特征保持是Diffusion下一个重要的研究领域,其在给定同主体的一张或者多张图像的情况,生成该物体不同风格、位姿、朝向的图像,同时要保证原主体特征不变【比如粗粒度的类别、颜色,细粒度的纹理细节、人脸特征等】。

其实在之前博客《Diffusion学习6-生成可控性》提到的DreamBooth、LoRA、Textual Inversion等技术就是属于特征保持的算法,但是这类算法多多少少存在训练/推理耗时久、推理数据要求高等多个问题。而最近一些的特征保持算法则在训练速度、生成效果、数据要求上都得到了全方位的优化,所以这里单独开了一个篇章进行介绍。
IP-Adapter
《IP-Adapter:Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models 》
【主页】【论文】【代码】【HuggingFace】
写在前面:
- 该工作并非是第一个使用Image prompt去进行图像生成的工作,像之前的SD Image Variations 和 Stable unCLIP 都尝试使用Image来替换Text进行prompt 控制生成。但是这些工作有两个严重问题:
- 在原本T2I的模型上使用Image prompt进行finetune,削弱了原本大模型的文生图的能力,其次finetune整个模型也是成本比较大。
- 这些finetune好的模型通常是不可重复使用的,因为其改变了原始基座模型的权重,也就无法适配其他诸如ControlNet之类的控制插件。
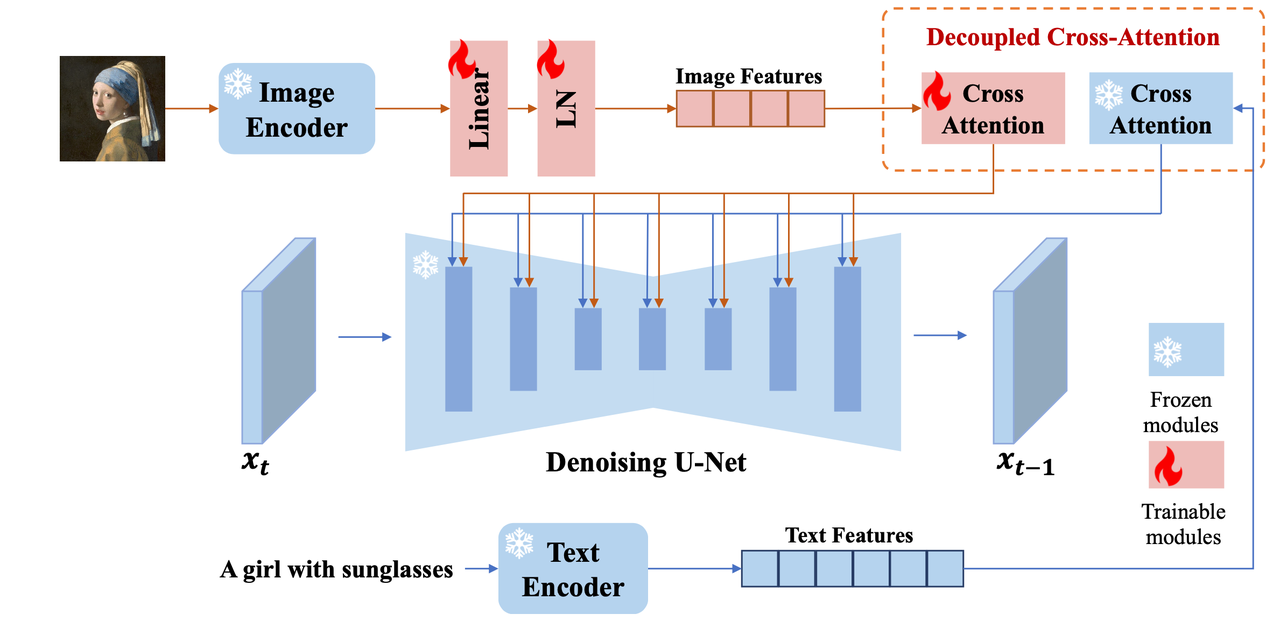
算法流程:图像相比文字具有更丰富的内容,也能更加精确地控制Diffusion的生成。该算法提出了一个解耦的Cross-Attention机制,将图像特征插入到Diffusion过程中进行控制生成,同时保持了原模型(包括UNet权重和Text Encoder权重)被冻住。该算法不损坏原本模型文生图的能力,并且配合Image Prompt达到多模态的图像生成效果;在仅需22M 参数量就达到了finetune整个网络的效果;也适配同一个基座模型的其他控制插件(比如ControlNet)。
算法细节:
Decoupled Cross-Attention : 在保留原本T2I模型权重(包含UNet和text encoder)冻住的情况下,在每个text embedding的cross-attention处为image embedding添加一个cross-attention,然后将两个cross-attention的输出相加后作为后续输入,公式化表达如下:
