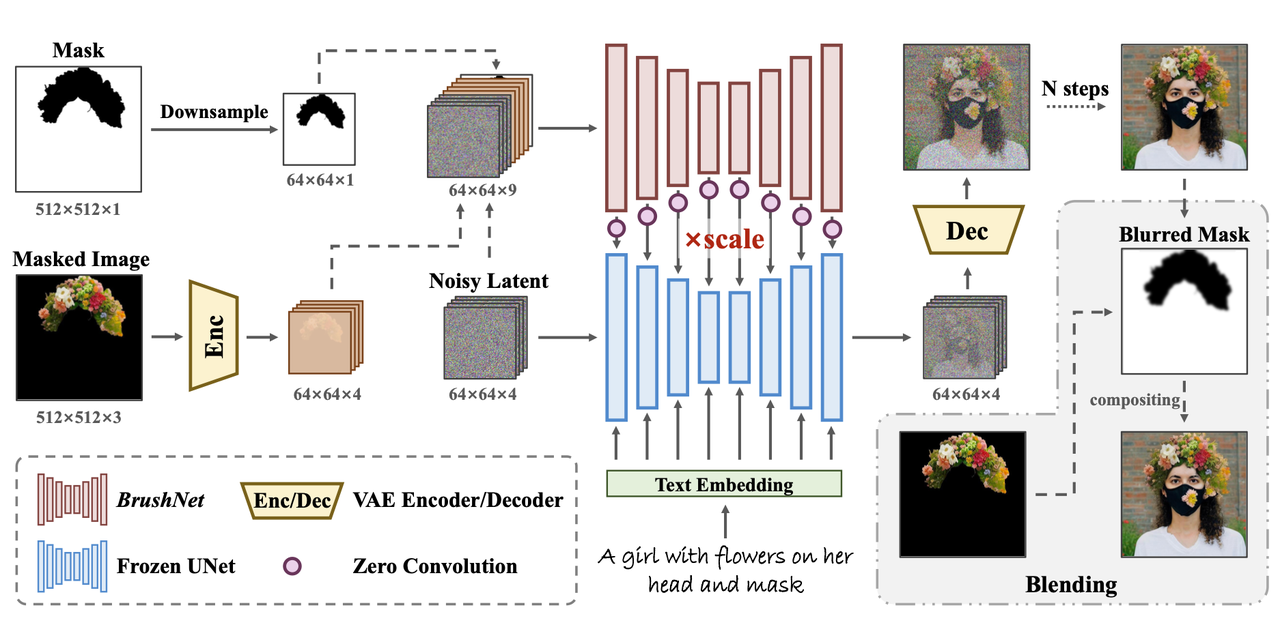
算法流程:如上图流程所示,本算法通过实验对比并验证了之前几种Inpainting方法效果都存在不及预期的地方,为此专门设计了一个双分支的网络结构(BrushNet)用于提升Inpainting效果。该方法冻住原基座模型的权重,将额外的输入(如Masked Image,Mask等)都通过插件的形式注入到基座模型的UNet,提升了算法的可迁移性。该Inpainting方法仍然是通过prompt的方式来控制mask区域要补出什么样的内容。
算法细节:
整个算法包含Masked Image Guidance和Blending Operation 两个步骤:
Masked Image Guidance:
设计了一个额外的分支通过插件的形式用来将masked image信息注入到原始基座模型中,具体做法在流程图中其实也表达的够清楚了:
对原始图像中要inpaint的区域涂抹为0,然后通过VAE提取得到
的masked image latent 对mask进行cubic插值的下采样得到
特征 对原始SD-UNet权重进行全拷贝【去除其中的cross-attention层并增加了输入通道数,论文称这个网络为BrushNet】,并接收9通道特征输入【noisy latent(4通道), masked image latent(4通道), mask(1通道)】,之后通过Zero Convolution的方式将该部署到原UNet中。
BrushNet不接受text embedding作为输入,所以其在拷贝权重的时候不拷贝corss-attention部分。这样做的目的为保证BrushNet只提供图像特征,文本特征仍然用原来的UNet。该部分用公式表达就是:
其中 是调节BrushNet的控制权重。 Blending Operation:
直接对Mask做模糊后,对生成结果和原始的Masked Image进行融合。
实验细节:
- 使用SD1.5作为backbone,去噪步数为50步,cfg=7.5
- BrushNet使用VAE提取masked image的特征【ControlNet则用未预训练的一般卷积层下采样,可参考这里】
- 对比SDXL下的ControlNet是3通道1024图像经过一般卷积编码得到4通道128大小latent,然后直接和4通道的noisy image latent相加!!而BrushNet是拼接得到9通道作为输入
- 在8卡 V100上训练430K步(3天左右)
其他:
算法优势-控制灵活性:
迁移灵活:未对原基座模型权重训练,所以可以快速适配到其他基于该基座模型的finetune模型中。
内容保持灵活性:通过
调节BrushNet的控制权重,可以控制unmasked区域的保持性。 融合灵活性:在最后Blending Operation过程中调整模糊程度,控制生成结果和原始Masked Image的融合程度。
BrushBench:构建了一个包含600张图片的评测标准集,该集合包含人像、动物、室内、室外等各种场景的图像。同时该评测集从mask类型上划分成random mask和segmentation-based mask
评测指标:
- Image Generation Quality:评测图像生成质量。常见的FID和KID对于当前T2I模型的评估相对落后了,作者使用了Image Reward (IR),HPS v2 (HPS) , 和Aesthetic Score (AS)三个指标评估生成质量。
- Masked Region Preservation :评估unmasked区域的保持性。使用Peak Signal-to-Noise Ratio (PSNR), Learned Perceptual Image Patch Similarity (LPIPS), 和 Mean Squared Error (MSE)三个指标。
- Text Alignment:评估生成内容与文本的一致性。使用CLIP Similarity指标。
灵活性与效果的权衡:作者也做了消融实验,证明如果基座模型的权重不冻住,那么效果其实是更好的,但是会限制其迁移的灵活性,所以最终还是决定冻住基座模型权重。
ObjectDrop
《ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion》
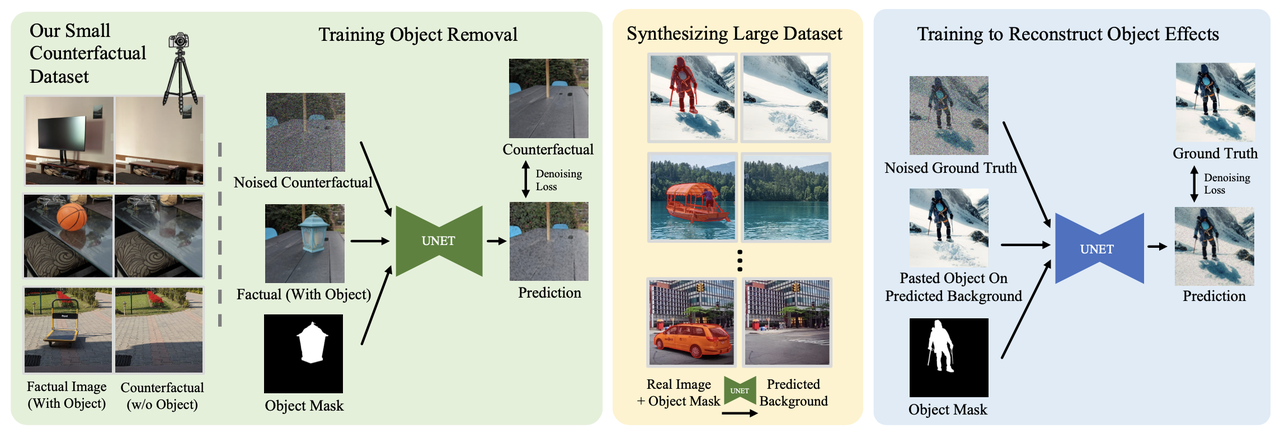
算法流程:本算法专注于在图像中的物体进行编辑时【例如去除或插入物体】,考虑其“遮挡、阴影、倒影”等附属效果,保证在编辑时这些附属效果也会跟着添加/去除,以进一步提升编辑真实性。为主体添加和去除分别训练了一个Diffision模型。同时为了克服这类数据集收集困难的问题,本算法提出了“Bootstrap监督”,即利用收集的少量物体去除时的数据集先训练一个物体移除模型,然后再合成方式扩展数据集。该算法在物体移除和插入任务上的表现显著优于现有技术,尤其是在模拟物体对场景影响方面。
算法细节:
任务描述:
其中 表示真实场景渲染,S表示场景, 和 表示修改前、后的渲染结果。在Object removal 任务中, ;而在Object Insertion任务中 。整个网络的输入输出分辨率为512x512,Denoise步数为50步。 Impainting任务的天然缺陷:
Inpainting通过一个mask强制将一张图像划分成两个区域(需要inpainting的区域
和不需要改变的区域 ),这样效果就受那个mask影响较大:太大的前景mask会导致很多背景发生变化;太小的mask又会导致inpainting受限,诸如“阴影、倒影”等区域无法覆盖到。 数据构造步骤:
先通过摄影师拍摄有和无主体的真实场景,尽可能取得只有这部分(主体和其附带的阴影、倒影等)改变而背景其他区域不发生变化,同时利用前景分割得到前景mask,最终得到的2500组的pair数据。每个pair包括【含主体的图
,主体mask ,不含主体的图 】。论文中称作counterfactual dataset 训练一个主体消除模型(object removal model)
用主体消除模型对未标注的图像进行主体和附属效果消除,构造更大的pair数据集-350K。
主体消除(Object Removal):
使用counterfactual dataset进行Diffusion训练:
其中在主体消除任务中 表示没有主体的结果, 代表对 加噪后的结果【在推理的时候就使用纯噪声】, 表示含有主体的图, 表示主体mask, 和 表示timestep和prompt。 Object Removal模型从Inpainting模型进行finetune,该Inpainting模型是其该算法团队内部的一个类似SDXL架构的模型。
主体插入(Object Insertion):
作者尝试过直接使用counterfactual dataset的2500图像直接训练Object Insertion模型,但是效果一般。因为附属阴影和倒影的生成要比消除难得多,于是作者进行了数据扩充(作者称这个步骤为Bootstrapping):
对采集来的、主体含有阴影/倒影的图像
先进行前景分割得到前景mask 使用Object Removal模型去除主体得到不含主体及阴影的图
, 然后再通过插值的方式将前景直接“粘贴复制”到
上:
最终得到的pair数据形式仍然为【含主体的图
,主体mask ,不含主体的图 】,扩充后的数据规模为350K。 Diffusion训练损失和Object Removal是一样的,只不过公式中的
表示有主体及其对应阴影的图, 表示直接将前景“粘贴复制”到背景上的图【其实就是上面的 】有没有主体的图。 Object Insertion模型从标准的text-to-image 模型
进行训练,同时添加了一些零初始化通道以支持更多的输入。至于为什么不用一些已经训练好的Inpainting模型,是因为Inpainting模型更擅长修复mask区域内的像素,但是对于前景区域外的像素(如阴影、倒影等)其修复效果并不理想。
DragDiffusion
《DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing》
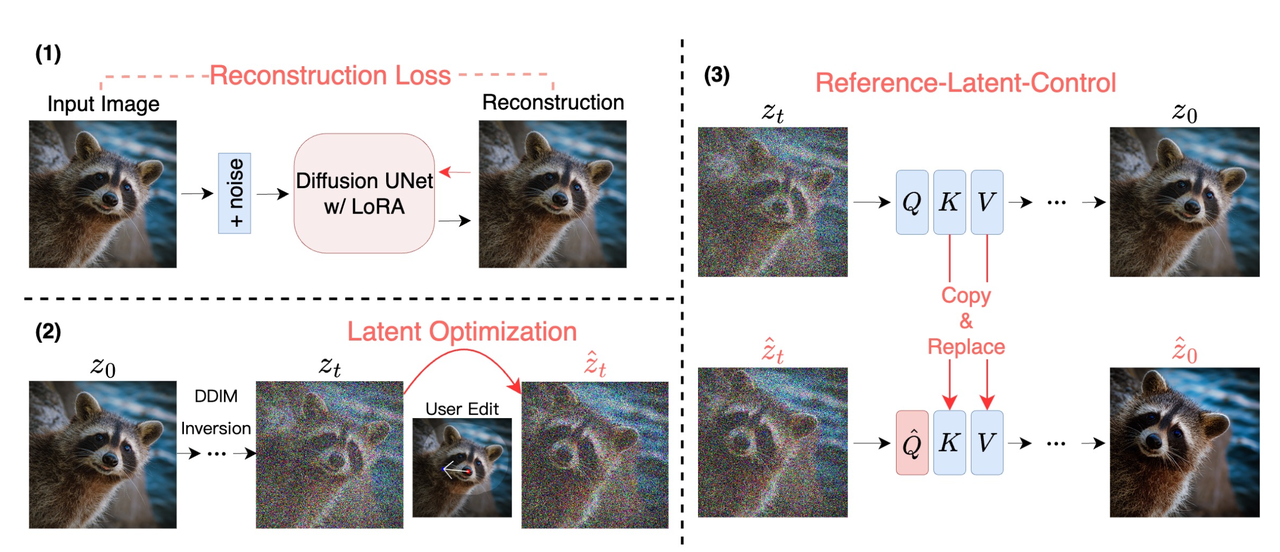
算法框架:将point-based editing从GragGAN扩展到Diffusion技术下,达到了更好的生成和编辑效果。本身是一个基于优化的编辑方法,在noisy diffusion latent上进行空间编辑。整个算法具体包括Identity-preserving Fine-tuning 、Diffusion Latent Optimization、Reference-latent-control 三个流程。
算法先验:UNet在某个特定的time step就已经提供了有效的语义和结构特征,这些特征足够进行point-based 的图像编辑任务。比如下面使用PCA对DDIM inversion 过程中的特征进行分析,50步的时候是纯噪声,但是在中间某个步数,比如35步的时候,图像的语义和结构信息就已经足够用于图像编辑了。
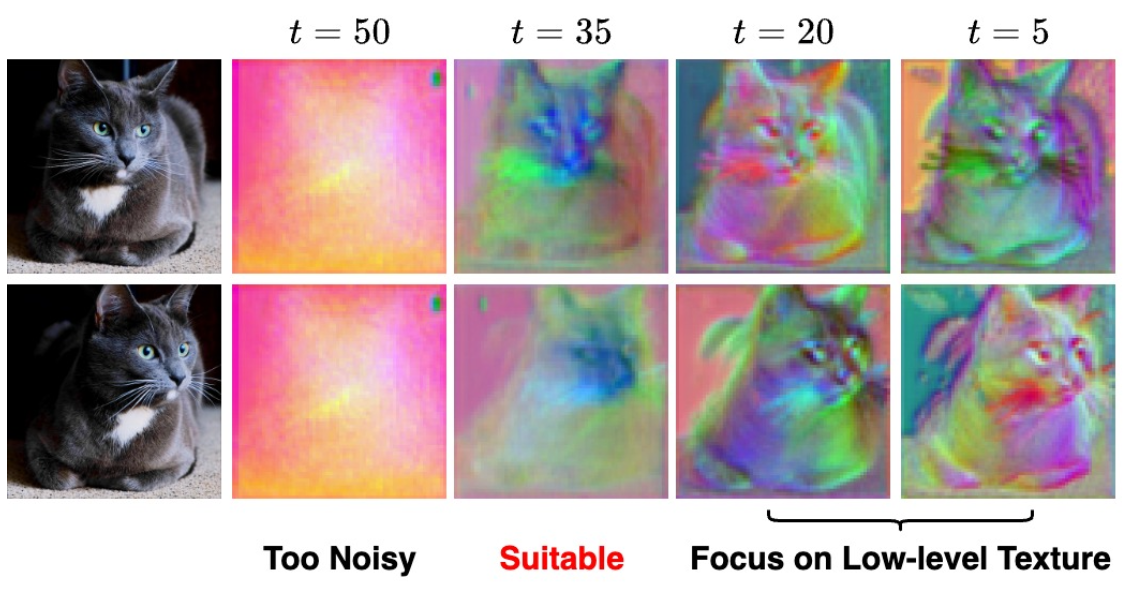
该方法是一个基于优化的编辑方法(optimizing diffusion latents),但是不同于之前的方法在Diffusion的多个time step的latent空间进行梯度下降,该方法只选择某一个time step下的特征进行优化。
算法细节:
整个算法依序包含Identity-preserving Fine-tuning、Diffusion Latent Optimization和Reference-latent-control共3个步骤:
Identity-preserving Fine-tuning :
因为要编辑我们指定的真实图像,所以该模块的作用其实就是保证Diffusion模型具有能生成我们指定图像的能力,其实就是相当于让Diffusion模型先提前看到待编辑的图像。
该本质就是一个LoRA模块,下公式中的θ 和 ∆θ 分别代表UNet和LoRA参数。
只仅仅需要训练80步就行了【在A100上25秒就搞定】 Diffusion Latent Optimization:
使用DDIM inversion对给定的真实图像加噪并获得某个指定time step下的noisy diffusion latent ,以此latent作为整个latent optimization 的起始点。
