一个图像的风格可以看作是图像的色彩、纹理等与内容无关的信息,而风格迁移旨在保证生成的图像具有指定的风格(不管是通过prompt指定还是通过图像指定),对于有指定内容的风格迁移,不仅要求生成结果具有指定的风格,还要保持和内容图具有相同内容(比如语义信息、layout),风格迁移的效果可以参考下面的示意图:

Style Aligned
《Style Aligned Image Generation via Shared Attention》
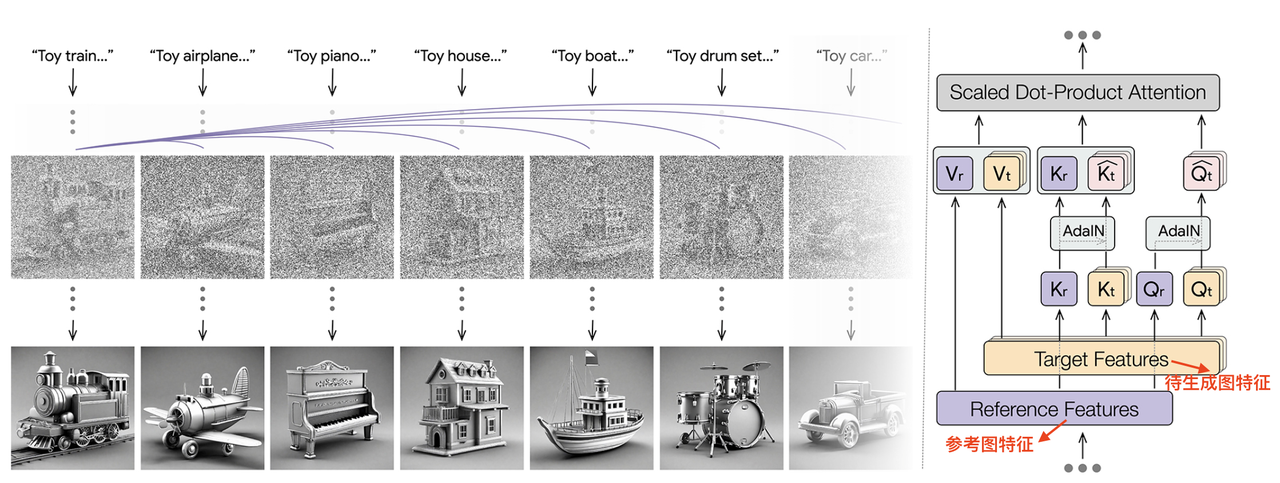
算法流程:本算法提出了一个training-free的方法进行风格迁移,在生成的过程中通过共享图像之间的attention特征来保证生成风格一致的图像,此外也通过限制共享attention的图像数量和AdaIN方式解决内容泄漏问题并提升了生成的多样性。不过本算法并没有显式的分离图像中的content和style,而是作为整体进行attention sharing。【该算法专注于text-2-image下的风格引导/迁移,在论文中未提及指定content图像的风格迁移】
其实之前多视角生成算法,如SyncDreamer也有过类似的想法,在生成过程中共享一些信息同时进行denoise,保证视角生成的一致性。
算法细节:
核心-Attention共享:
该算法旨在生成过程中共享特征完成信息互通,具体地在self-attention层拼接所有图像的K和V来生成当前图像的Q,公式表达如下:
SD模型中的self-attention是从当前的noisy latent中提取QKV做attention,而这里的attention中的K和V是从n张图像的生成过程中的特征同时提取的K,V的拼接,即:
进一步优化:
作者在上述attention sharing核心思想的基础下又进行了几项优化:
Restrict the Content Leakage(避免信息泄漏):
问题:作者发现如果在SD中全部的attention都进行共享的话,会导致内容泄漏,即当前图像生成的内容(比如物体、颜色)等会复制到其他图像中,这也会导致生成的结果多样性降低。
解决:只从集合中的某一张图像(或者参考图)做attention sharing。这时候K和V就只有当前图像本身的KV和参考图像的KV。
Enable balanced attention reference(平衡注意力风格):