其中两个cross-attention共用一个来自上一层的UNet特征 ,作为query即 ,而原本text embedding的key和value分别为 【其中 就是text embedding】,然后image embedding的key和value为 【其中 就是image embedding】,并且其linear projection layers的权重 是从 作为初始化。 回顾上面公式,整个IP-Apader中要训练的参数只是每层Image Embedding下Cross-Attention的
和 。 模型训练:
使用和原SD相同的训练损失:
在text和image上都使用classifier-free guidance:
权重调节:
在text和image的cross-attention的相加时添加权重系数,用于调节image embedding的控制权重,在 时候就退化成了原本的T2I模型。
实验细节:
- 从LAION-2B和 COYO-700M收集了10million的text-image数据对作为训练数据
- 使用OpenCLIP ViT-H/14 作为Image Ecoder。
- 以SD1.5作为基础backbone,并在其内的16个cross-attention中添加了image cross-attention layer
- 使用DeepSpeed ZeRO-2 做了训练加速
- 8卡V100在batch_size=8情况下训练了一百万步数。
- 训练过程中对图像短边缩放到512并center crop 最终得到512x512大小图像
- 0.05 的概率同时丢弃text和image;同时各自再有0.05 的概率分别丢弃text和image
其他:
除了Decoupled Cross-Attention,本算法也尝试了一种simple adapter :即image embedding 和 text embedding拼接后送到UNet原先的cross-attention。但是该方案经过实验其效果会下降,而且其和原图像的一致性也下降了。
CLIP提取的Image Embedding代表的图像整体特征,而缺少了一些细节特征,作者也尝试了使用CLIP的倒数第二层特征作为Image Embedding。该方法不仅能够提升结果与原图的一致性,而且也能学到原图的结构特征,减少形变。
IP-Adapter-FaceID 和IP-Adapter-FaceID-Plus等后续任务,主要思想是将原生的CLIP Image Embedding换成/添加了Face ID embedding,来完成人脸ID保持的任务。
AnyDoor
《AnyDoor: Zero-shot Object-level Image Customization》
算法流程:
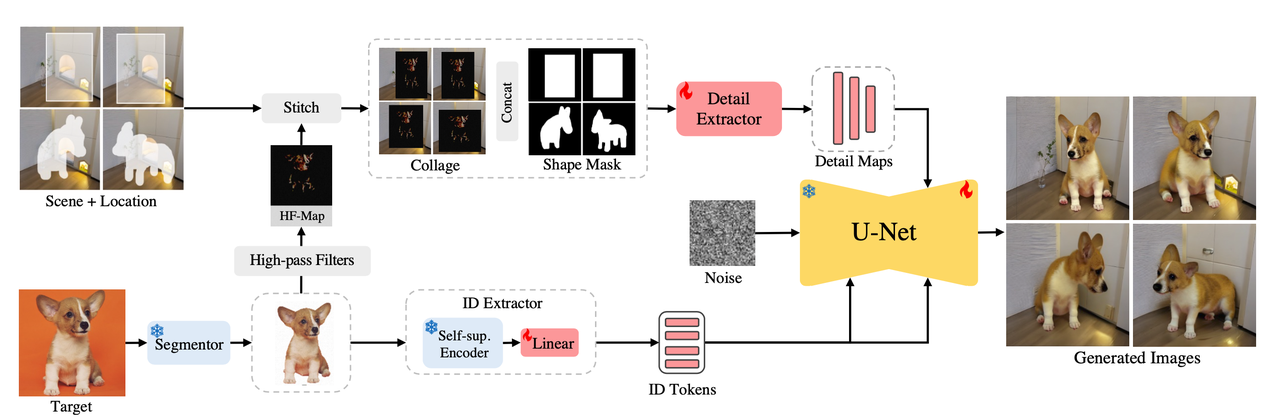
本文尝试将一个物体更自然地迁移到图像的另一个位置,用论文中的原话就是“object teleportation ”,实际上更像是图像融合的一种算法,只是在这种融合过程中主体的姿态、大小、形状等都有可能发生变化,但是ID特征必须保持不变,ID保持也是本算法的核心内容。