其实就是类似基于优化的GAN Inversion方法:以某个噪声为起始点,送到StyleGAN生成得到图像,并与指定的原始图像做MSE/VGG损失后,梯度反传并不断更新起始噪声,最后保证优化后的噪声在经过StyleGAN后生成的图像与指定的图像很接近,那么这时候我们就得到了该图像在StyleGAN的latent表示,并后续可以利用该Latent在各种比如W,W+空间进行图像编辑。
有了起始noisy diffusion latent后,首先要明确两点:
用户在编辑开始阶段会给定n组点,每组点表示需要将某个起始点
拖拽到目标点 附近 该方法并非一步拖拽【因为如果一组点距离太远,效果肯定不好】,而是迭代式地不断将起始点附近的图像像素给一步一步拉到目标点(比如一开始某个起始坐标
,然后将图像在该点附近的像素先拉到 ,然后再是 ,以此类推不断靠近目标点,最后就将一开始的像素拉到目标点附近),一共要拉K次,所以每组点就会有K个中间点,有就不断重复n步迭代优化以下Motion Supervision和Point Tracking两个步骤:
Motion Supervision:
首先规定几个变量:
和 表示用户最开始指定的一组【起始点(又叫handle points)和目标点(又叫target points )】 :表示在第k步优化,需要将用户指定的第i个起始点拉到的位置,其中 :原始图像,即待编辑的图像 :DDIM Inversion在第t步时的noisy diffusion latent : 在经过U-Net后的特征图 : 在 位置的特征向量 :表示一组点,这些点都在以 为中心, 为边长的正方形内。 :用户指定的Mask,即变动图像中的哪些地区域
然后就有以下的损失函数了:
上面的公式也是不断计算损失并利用梯度下降,迭代更新
,得到合适的编辑后noisy diffusion latent : 再拆解上面公式中每个变量的含义: :表示stop gradient operator ,即梯度不会通过该模块进行反向传播。 :从 指向 的单位向量 :以 为中心, 为边长的正方形的某个点 :表示最新 经过UNet后在 点位置的特征向量 :表示最新 经过UNet后在 在位置的特征向量
上面公式的意义其实就是将
点正方形范围内的特征图拉到一个更靠近目标点 的位置。 此外上面公式的后半部分(即
后面的)表示,在每次更新 后会进行一步去噪得到 ,并保证 在用户指定mask之外的区域不发生变化,和原始图像在该部分区域的特征是一样的。
【思考:这里的损失只是规定了目标区域的特征和原起始区域的特征接近,但是并没有限制编辑移动后原起始区域的特征,这会不会导致原来区域的特征不发生变化,从而导致出现“粘贴复制”的问题???】
Point Tracking :
在第k步更新完得到
后,我们按照之前说的,因为是一步步靠近目标点的,所以这时候需要第k步的起始点 计算下一步的位置 ,具体起始就是通过一个简单的距离计算,找到最接近的像素点: 即将以 为中心, 为边长的正方形内,最接近原始特征向量的点的位置赋值给 。 思考:这里会不会有可能
距离目标点更远了??
Reference-latent-control :
- 要解决的问题:在经过Diffusion Latent Optimization步骤后得到了Optimized Diffusion Latent,但是如果直接送到DDIM去噪的话,会发生identity shift和quality degradation的问题(总之就是效果不好)。
- 解决思路:论文借鉴了Masactrl的思想(mutual self-attention),在denoise的过程中使用原图的信息进行引导。
- 具体做法:在Denoise过程中,我们此时拥有原图加噪后在UNet中self-attention的特征,和Optimized Diffusion Latent经过UNet的attention特征,然后将原图特征的key和 value 替换Optimized Diffusion Latent特征中的key和value。
- 达到的效果:通过这种简单的attention特征替换,保证在denoise过程中,Optimized Diffusion Latent特征的query能够自动找到原图特征中的key和value,从而保证最终的编辑结果与原图在语义上的一致性。
实验细节
参数配置:
- 使用Stable Diffusion 1.5 作为基座模型,图像分辨率为512x512
- LoRA的rank设置为16,batch_size为16训练了80步
- latent optimization过程中,使用DDIM去噪且步数为50步,利用第35步的noisy latent进作为编辑特征
- 不使用classifier-free guidance (CFG) 技术:因为cfg在DDIM inversion过程中会出现数值误差导致图像的重构误差。
- 超参设置:
、 、
每次编辑的推理耗时:
- LoRA 的fine-tuning: 25 s
- latent optimization:10 s到 30 s 【具体取决于Grag点的数量】
- Latent-MasaCtrl 引导的去噪:1 到 2 s
对Diffusion本身生成的图像编辑:
- 在编辑真实图像的时候需要做LoRA的fine-tune,但是在编辑Diffusion文生图的的生成图像,我们不需要做LoRA 的fine-tune也不需要做DDIM Inversion,因为:
- 这里的LoRA就是为了让DIffusion模型“认识”我们指定的真实图像以保证其具备生成该图像的能力,而从噪声进行Diffusion文生图得到的结果,说明Diffusion已经具备了生成该图像的能力,自然就不需要LoRA了
- 已经有了最终生成图像的noisy latent,相当于已经有了编辑的起始点。
其实就相当于在原StyleGAN下,我们如果要编辑StyleGAN从噪声生成的图像,那么我们也不需要做GAN Inversion了,因为我们已经有了结果图像对应的原始噪声
DRAGBENCH Dataset
- 共含有205 张图片和 349 组编辑点对
- 包含动物、建筑、人像等10类图像
InstaDrag
《InstaDrag: Lightning Fast and Accurate Drag-based Image Editing Emerging from Videos 》
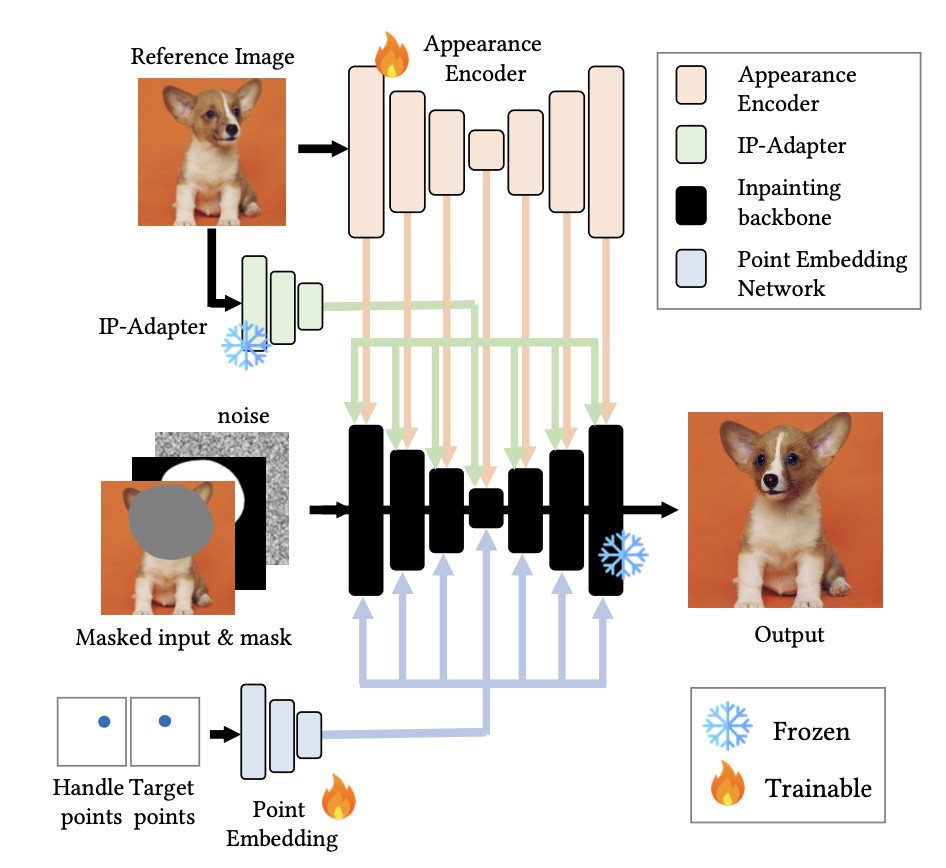
算法框架: 该算法将Drag-Based的图像编辑认作是一个条件生成的任务,从而大大减小了之前基于优化和DDIM Inversion的算法耗时【从DragDiffusion的55s减少到2s内,再配合LCM-LoRA则只有0.92s】。具体地,该算法将用户的编辑信息(即Drag信息)embedding后注入到网络中作为控制条件,不用重复计算diffusion latent的梯度并更新了。同时额外设计了一个Appearance Encoder保持原图像的细节信息。
算法细节:
数据集:
从视频数据中获得,具体步骤如下:
先挑选合适的视频:选择摄像头不动的那些视频,因为要尽量模拟Drag的效果,即只有部分区域发生变化而且其他区域不变。
挑选视频中的两帧作为首帧
和尾帧 (要过滤一下以避免选到那些静止帧),利用光流算法计算首帧中变动幅度比较大的像素点作为Drag的起始点 。 使用CoTracker2 算法计算尾帧中对应起始点
的目标点 。 使用相似度计算法方法,获取首尾帧中变化的区域,作为mask
表示编辑区域。 最终就得到了【
】作为最终的训练数据集。
网络结构:
Inpainting Backbone-保证未指定区域不变:
使用Stable Diffusion Inpainting U-Net 作为backbone,接收以下的concat作为输入-【噪声latent
,二值mask ,masked latent 】,此外要注意的是:这里并不需要输入text prompt,因为在drag-based的编辑任务中原图已经提供了足够的信息。所以,该算法使用IP-Adapter来提取原图的信息并将text prompt置空。 Appearance Encoder-编辑区域的identity保持:
接收原始latent
作为参考输入,并从其self-attention层提取特征,并将通过self-attention该特征加入到denoise的过程中: 其中 分别表示将denoise的特征与参考特征进行拼接。此外要注意的是,该Appearance Encoder是一次性的,对得到的参考特征在整个denoise过程中是反复使用的。这个整个过程其实也就是类似ControlNet Reference-Only的基本原理。 【疑问:感觉这里Appearance Encoder和IP-Adapter的作用是一样的啊?都是为了保持原有图像的特征,是不是有点重复啊?】问了原作者,其回答是:
- IP-adapter的appearance的信息不准确可能会导致编辑时候的identity特征发生变化,IP-adapter在这里的主要作用是替代文本,所以其实如果有文本输入,不用IP-adapter也行
- Appearance Encoder是加到self-attention,并且会给point特征一起作用到self-attention中确保编辑的位置准确性。
Point Embedding-保证起始点区域移动到目标区域:
将起始点和目标点分别画在一个和原图相同大小的画布上,然后通过Point Embedding网络(12个卷积层和SiLU激活函数)提取4种分辨率的特征(对应SD-UNet的4种分辨率的特征层)。然后再通过attention模块将点的embedding信息融入到网络中:
其中 分别是起始点和目标点的embedding信息。
推理时提升编辑效果的技巧:
从算法角度,提升编辑效果防止出现伪影:
Noise prior:
作者发现如果使用纯的随机噪声作为起始噪声,那么编辑效果会比较差,于是尝试了以下几种加噪方法:
- Noised source latents: 对原始图像latent进行全局加噪
==效果最好== - Mixed noise latents: 对Noised source latents中指定的待编辑区域再使用高斯噪声加噪一下,提升编辑灵活度。
- Copy and paste noise latents:将起始点区域的噪声latent拷贝到目标区域
- Noised source latents: 对原始图像latent进行全局加噪
Point-following classifier-free guidance:
类似原始的CFG算法,这里将point信息作为指导信息来加强去噪效果:
其中 分别表示appearance 特征和编辑点对, 就是将Point Embedding提取到的点特征融入到SD中,而 就是将点特征置空。通过调整系数 来调整point指导的强度,注意到该系数是一个与time-step有关的系数,即在去噪的不同阶段强度不同(比如是一个线性变化的过程:一般是在去噪前期t比较大时候强度大,后期强度小)。 从算法角度,提升编辑成功率【将起始点的图像内容移动到目标区域】
- Point augmentation: 那么就增加编辑点对的个数
- Sequential dragging:分多次拖拽编辑,避免一次性拖拽距离过大
DragonDiffusion
《DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models》
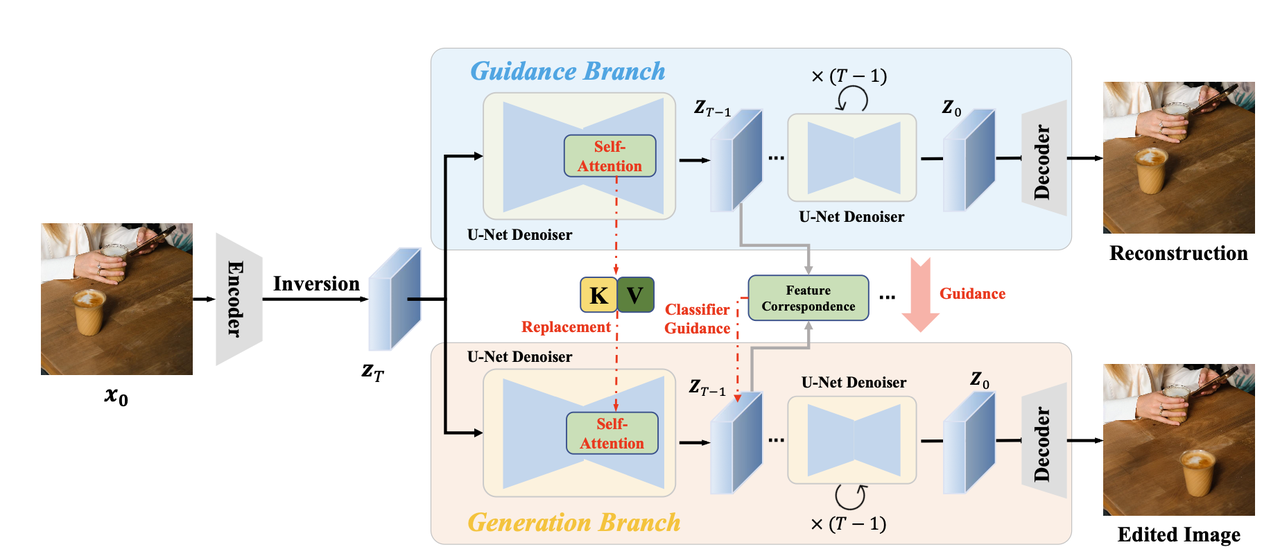
算法流程:该算法提出了一种Train-Free的图像编辑方法,能够完成物体移动、缩放、外表更换等编辑任务,总体来说其和MasaCtrl思路相同【也是两个分支进行attention替换】也是有两个分支【一个负责重构,一个负责编辑】,但是相比MasaCtrl只使用prompt进行编辑,该算法还显式添加了移动前后的mask作为guidance指导编辑任务【类似classifier-guidance】,该算法精度更高且更适合drag风格的编辑任务。
算法细节:
DIFT发现diffusion模型的中间特征具有很强的关联性,能够在不同图像之间用来进行point-to-point的匹配。具体地,算法对真实图像进行DDIM Inversion,然后分两个分支进行图像编辑:
Guidance branch:对inversion的结果
重构最终得到原图 Generation branch: 对inversion的结果
进行生成得到最终编辑的结果
具体地,在上述两个分支中作者使用了Classifier-guidance-based Editing和Cross-branch Self-attention 两个技巧完成最终的图像编辑:
Classifier-guidance-based Editing:
类似Classifier-guidance一样,在生成过程中利用额外的信息/函数引导生成过程,具体如下:
在
经过两个分支后分别得到UNet-Decoder中的两个特征图 和 ,在drag任务中希望目标位置出现和原位置相同的appearance,简单来说就是希望这两个特征图在编辑前后位置上的特征值相似,计算这部分相似度如下: 其中 和 分别代表编辑前后的区域mask【将物体从起始点拖拽到目标点】, 表示gradient clipping。 此外在drag任务中除了希望原始特征能够无保留的迁移到目标区域上,而对于剩下不编辑的区域肯定是希望不发生变化,假定这部分为mask
,那么也要计算这部分区域的在编辑前后的相似度 ,于是最终的guidance就变成了: 其中 和 是两个超参, 和 是两个权重用于平衡两项(前edit项称为editing guidance,后特征保留项称为content consistency guidance )的比例。 有了上述的guidance,就可以进行编辑生成了:
简单回顾下原始的Classifier-Guidance:
在该步骤中使用了以下几个小技巧:
Multi-scale Guidance :
作者使用重构实验(即
和 设置全0, 设置全1)证明同时使用UNet-Decoder的第二层和第三层的特征进行重构最好,这两层特征同时包含了高级和低级的语义特征,所以最终 和 也是均包含各自第二层和第三层的特征用于编辑任务。 不同编辑任务下的具体设定:
在不同的编辑任务下各个参数有略微不同的设定:
Object moving -物体移动:
和 表示物体移动前后的mask区域, 表示 的补集。同时为了防止移动后原始区域残留了一部分特征没移动干净【比如移动了面包但是还剩了点面包块在原区域】,作者额外添加了一个contrastive 损失: 其中
表示在原始区域但不在目标区域的那部分【即移动后需要inpaint的区域】虽然有了上面 的损失能够一定程度上减少大面积原始物体残留在原始区域,但是其实原始区域需要inpainting的地方并没有任何指导 信息,为此作者又设计了一个inpainting损失: 针对上面的各种mask这里做了个示意图:
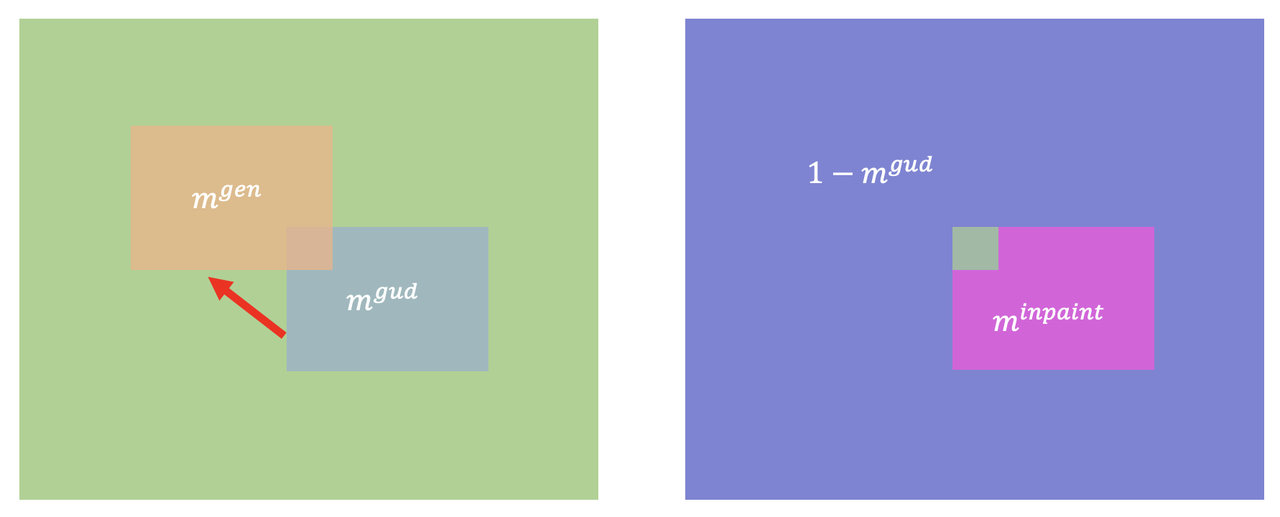 即contrastive损失是希望移动前后在玫红色区域两个特征相似;inpainting损失是希望移动前后,
即contrastive损失是希望移动前后在玫红色区域两个特征相似;inpainting损失是希望移动前后,在右侧玫红色区 域的特征和 在紫色区域的特征相似【即用原图在背景区域的特征去补全移动后目标区域的特征】。 Object resizing:
对特征进行缩放然后计算相似度:
Appearance replacement:
使用另一个同类的物体appearance来替换当前物体的appearance:
因为牵扯到另一个appearance reference image,所以这里 和 分别表示appearance图像的特征和mask区域。 > 作者在论文的第二个版本中,专门提到了Appearance replacement,在DDIM Inversion的过程中保存reference image在不同time step的key和value【称为memory bank】,并在denoise过程中使用reference image的key和value替换generation分支的key和value,具体可以看文章。 在该论文的第二个pdf版本中,对每个损失换了说法,具体对应关系如下: 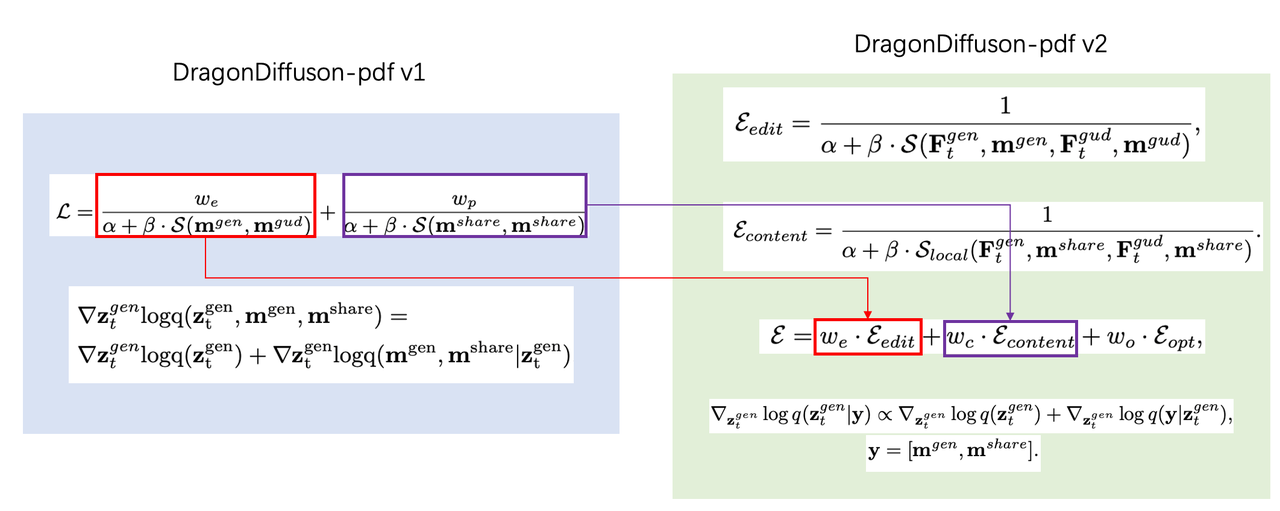 其中