问题:减少attention sharing虽然能避免内容泄漏但是也会造成参考的信息太少进一步导致生成的图像风格一致性没那么好。
解决:使用参考图像(即Reference Image)的query
和key ,并结合AdaIN技术对当前图像(即Target Image)的query 和key 进行归一化,具体公式如下: 回顾:AdaIN的公式为:
该算法中的
,最终的self-attention又改写成了 ,其中 ,注意到这里 是没有做AdaIN的。上面每一步的优化结果如下: 
实验细节:
- 以SDXl为基础网络,在A100上生成4张图像需要29s
- 在生成过程中,reference图像是不受其他图像影响的
其他应用:
指定图像风格迁移:上面都是在一个 batch生成过程中以第一个noisy latent作为reference的,而对于指定的reference图像,要先使用DDIM Inversion得到中间noisy latent然后进行
配合其他插件:配合ControlNet完成指定风格的条件生成;配合MultiDiffusion完成指定风格的全景图生成
InstantStyle
《InstantStyle : Free Lunch towards Style-Preserving in Text-to-Image Generation》
【主页】【论文】【代码】【HuggingFace】
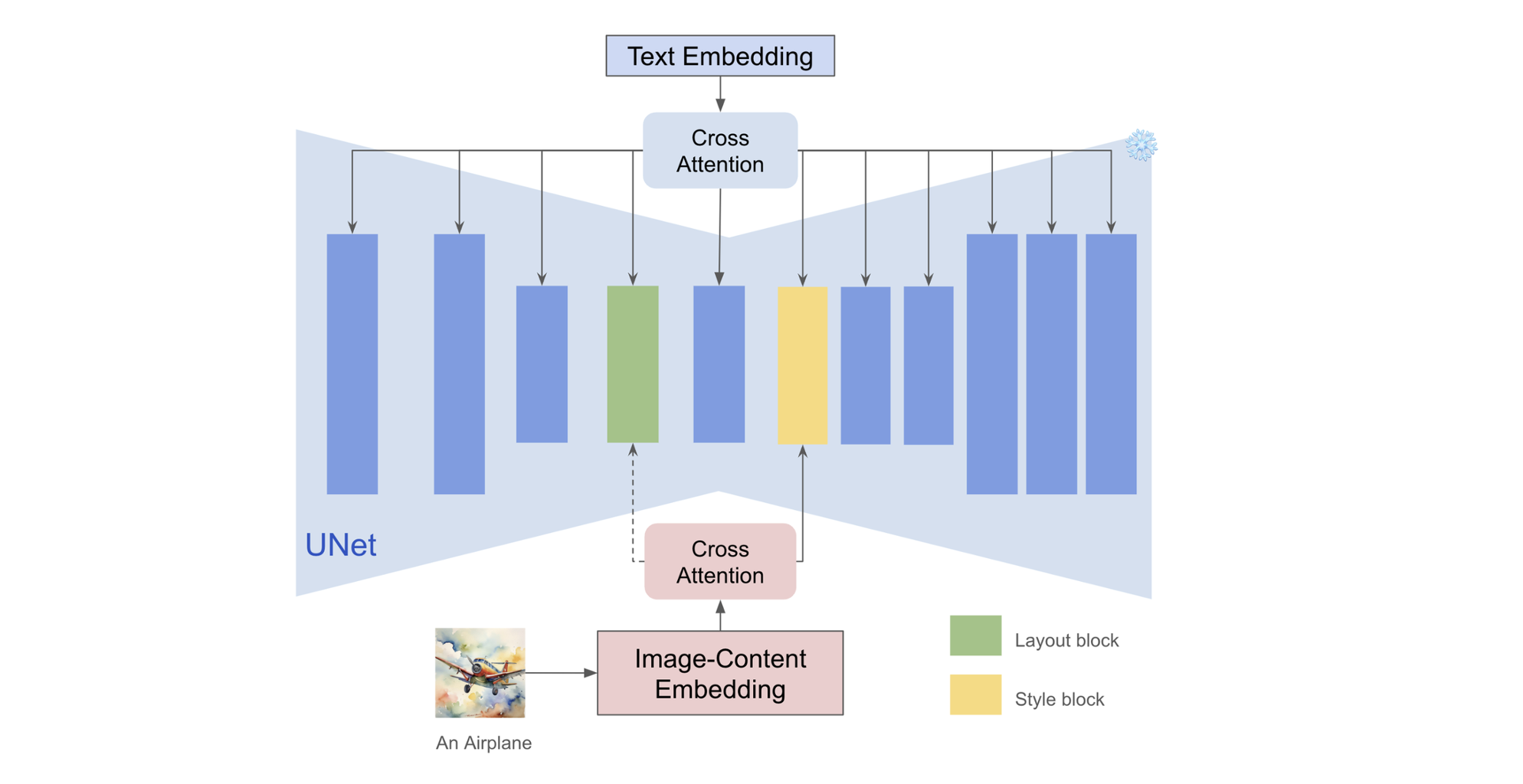
算法流程:本算法基于预训练好的IP-Adapter实现training-free的风格迁移方法,其借助CLIP特征的算术法则来提取不含内容只有风格的image embedding,并将embedding通过cross-attention的方式只插入到UNet指定的blcok(该block经过验证是对风格影响比较的),通过这两种trick实现风格迁移过程中content和style的解耦,减少内容泄露提升生成效果。【和StyleAlign一样,该算法专注于text-2-image下的风格引导/迁移,在论文中未提及指定content图像的风格迁移】
目前两种常见的风格迁移方法:
- Adapter-free :如Style Aligned借助参考图像的attention特征进行生成。通常需要配合inversion算法提取参考图的attentionte特征然后concat到目标图的生成过程中,这不仅耗时多也会导致风格细节的损失。