用户指定一张主体图和场景图,同时通过粗糙Mask(矩形框Mask)或者精细Mask (符合主体理论形状的Mask)来指定主体要插入的位置,然后生成一张该主体在指定位置的图像,该过程中通过专门提取主体的ID特征和高频信息来保证插入前后主体ID一致性。【好像只做了主体的插入和移动,并没考虑主体消除??】
算法细节:
该算法主要包括ID特征提取、细节特征提取、特征注入三个主要模块:
ID特征提取(Identity Feature Extraction):
之前的一些类似工作选择使用CLIP提取图像的identity 特征,但是这并不准确,因为CLIP在图文pair对上训练,其提取的多是语义级别的特征。所以为了更好提取图像里主体的identity 特征,算法进行了如下三步:
- 主体抠图,去除背景:防止背景对前景主体的特征影响。
- 使用自监督模型提取特征:使用DINOv2将图像编码成一个
大小的全局token和 大小的patch token特征,合并后使用 大小的特征作为最终图像中主体的ID tokens. - 特征注入: 使用一层简单的Linear层就能将上述的ID tkoens注入到预训练好的T2I-UNet网络中
细节特征提取(Detail Feature Extraction):
有下面几个点需要我们注意:
该模块通过Sobel边缘检测、腐蚀等传统操作来提取图像的高频特征,然后将该高频特征直接粘贴复制到要合成的场景图指定位置
上述合成的结果再拼接上指定的mask(矩形的或者符合物体shape的都行)后送到细节提取器中(Detail Extractor)提取特征供后面使用
细节提取器是一个类似ControlNet-Encoder结构的网络
作者有尝试过直接将原图主体替代高频特征进行合成,但是发现这样会导致最终生成的结果多样性太少。
拼接的mask有30%概率是box形式,有70%概率是符合物体形状的mas
特征注入(Feature Injection):
在通过上面两个模块分别获得ID tkoens和细节提取器输出的detail maps 后,则再分别通过以下的方式注入到SD网络中:
对于ID tokens:用ID tkoen替换原本SD的text embedding,通过cross-attention的方式注入到UNet中。所以也导致该方案没有prompt控制。
对于detail maps :就像ControlNet一样,直接将该特征加到原始UNet-Decoder对应的特征图上。
其他:
数据制作:
难点在怎么找到“同一个主体在不同场景下”的pair数据,旋转、缩放等简单的数据增强通常不自然。作者则以视频数据为出发点,寻找在“具有相同主体的不同视频帧”,具体步骤如下:
- 从视频中采样两帧,然后进行前景分割找到主体
- 将图片A中的主体crop出来当做Target Object