其中代表每个具体任务额外的损失,论文pdf的v2版本阐述了整个算法的过程(ref上标代表参考图): 
Cross-branch Self-attention:
类似MasaCtrl中Mutual Self-Attention一样的技术,即使用guidance分支中attention的key和value替换generation分支中对应的key和value,同样也是用的UNet-Decoder部分的attention。该技术能够保证编辑后的图像和编辑前特征的一致性。
实验细节:
- DDIM Inversion为了保证重构精度,将prompt置空
DiffEditor
《DiffEditor: Boosting Accuracy and Flexibility on Diffusion-based Image Editing》
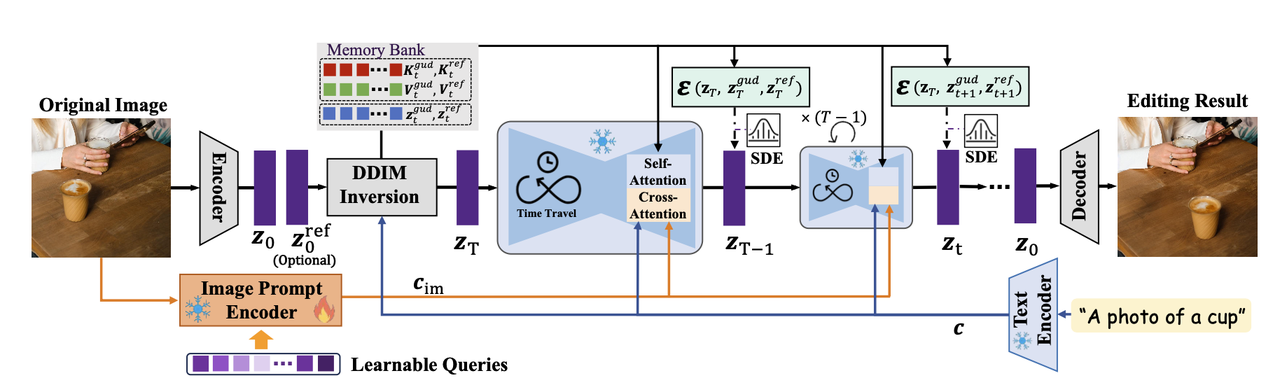
算法流程:本文在DragonDiffusion的基础上进行了优化,同样可以完成物体移动、插入、缩放、更换外表等任务,该算法使用Image Pormpt提升结果一致性,此外还采用了Regional gradient guidance和SDE采样等trick均有效提升了编辑灵活性和结果一致性,同时也解决了之前模型对于原图中不存在属性的编辑效果【比如编辑原图从闭嘴到张嘴】。整个过程对基础模型是冻住的,需要训练的部分是Image Pormpt的linear层和QFormer中的参数。
算法细节:
使用图像进行内容描述(Content Description with Image Prompt):
作者任务在编辑任务中,图像相比文字能提供更丰富的描述,于是使用类似IP-Adapter的方式将图像信息注入到后续生成中。具体使用CLIP的image encoder将图像编码成257长度的tokens,然后使用一个linear层调整通道维度后再使用QFormer的技术,利用learnable queries 去从257个image tokens中抽取信息,得到64个embedding tokens后再与257个image tokens组合作为后续的cross-attention的输入,像text embedding一样注入到UNet中,注入方式和IP-Adapter是一样的:
其中 和 分别是text和image的key和value。【如果生成参考图,那么 是原图和参考图的key和value的分别拼接】。整个训练过程冻住SD权重和CLIP-Image-Encder,训练linear层和QFormer。 使用区域SDE采样(Sampling with Regional SDE):
图像编辑中常用DDIM进行采样(比如DDIM Inversion),该方法属于ordinary differential equations (ODE)是确定性采样的一种,这种方法虽然能提升编辑一致性但是也会限制编辑灵活性。而DDPM则是stochastic differential equations (SDE) 属于随机采样的一种。
此外之前为了保证编辑结果和原始图的内容一致性,DragDiffusion使用LoRA而DragonDiffusion使用cross-branch attention,但是这些都会限制编辑的灵活性,难以生成新内容【比如论文中让狮子开口就失败了,因为原图中狮子是完全闭嘴的,无内容可作为编辑生成的reference】。
为了同时保证编辑的灵活性和一致性,作者在DDIM的过程中将参数
设置大于零将确定采样变成不确定采样,公式化表达如下: 参数具体意义可详见DDIM的推导,此外在DragonDiffusion中该参数为0即变成了确定采样,导致最终编辑结果高度依赖于cross-branch attention,即从原始图中提取信息从而限制了灵活性。 其中
和 都是 的意义, 代表DDIM采样, 表示待编辑区域的mask。即在不同的去噪time step,不同的图像区域给定不同的 值。 使用Gradient Guidance进行编辑(Editing with Gradient Guidance )
区域化梯度指导(Regional gradient guidance )
DragonDiffusion中的edit和content consistency是针对整张图像进行全局梯度计算的,但是作者发现这种会导致梯度的弥散【比如编辑区域的梯度弥散到了背景区域】,所以这里针对控制条件的gradient guidance做了区域化隔离,具体如下:
Time travel:
作者针对
进行回顾:DragDiffusion将其作为一个可迭代优化的参数,而DragonDiffusion使用gradient guidance指导其生成采样的方向,作者则综合了量真的优势设计了一个循环指导的trick,即在生成过程【即 】进行回传即 ,同时为了避免随机噪声带来的内容一致性的损失,作者使用DDIM Inversion的确定采样完成此回传过程。 作者在每次的gradient guidance采样后执行三次回传。该trick的好处是可以使用更少的gradient guidance采样次数【比如每两步time step进行一次guidance,加速生成过程】