- Adapter-based :如IP-Adapter通过一个额外的encoder提取参考图的特征并注入到denoise过程中。该类方法通常无法有效解耦content与style,过高的注入权重有可能会造成content的泄露,导致文本控制能力降低;但是过小的注入权重又无法实现比较好的风格保留。
算法细节:
- 算法先验:
Subtracted CLIP’s embeddings as disentangled representation
CLIP的特征空间是符合算数法则,可以进行简单的加法和减法的。比如在使用CLIP进行特征检索的时候,如果给定一张空街景的图像和一个prompt
cars,用这两个合并后进行特征检索,就能搜到那些有车街景的图像,如下所示:
The impact of different blocks is not equal
在CNN网络中,浅层的特征通常代表low-level的表征(如shape, color),而深层的特征代表更高level的语义特征。在Diffusion方法中,这种逻辑规则也是同样适用的。
作者发现在Diffusion(具体是SDXL模型)中有两个attention层对于风格具有比较好的表征效果(up_blocks.0.attentions.1 和 down blocks.2.attentions.1层),分别代表style (color, material, atmosphere) 和空间layout(structure, composition) 。【后者将layout认作style元素的一种具有主观性】
- 算法步骤:
在风格迁移前,我们有<风格图,风格图prompt,目标图prompt>
使用CLIP的text encoder和image encoder分别提取风格图prompt的text embedding和风格图的image embedding。text通常是表示图像的内容,然后得益于CLIP特征的算术法则,可以直接用image embedding减去text embedding就获得了与内容无关的风格特征。
将上述提取到的特征,通过cross-attention的方式注入到UNet中,但是只注入到指定层的的attention(如up_blocks.0.attentions.1 和 down blocks.2.attentions.1层)【👉🏻其实就是局部注入的IP-Adapter】