- 图片B直接就可以当做生成结果图作为整个diffusion的监督
- 对图片B,在主体位置进行主体消除得到场景图,当然此时location也是有的
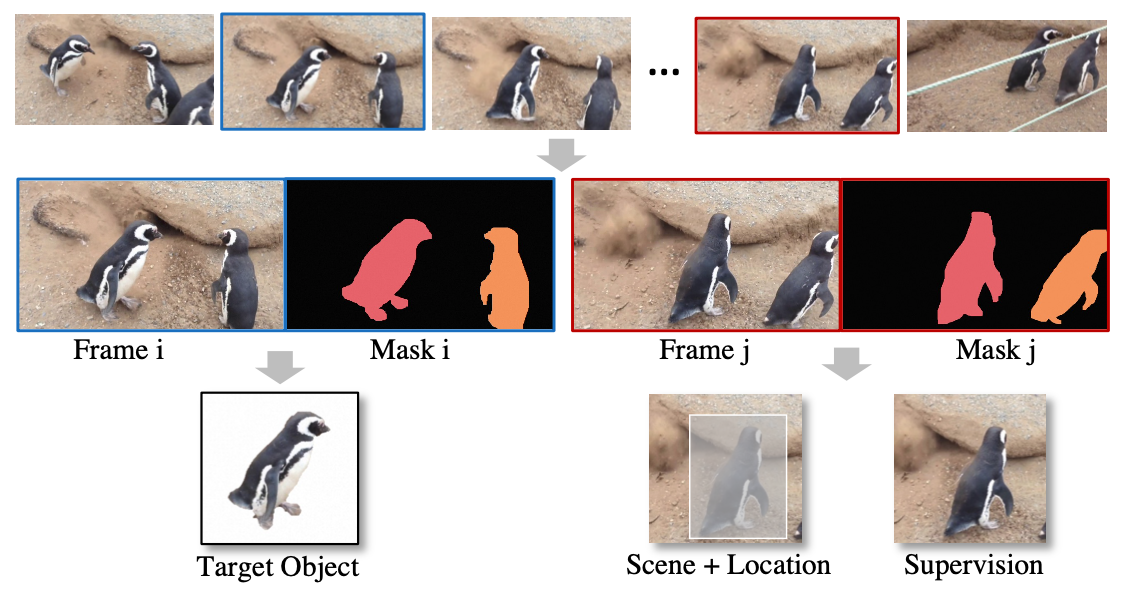
该通过视频采集训练数据的方式,好处是主体在不同的视频帧之间虽然是不同pose、大小等,但是ID是不变的。
Adaptive timestep sampling :
虽然视频数据极大扩充了训练集,但是视频数据多存在运动模糊等质量问题,所以其细节特征是不够的,但是好处是其整体特征(比如pose,shape)是没问题的。同时作者也联想到在Diffuson去噪过中,去噪前期(比如t在500~1000)多是生成粗粒度的特征,而在后期(比如t在0~500)多是生成细粒度的特征,借助此特点,作者则在使用视频数据训练时,提高t在500~1000采样的概率,而在使用图像数据时,则提高t在0~500采样的概率,这样就能充分使用量大但是质量一般的视频数据和量小但是质量高的图像数据。【这还是一个挺有意思的方案】
回顾下SD的训练流程:会随机从1~1000采样一个time step,对该time step下的noisy latent进行噪声预测并与原先该time step下的添加的噪声计算损失后再梯度下降更新权重
算法应用:
- Virtual try-on
- Object Moving、Swapping
- Shape Editing
- 配合ControlNet完成Human Pose Transfer
CustomNet
《CustomNet: Zero-Shot Object Customization with Variable-Viewpoints in Text-to-Image Diffusion Models》
算法流程:
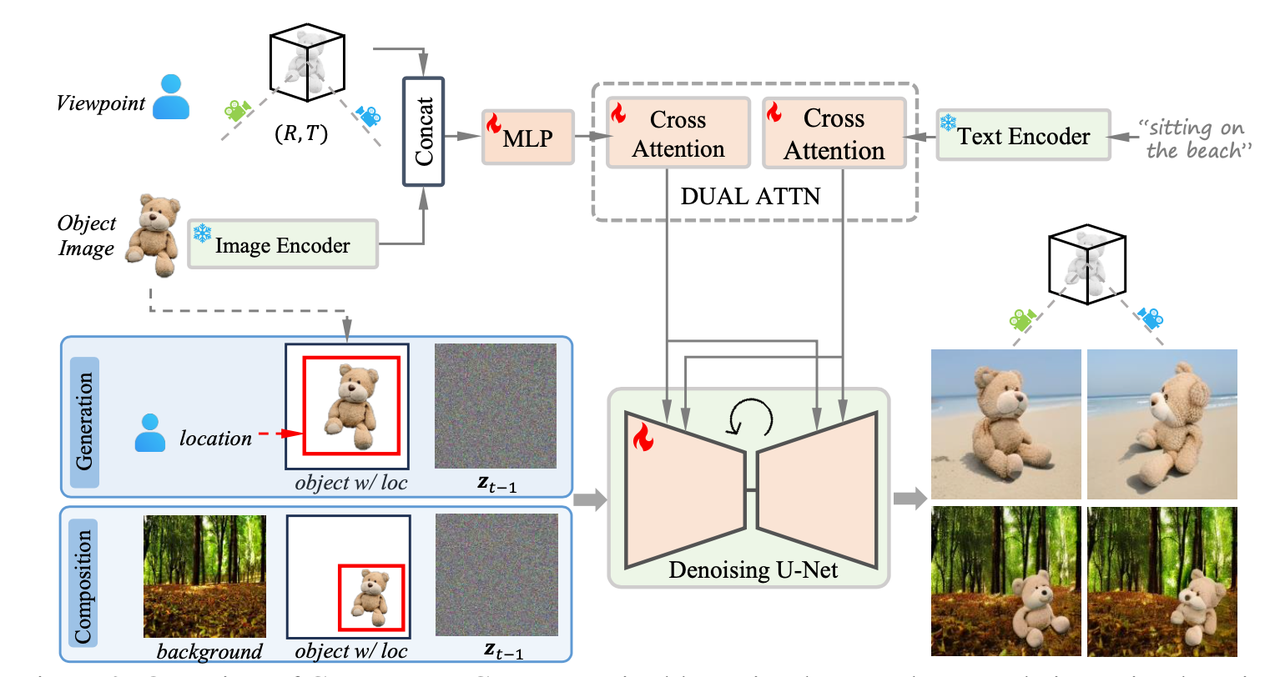
提出了一个Zero-Shot的ID保持算法,可以生成指定物体的图像,并且提供了视角控制、位置控制、文字背景控制、图像背景控制等多种可控生成的方式。该流程用公式化表达就是:
给定物体 ,并提供想要控制的参数(比如代表相机相对视角的旋转、变换参数[R,T],位置参数L,背景参数B),算法生成符合这些参数的新物体 ,并且新物体和原始物体于具有相同的ID特征。其中背景参数B可以通过文字提示,也可以是通过参考图。 算法细节:
下面就从4种控制方式来主要讲解这篇算法:
视角控制(Viewpoint Control)
对图像进行主体抠图,然后送到CLIP的image encoder得到包含物体高级语义信息的embedding(论文中称为object embedding),再与旋转变换参数[R,T]参数concatenate后送到一个MLP层【 该思路和Zero-1-to-3是一样的】,最后经过cross-attention注入到UNet中。