整个算法过程如下:

实验细节:
- 使用SD1.5作为backbone,分辨率为512x512
- batch_size为16,在4卡A100上训练了10万步
- DDIM采样50步,classifier-free guidance系数为5
DragDiffusion和DragonDiffusion都不使用文本作为编辑控制
DiffUHaul
《DiffUHaul: A Training-Free Method for Object Dragging in Images》
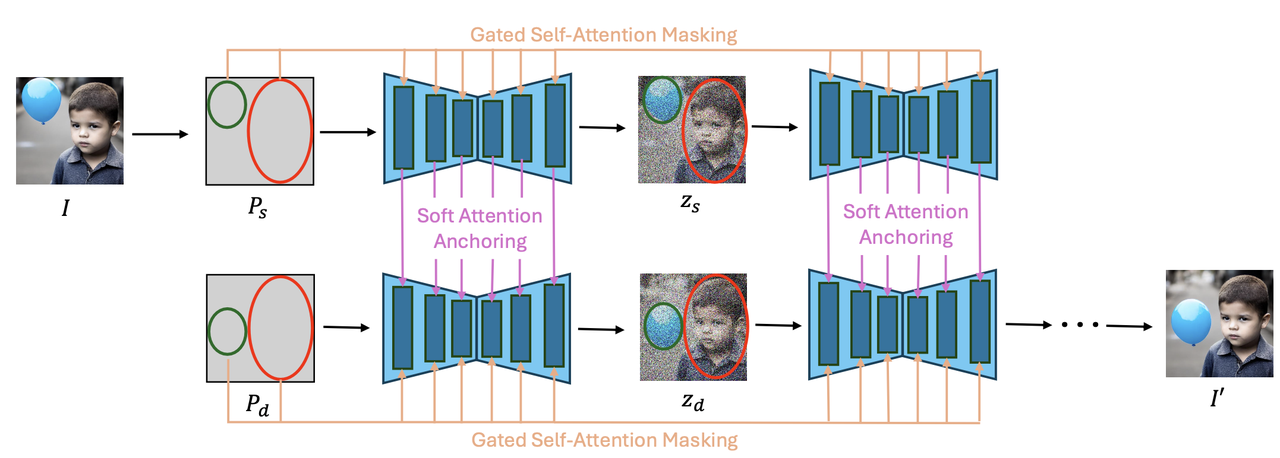
算法流程:该算法提供了一种Training-Free的方法对图像的物体进行移动,并且能够保持如倒影等物体本身附属的效果。该算法使用具有location控制能力的模型BlobGEN作为backbone,改进了两个算法-Masked Gated Self-Attention【对GLIGEN的Gated Self-Attention的改进】和Self-Attention Soft Anchoring【对MasaCtrl的Mutual self-attention的改进】,提升了移动后物体的细节保持能力。
前置工作-BlobGEN:
本算法以带有布局控制性质的BlobGEN为backbone,该BlobGEN的细节如下:
BlobGEN以两个参数为条件生成带有布局的图像
- Blob Parameters:
表示一个椭圆形状的位置和朝向,其中 是椭圆中心坐标, 是椭圆长轴和短轴半径, 是椭圆摆放角度。 - Blob Description:
表示椭圆内要生成的图像描述。
- Blob Parameters:
BlobGEN在网络结构上使用了两个专门设计的attention机制:
类似GLIGEN的Gated Self-Attention:该机制在pre-trained的LDM模型的self-attention和cross-attenion中间插入了一个专门设计的attention,该机制为模型添加了条件生成的控制(诸如depth、bbox)。
Masked Cross-Attention:feature map经过mask后和blob embedding拼接
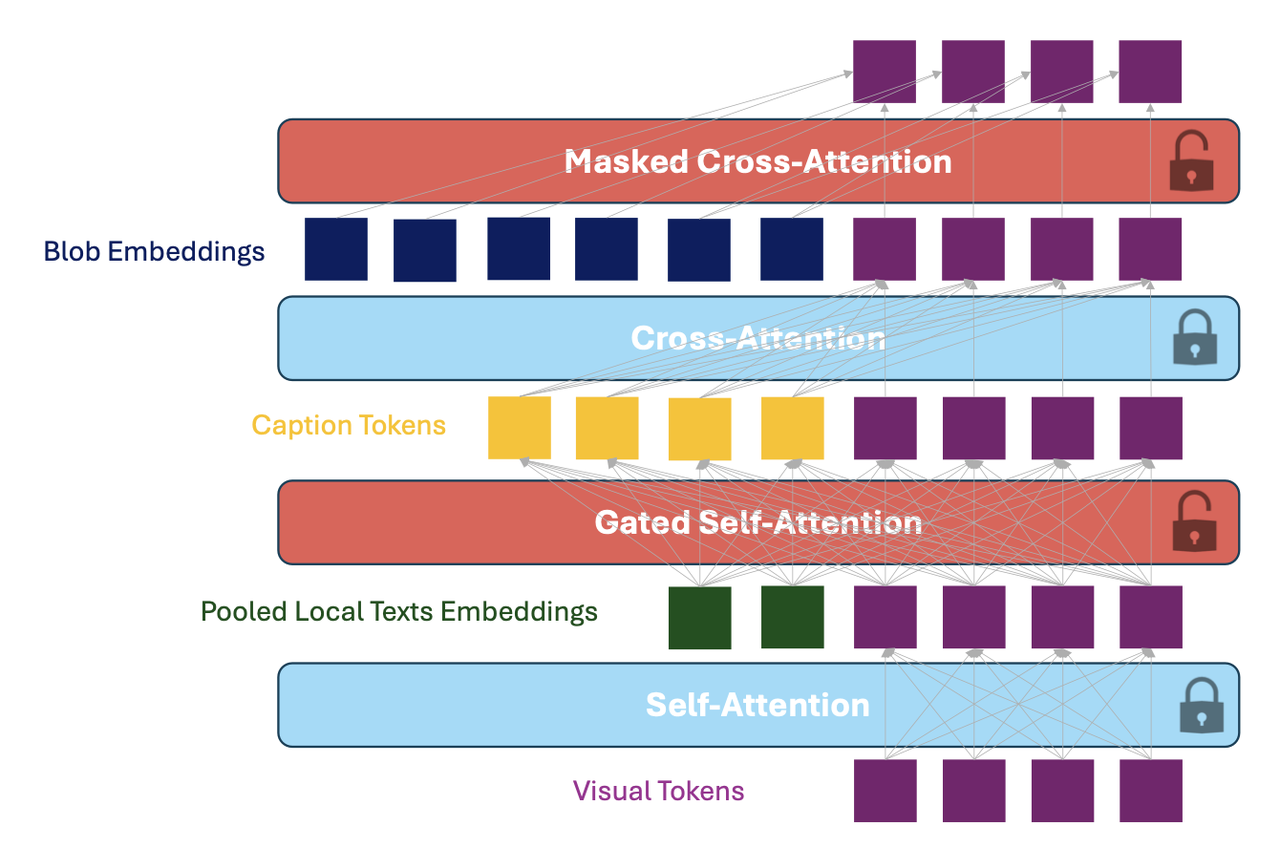
算法细节:
Masked Gated Self-Attention:
这是对GLIGEN的Gated Self-Attention的改进,用在单个图的denoise过程
Gated Self-Attention接受多个visual tokens和多个Local text tokens的拼接作为输入,然后对拼接结果做self-attenion。作者经过实验表明:这其实就是一个corss-attenion的操作,并且这种attention有可能会“溢出”,即某个local text token可能会和其对应的visual区域之外的visual token产生关联【即下图中第一行中用于描述红色框的"兔子"text token溢出到蓝色框的猫区域】
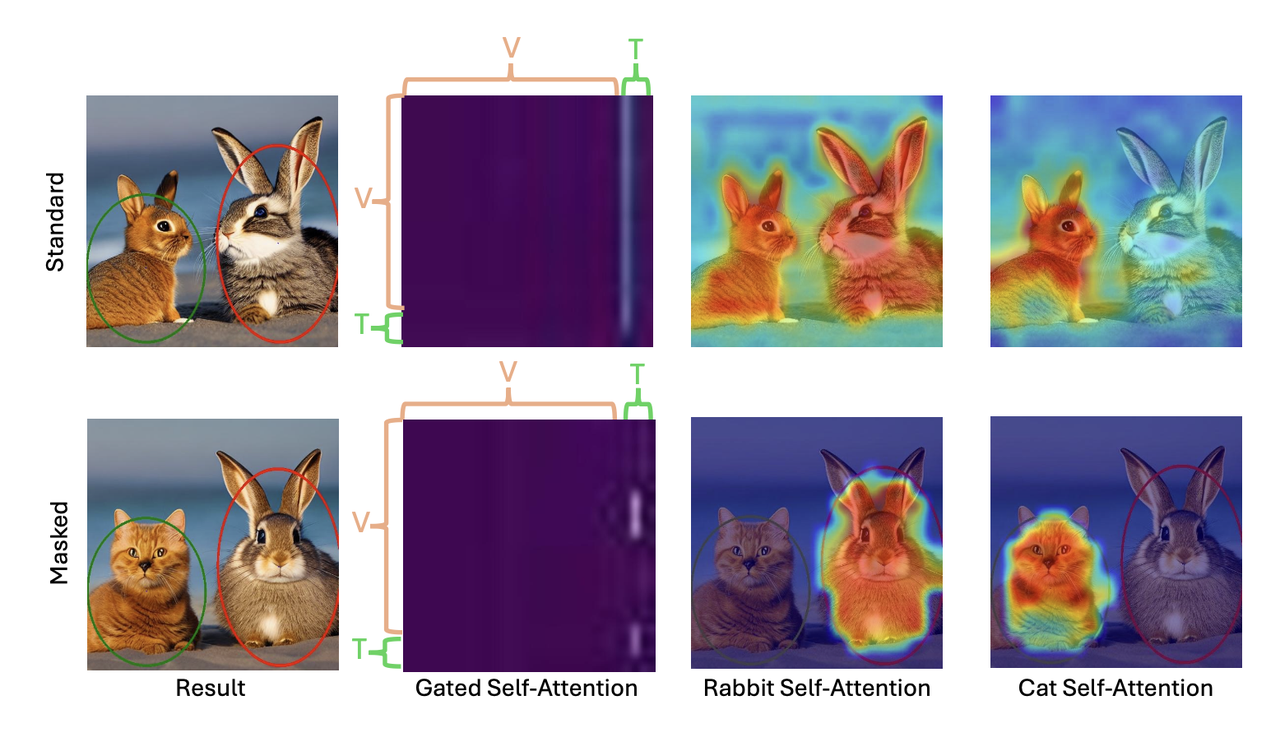
于是对BlobGEN的Gated Self-Attention进行优化提出了Masked版本,即针对n个blob参数,先得到对应的n个mask,然后在diffusion的过程中将不属于同一个blob的text token和visual token给masked掉。如上图的第二行,在经过mask后,“兔子”text token只会映射到图中的兔子区域,而不会泄露到“猫”的区域。
Self-Attention Soft Anchoring:
这是对MasaCtrl的Mutual self-attention的改进,用在原图和目标图的denoise过程的特征共享。
原Mutual self-attention是在生成目标图的同时,也会对原图进行并行生成,并使用原图attention的key和value特征在替换目标图在denoise的key和value。但是原算法是让网络自己去找对应性,不可避免会产生细节的丢失和找错的问题,虽然原MasaCtrl提出了Mask-Guided Mutual Self-Attention缓解该,但是该仍然存在存在。
因为在本算法中,需要修改的目标和区域是确定的【即将某个物体从
移动到另一个区域 】,所以作者显式地在生成目标图的过程中,将原图中 区域的attention特征"copy"到目标图的 位置上。具体操作是在denoise的前P步通过插值的方式融合原图和目标图的特征,而在denoise的p步之后,通过最近邻的方式直接将原图的特征copy过来,示意图如下: 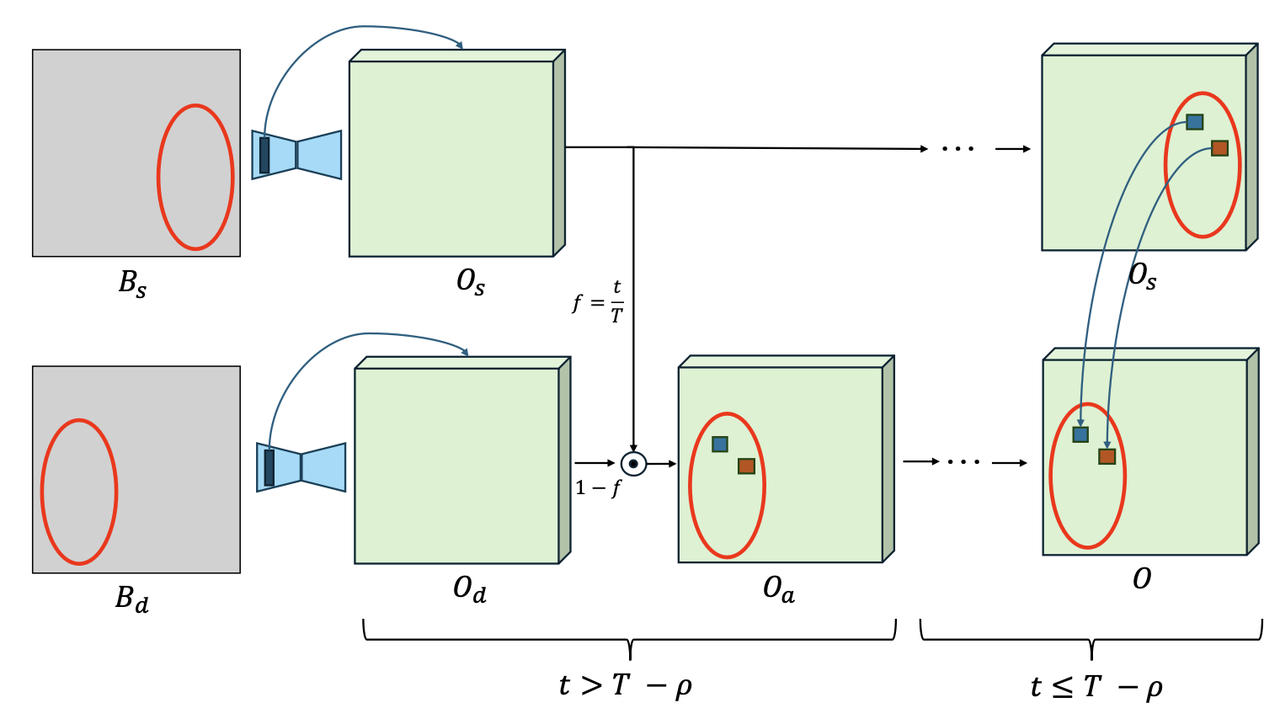
其他:
- 真实图像内的物体移动:
- Inversion:之前对真实图像进行编辑时通常是利用DDIM Inversion的方法将得到真实图像的noisy latent。回顾上面的算法:当我们对一个本身就是生成图像进行编辑的时候,我们需要的仅仅是原图的 self-attention特征,所以作者提出了DDPM self-attention bucketing:在不同time step对真实图添加不同程度的噪声,然后将该noisy latent和提取到的blob特征送给模型就得到self-attention特征。【作者有强调这种方法可能只适用于object dragging任务。】