- 算法先验:
实验细节:
- 基于SDXL和IP-Adapter进行实验
- 作者也尝试过重新训练IP-Adapter但是只训练负责style的block attention层,有趣的是作者发现最终效果和直接使用原生pre-trained的ip-adapter效果差不多,所以作者就直接使用pre-trained模型。
InstantStyle-Plus
《InstantStyle-Plus: Style Transfer with Content-Preserving in Text-to-Image Generation》
【主页】【论文】【代码】【HuggingFace】
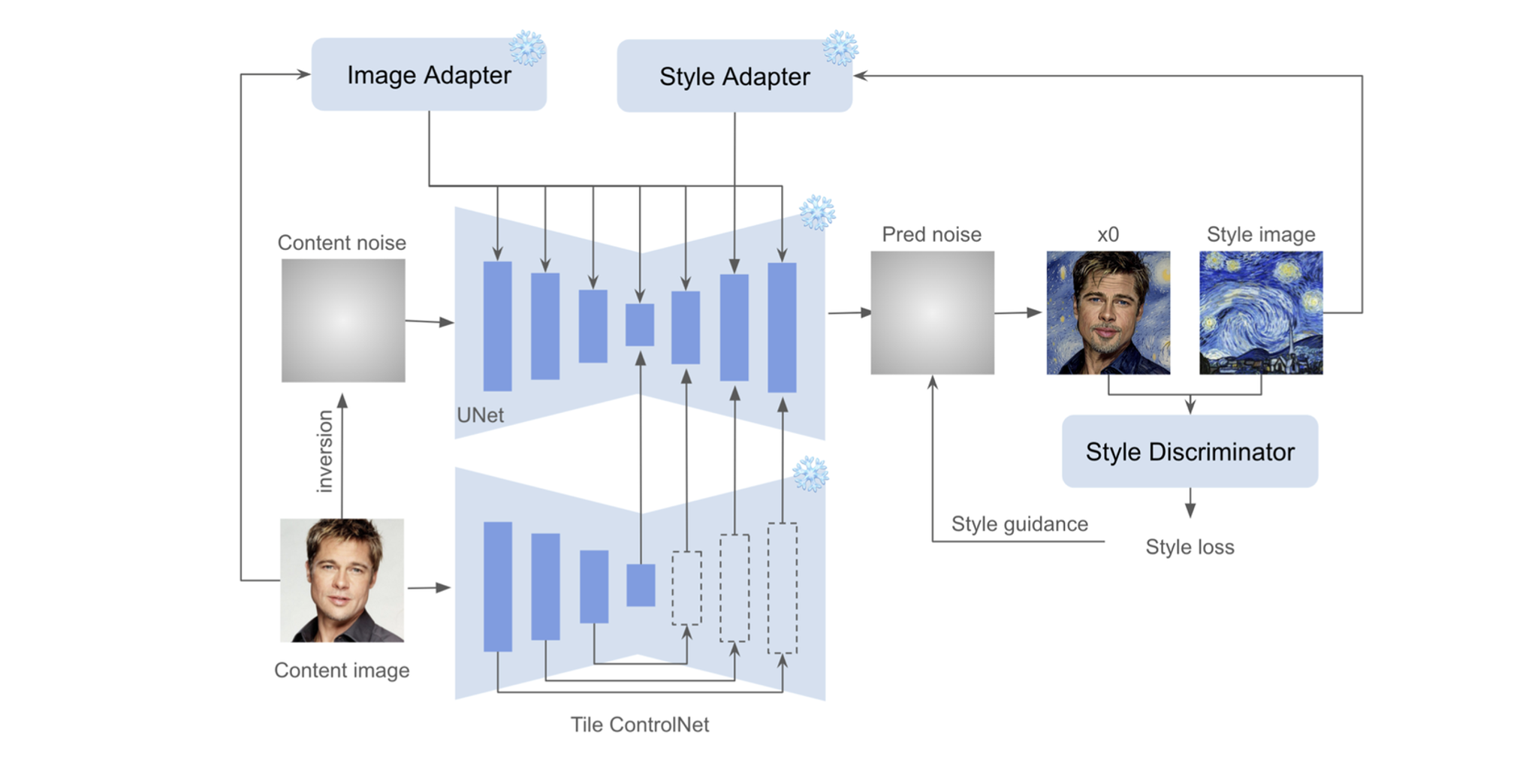
算法流程:该论文不仅局限StyleAlig和InstantStyle能做text-2-image的风格迁移【即无法做对指定content图进行风格迁移】,而本算法则提出了一个能很好保留指定指定content图像信息的风格迁移方法,主要包含三个内容:风格插入(style injection), 空间结构保持(spatial structure preservation)和语义内容保持(semantic content preservation )。
算法细节:
Style Injection【风格插入】
该部分沿用了InstantStyle的思路:即通过IP-Adapter的方式将 CLIP提取到的风格特征以decoupled cross-attention的形式插入到UNet中与风格有关的block的attention层中。不过需要注意的点是这里作者为了方便起见,并没有用CLIP image embedding减去CLIP text embedding得到内容无关的风格信息,而是直接将CLIP image embedding作为风格特征注入到UNet中。
Spatial Structure Preserving【空间结构保持】
内容保持作为该算法的核心,解决了StyleAlign和InstantStyle只能在text-2-image生成过程中进行风格迁移的局限(即不存在的图像),该模块允许对已有的图像添加风格。该模块主要下面两个注意点:
- Initial Content Latent :使用了比DDIM Inversion重构性更好、content保留更好的算法ReNoise,对content图像加噪得到初始化的noisy latent。
- Tile ControlNet for Content Preserving : 使用tile-based ControlNet进一步提取图像的content信息。
Semantic Content Preserving【语义内容保持】
除了空间结构,作者认为identity、gender、age和facial expression等更高级的语义信息对于内容保持也非常重要,所以作者使用了类似IP-Adapter和InstantID的方式,将CLIP提取到内容注入到UNet的所有attention层中。
Supplementary Style Guidance 【额外的风格监督】
作者借鉴CSD的方式,在特征层面计算风格迁移后的生成结果
和风格图的相似性并计算style loss,然后通过该style loss来继续更新预测的噪声,用于进一步提升生成结果和风格图的风格相似性。【style loss的具体定义可以见CSD】
实验细节:
以SDXL为backbone,总体遵循InstantStyle的设计原则,并且只重新训练了tile controlnet,其他模块都冻住
使用ReNoise算法进行Content image的inversion
使用官方IP-Adapter提取整张图的语义信息插入到UNet的所有层
使用CSD的style extractor进行风格引导
对比实验:对比了StyleAlign、InstantStyle和StyleID算法,其中StyleID已经专门设计了content保留,而对于StyleAlign、InstantStyle,为了对比公平作者则使用controlnet进行空间结构信息保留。对比下来当然是本算法的内容保留最好。
消融实验:
因为该方案是InstantStyle的一个优化版本,所以在此基础上对比了其他几个模块的重要性:

前两张是内容图和风格图,ICL表示Initial Content Latent、Canny表示Canny-based ControlNet、Tile表示Tile-based ControlNet、Sem表示Semantic Content Preserving、SG表示Style Guidance。
上面结果表明:
ICL(Initial Content Latent)有助于保留细节信息;