位置控制(Location Control)
在给定位置和大小参数[x,y,w,h]后,先将object image缩放到[w,h]大小然后将其左上角放置于无背景图片(比如纯白背景)的[x,y]位置上,然后concat上noisy latent
后得到 作为UNet的输入。 文字背景控制(Generation-based Background Control)
用类似IP-Adapter的方式,将拼接上旋转变换参数[R,T]参数的object embedding与background text embedding通过两个独立的cross-attention注入到UNet中:
其中 来自UNet特征,$ K_o V_o K_b V_b$来自text embedding。同时为了防止背景text与view耦合,会有一定概率随机将background text embedding丢弃。 图像背景控制(Composition-based Background Control)
直接将背景图片与位置控制、noisy latent通道维度拼接后得到
作为UNet的输入。
数据构造:
为了构造训练数据,需要以下pair对【object图像
,生成结果图像 ,视角参数[R,T],位置信息L,背景信息B(来自文本描述或背景图)】。作者首先尝试了以下步骤: - 先从3D数据集下载3D模型,并在不同的视角[R,T]下渲染该视角下的图像
- 上述视角图像一般是纯白背景的,所以要用预先收集好的背景图像,对其进行背景填充融合
- 使用BLIP2获得背景的文本描述
- 但是上述步骤的问题在于,最后背景和视角图像融合肯定存在不自然的情况,所以作者逆向思考,重新设计了数据收集流程:
- 直接使用OpenImages数据集,有背景有主体作为最终生成结果
- 使用SAM分割得到图像中的主体
- 使用Zero-1-to-3对分割的主体生成新视角作为object image
实验细节:
- 使用viewpoint-conditioned diffusion模型Zero-1-to-3作为基座模型进行finetune。
- 作者使用上述两个数据构造流程,构造最终数据集有(250+500)K的图像
- batch_size=96,在8卡32G的V100上训练6天
- 几个消融实验结论:
- viewpoint控制能够保证视角多样性,同时避免出现那种“粘贴复制”的违和感
- 从多视角数据和Zero-1-to-3模型权重进行finetune,有助于提升视角一致性
- 与Object Image的拼接,有助于保持原图像的纹理细节
- OpenImage数据有助于提升结果的自然感避免出现前后景的违和
- Object embedding和text embedding使用各自的cross-attention有助于提升生成质量。
PhotoMaker
《PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding》
【主页】【论文】【代码】【HuggingFace】
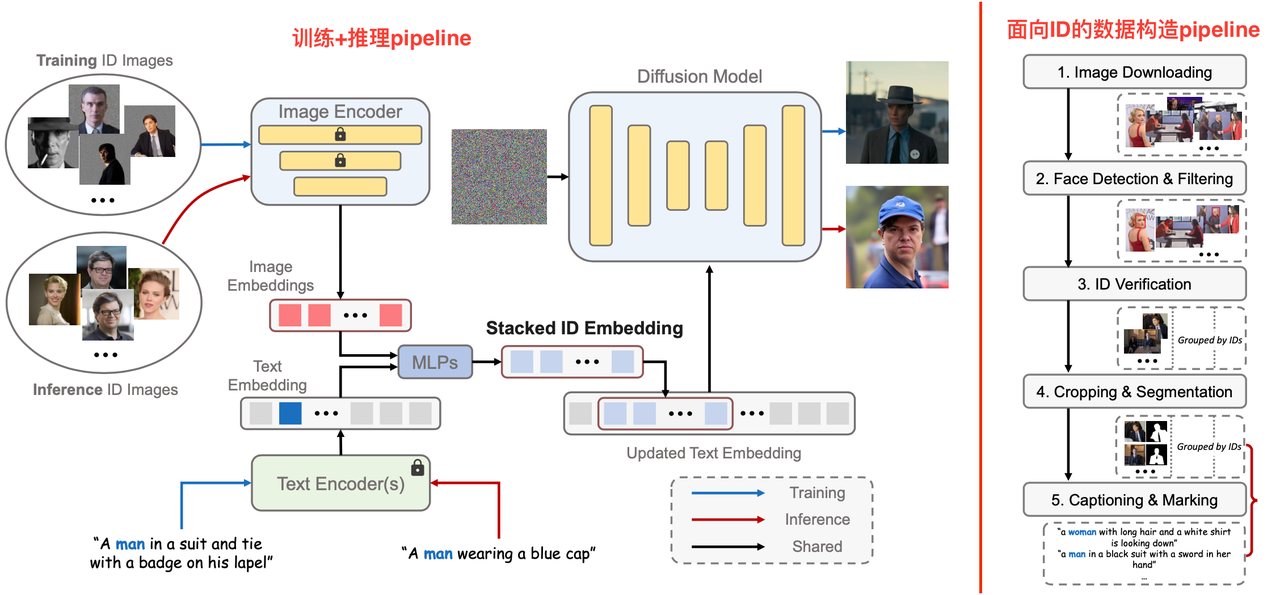
算法流程:提出了一个可以使用多张ID图像进行人脸生成的方法。对多个ID图像提取特征得到stacked ID embedding提升了最终人脸保真度。同时支持多ID混合生成新人物ID【即Identity mixing】。该方法同时提出了一个面向ID的数据构造流程,对同一个ID可以获取多张图像,同时保证姿态、表情的多样性。
之前ID保持方法存在的一些问题:
- 训练时target image和input ID image是同一张,这会导致模型可能会记住ID以外的人脸特征(如表情、姿态等),从而导致编辑性比较差。
- 仅依赖单个ID图像进行定制化生成,使得模型难以准确捕捉要生成的ID特征,从而导致ID保真度不及预期。
算法细节:
算法总体还是沿用了之前Diffusion做ID生成的思路:即将ID embedding通过cross-attention注入到UNet,但是提出了多ID融合的trick:
Stacked ID Embedding :
人脸特征提取:同一个人像ID有N张图像
,经过image Encoder得到 个ID embedding特征。此外text embedding的尺寸为 。 特征堆叠:
该步借鉴DreamBooth中class word的想法,使用定制化words来加强图像中的ID特征,具体做法是:
每个人脸图像有对应的caption,同时caption中手动加入类别单词(比如区分男女的"man"或者"woman"),
将上述定制化的caption通过text encoder后得到text embedding,按照类别单词在原定制化caption中的位置,提取texe embedding中位置下的tkoen。
将步骤2的得到的token和ID embedding送到一个两层的MLP中进行融合,得到带有定制类别的ID embedding
。 对这N个embedding在长度维度拼接后得到stacked ID embedding :
。
人脸信息注入:
将stacked ID embedding放回text embedding,具体放在“特征堆叠”的步骤2中找到的位置。
放回text embedding后,维度则从
更新到了 。 通过cross-attention的方式将上述更新后的text embedding注入到UNet中,其中key和value是text embedding映射后的特征,query是UNet的特征。
ID-Oriented Human Data Construction