- Blob信息提取:使用ODISE进行实例分割得到mask,然后计算与该mask最小IoU的椭圆形。然后将每个实例crop出来后使用LLaVA-1.5进行局部打标。
- 在一副真实/生成的图像中,移动其中的主体并且保持原始背景不变,这个任务对当前的图像编辑任务是很难做到的。
- 真实图像内的物体移动:
背景保持:作者还使用了Blended Latent Diffusion进行背景细节的保持。
Omnimatte
《Omnimatte: Associating Objects and Their Effects in Video》
【主页】【论文】【代码】【research.google】
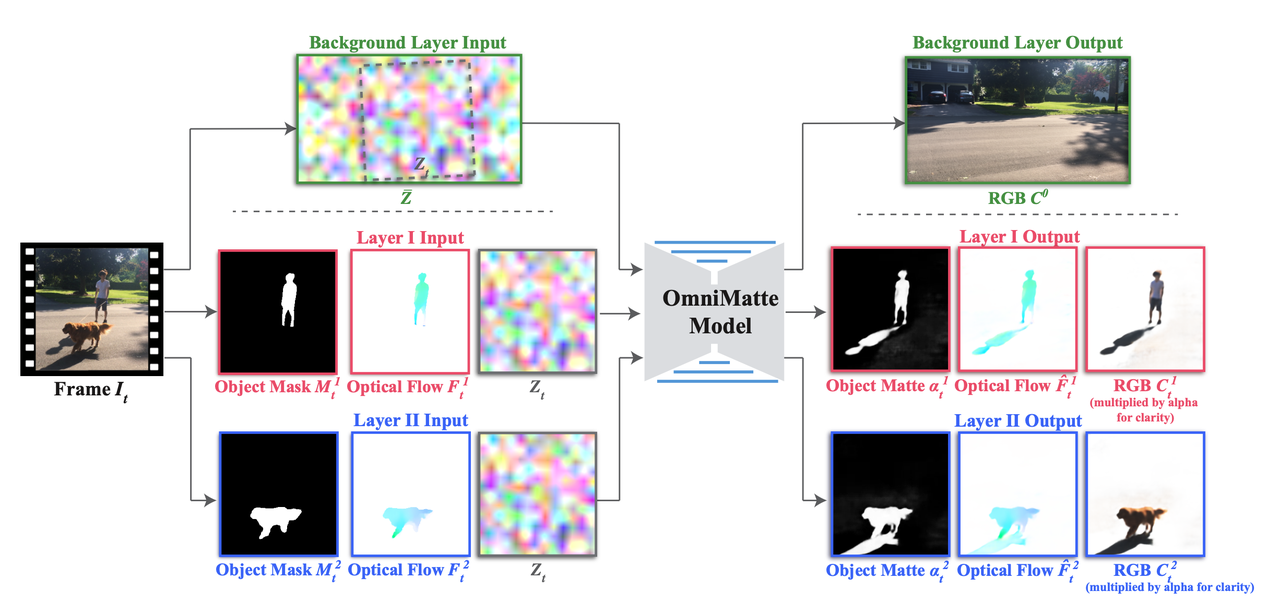
算法流程:本文是一个非Diffusion的方法,其提出了针对视频的matting技术,该matting不仅能够将前景分割出来还能将与其相关联的各种伪前景(比如前景的阴影、倒影等)都分割出来,论文称Omnimatte。该方法对于一张图像中指定的每个前景都按照图层的形式进行处理并返回每个图层中的Omnimatte。该方法并非是Diffusion/GAN框架【上面的噪声
并非是Diffusion中的噪声,而是与相机有关的一个表征】,但是其是第一个提到要与前景有关的全向分割技术。 该算法保证对一个物体进行编辑(消除、添加、移动等)时,那么它附带的阴影、倒影、烟雾等都需要跟着变动。
算法细节:
输入输出:
- 4个输入:分别为第t个视频帧
和相机对应性 (论文和代码都没有公开这里到底怎么计算的,不过好像是个类似SIFT做特征匹配的事情,可以用Opencv的findHomography函数计算)、第t个视频帧中第i的主体的前景Mask 和光流信息 。 - 3个输出:分别为effects相关的matting alpha、整个关联的前景(其实就是matting出来的全部关联前景)、下一帧的物体光流。
- 4个输入:分别为第t个视频帧
训练损失:
Reconstruction Loss:
其中 表示网络输出的第t帧中第i个物体的Omnimatte alpha和抠出来的关联前景, 是原图中对应部分, 表示一种图像合成技术,然后该重构损失就是保证合成后的图要和原视频帧 相同。 Regularization Loss:
为了防止重构损失让每一个图层都返回全部的前景(即
全1导致重构整张图),正则化损失则保证每个图层都只返回自己前景的Omnimatte alpha。 其中
用来惩罚那些非0的值,保证 不要是全1 Bootstrap Loss:
为了保证输出的Omnimatte alpha尽量和原本只有前景的mask相同,作者使用了一个引导损失。
其中 表示边缘腐蚀的mask,用于关闭在边缘部分的损失。要注意的是该损失在收敛到一个相对稳定的值后就固定了,不能一直优化下去。【该损失只是引导作用,不然最后Omnimatte alpha和原本前景Mask完全一样,并不是我们要的结果】 Flow Reconstruction Loss :
网络还预测每个帧的光流信息作为网络的辅助任务,来提升模型的整体效果。
其中 表示预测的第t帧中一系列前景的光流map集合。同样使用图像合成技术得到预测的完整的光流图,并与预先计算好的光流图GT计算重构损失。 Alpha Warping Loss:
为了保证时序一致性(即两个帧之间预测的Omnimatte alpha要连贯平滑),使用warp损失:
其中 表示使用当前预测光流 对下一帧预测的Omnimatte alpha 进行warp,并与当前帧的 计算重构损失。
实验细节:
- 使用Mask R-CNN 进行主体分割,使用STM(一种视频主体分割技术)来跟踪每帧之间的主体
- 使用RAFT计算连续帧的光流
其他:
- 算法应用:
- 主体自然消除:在主体消除中完成连带阴影的一起消除
- Color Pop:对图中主体及其相关的effect高亮显示
- 视频编辑
- 与Instance Shadow Detection比较:该方法整体检测效果更好,且也能检测那些非地面的阴影区域
- 局限性:对背景移动太大的场景效果可能比较差
- 在这个Issue中提到需要对每一个视频训练一个模型
- 算法应用:
总结
图像编辑给予了Diffusion模型更多的应用和落地方向,本篇文章的几种编辑方法基本可以分为3大类:
- 无Mask的隐式编辑方法:以Prompt2Prompt、InstructPix2Pix、MasaCtrl为代表,这类方法直接通过prompt形式告诉模型要如何编辑,并非需要指定编辑的区域而是让模型自己去找到需要修改的区域。这类方法通常可应用在指令式编辑做同款等相对更自由的方向。
- 有Mask的隐式编辑方法:以MimicBrush、BrushNet为代表,这类方法类似Inpainting算法,需要额外指定一个Mask将修改范围基本限制在指定的区域,通过prompt或者参考图的方式作为引导生成。这里方法通常可用于换背景等需要严格限制编辑区域的方向。
- 拖拽式的编辑方法:以ObjectDrop、DragDiffusion等剩下的算法为代表,这里方法可能需要mask或拖拽点的方式对进行主体移动、主体消除等编辑效果