而tile-based controlnet对比其他类型的controlnet更有助于内容保留;
Sem(Semantic Content Preserving)模块虽然有优化效果但是也不多;
SG(Style Guidance)对于细节的风格化有优化效果(比如第一行人物的嘴边);
局限和思考:
- Inversion过程是耗时较大的,这可能是大规模应用的一个重要考虑因素。
- Tile-based ControlNet的潜力尚未完全实现,其功能有足够的进一步探索空间。
- Style Guidance虽然有效,但由于在像素空间中梯度的累积(更新noise),需要大量的显存,这表明需要一种更复杂的方法来有效地利用风格信号。
CSGO
《CSGO : Content-Style Composition in Text-to-Image Generation》
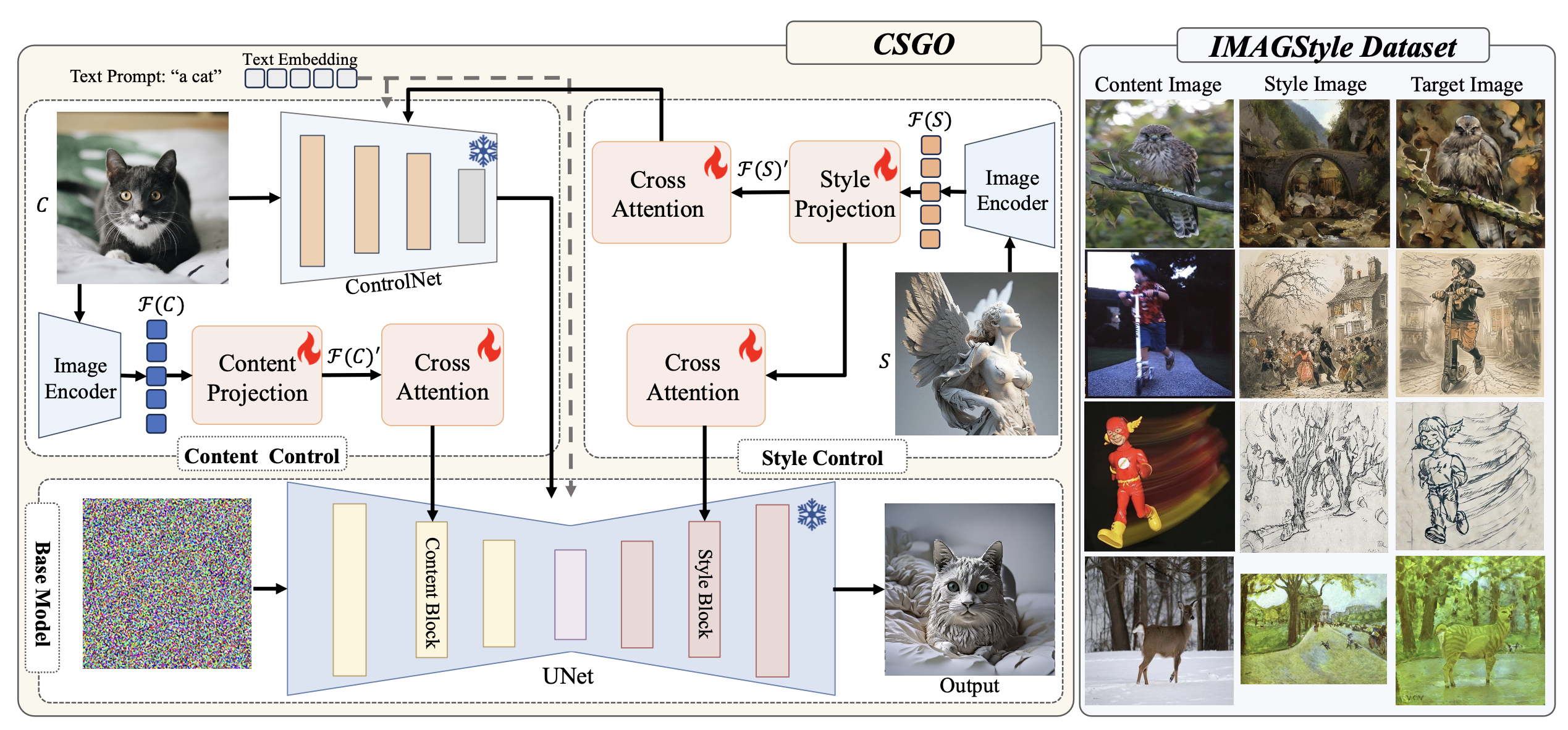
算法流程:在数据集上借鉴B-LoRA提出了一个有效构造【内容图、风格图、结果图】三元组数据的流程,在模型结构上分别通过两个Projection提取内容图和风格图特征,同时借助Tile ControlNet进一步提升内容保持,而且也将风格特征注入到ControlNet中提升了风格迁移的效果。
算法细节:
数据集:构造了包含21万个(内容图、风格图、结果图)三元组的风格迁移-IMAGStyle,具体包含两个步骤:
风格化图像生成(Stylized image generation):借鉴了B-LoRA的思想:一张图像中的内容和风格信息可以分别通过两个LoRA进行有效分离。于是首先在单张内容图上训练一个LoRA,然后通过B-LoRA算法将该LoRA分解成一个内容LoRA和一个风格LoRA。最后交叉组合不同来源的内容LoRA和风格LoRA就可以得到众多的风格化图像
风格化图像清理(Stylizedimagecleaning):上述方法生成的风格化图像还是会一定程度出现badcase,所以需要进一步清理生成的数据。为此作者提出了一个指标Content Alignment Score (CAS) 用于衡量风格化后图像与原始内容图像在内容上的相似度:
其中C和T分别表示内容图和风格化图, 表示使用DINOV2提取到的图像特征,Ada表示AdaIN函数【 】。较小的CAS分数表示生成风格化图与内容图具有近似的内容信息,据此通过设置合适的阈值即可进行过滤。以上整个数据制作的流程如下左图: 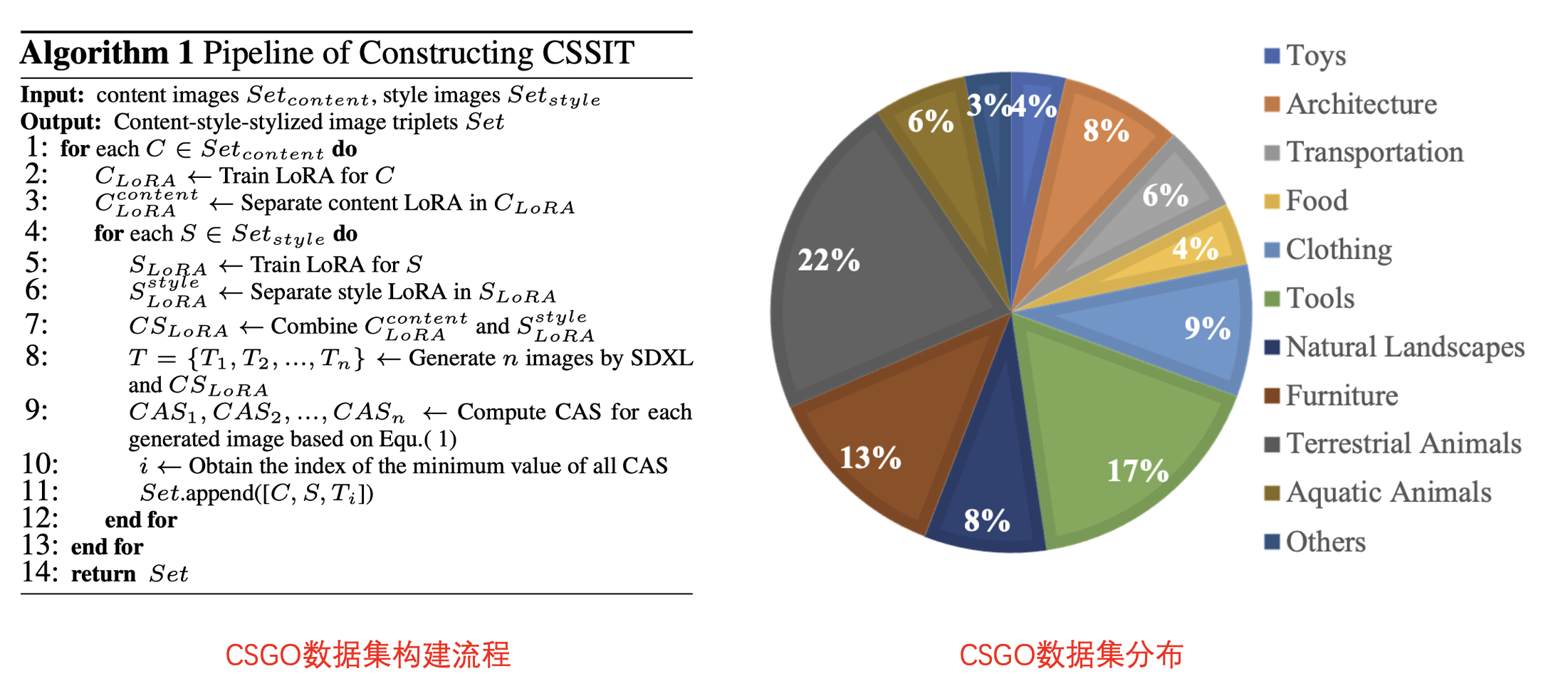
数据集构成:
内容图像:使用具有明显主体的图像作为内容图像,并补充了1000张线稿手绘图。最终有1.1万的内容图像。
风格图像:收集了5000张具有明显油画艺术风格的图像,又使用Midjourney生成了5000张艺术风格图像,共1万张风格图像。
训练三元组:使用上述介绍的数据构建流程,最终得到21万组三元组训练集合。测试集中内容图和风格图各248和206张。
模型架构:
整个模型架构包括内容控制和风格控制两个部分:
Content Control:为了保证尽可能避免内容特征的丢失,作者使用了两个技巧:
使用原Tile ControlNet做内容图像的特征提取然后注入到base模型中,Controlnet的权重冻住
谁用CLIP提取内容图像特征,然后再通过一个Content Projection层后,使用新cross-attention的方式注入到base模型的down-sampling blocks中。和IP-Adapter一样,Content Projection层和新cross-attention层是可训练的
StyleControl:
首先借鉴Perceiver Resampler structure设计了一个Style Projection来提取风格图的风格特征,然后将该特征通过两个不同的corss-attention分别注入到base模型的up-sampling blocks和Content Control用到的Tile ControlNet中。其中Style Projection和两个corss-attention是可学习的。
训练与推理:
训练:
使用标准的DDPM损失,其中C,S,P分别表示内容图、风格图、prompt。在训练过程中对C和S随机丢弃以确保在inference中能够使用classifier-free guidance。 推理:
配合classifier-free guidance 技术进行推理:
实验细节:
- 使用SDXL作为base模型、ViT-H作为image encoder。分辨率为512x512,learning rate 为1e-4,在8张H800(80GB)上,每张卡batch size=20 训练了共80000步。
- B-loRA的rank设置为64,训练1000步
- 对内容和风格都适用比较简单的表述,如训练中
'a [vcp]' 、'a [stp]'’分别表示对应的内容和风格。在推理时候就用'a [vcp] in [stv] style'的prompt。 - 文本、内容图、风格图的丢弃概率为0.15
- 评估指标:
- CSD score:评估风格相似度
- Content Alignment Score (CAS) :使用本文提出的CAS评估内容相似度
- 消融实验结论:
- Content Control的ControlNet极大提升了内容保持,同时风格特征注入到ControNet中也增加了风格的迁移稳定性
- Style Projection使用Perceiver Resampler structure提取风格特征比一般CNN(比如normal linear layer)更加有效
- Style Projection层特征的额token数越大,风格迁移效果越好
- ControlNet的注入权重越大内容保持越好,但是太大会导致风格信息减弱,一般设定在0.5
- CFG设定在10左右,太大导致风格过强内容损失严重,太小又会导致风格太弱
- 内容注入权重和风格注入权重都保持在1.0左右效果最好
应用:
- Image-Driven Style Transfer:只使用风格图作为指导,不提供prompt,对指定的内容图进行风格迁移
- Text-Driven Stylized Synthesis:提供风格图和内容prompt,生成与风格图的风格近似且符合prompt内容的图像
- Text editing-Driven Stylized Synthesis:同时提供风格图和prompt,对指定内容图进行风格迁移的同时,利用prompt进行微小的图像编辑(比如人脸添加眼镜、场景增加汽车等)。
总结
本篇博客介绍了几种基于Diffusion的风格迁移方法,相比之前的算法也极大提升了风格迁移的稳定性和效果,但是不同算法支持的功能还是有点区别的,下面做了简单的比较:
| 支持指定Content图 | 支持指定Style图 | |
|---|---|---|
| Style Aligned | ❌ | 可通过DDIM指定 |
| InstantStyle | ❌ | ✅ |
| InstantStyle-Plus | ✅ | ✅ |
| CSGO | ✅ | ✅ |