当前大多人脸数据集是不包含ID信息的,即一张图像是输入哪个ID是不知道的,所以为了满足本算法对同一个ID需要多个人脸图像的需求,作者构建了一个面向ID的人像图片数据收集Pipeline,该pipeline的具体过程如下:
Image downloading:从VoxCeleb1和VGGFace2数据集获取一系列知名人物的姓名,然后使用搜索引擎查询并下载每个人的图像(每个ID约100张),并筛选掉短边小于512的低分辨率图像。
Face detection and filtering:使用人脸定位模型Retinaface检测图像中的人脸框,并过滤掉小于256x256的人脸
ID verification:一张图像可能存在多张人脸,所以crop图像中的每个人脸并送到ArcFace模型中提取人脸embedding ,然后计算每个人脸embedding与其他embedding的L2相似度并求和作为该人脸的分数,选择分数最高的人脸框用于代表该ID,然后计算代表ID与其他人脸框的相似度分数并计算分数的方差,最终以8倍方差过滤掉那些大概率不属于该ID的人脸框。
Cropping and segmentation :对人脸图像进行剪裁保证人脸区域占比在10%以上,然后使用Mask2Former进行分割并mask掉不相关的背景和ID
Captioning and marking:因为本算法需要使用class word(如“man”、"woman"),所以使用BLIP2的随机模式进行caption直到出现class word。同时还使用了CLIP score等方式解决出现多class word的情况。
实验细节:
- 使用SDXL作为backbone,使用CLIP ViT-L/14 提取人脸特征
,同时在attention层训练了LoRA来提升人脸定制化的效果。 - 在8张A100上,batch_size=48训练了两周
- 训练过程中每个人使用1~4张该ID图像计算stacked ID embedding
- cfg有10%的概率置空prompt
- 使用50%概率的masked diffusion loss提升ID
- 算法将抠好的人像图送到CLIP提取人脸特征,但是因为CLIP是在背景相对复杂的自然图像上训练完成的,所以为了保证对masked人像图也能提取到比较好的特征,则对CLIP的后几层transformer层进行finetune.
- 推理过程中DDIM步数为50,cfg=5.0
- 推理使用bfloat16和float16在V100上耗时分别为单图1min和4s,最小运行现存11G。
- 使用SDXL作为backbone,使用CLIP ViT-L/14 提取人脸特征
消融实验:
- ID图像的数量:多张ID图会提升ID质量,尤其在从1张提升到2张的时候提升明显。
- ID embeddings的融合方式:探索了3种融合方式:平均、通过一个Linear层融合、本文的concat。实验证明最后一种方法在保证编辑多样性的情况下能提升ID质量
- 训练过程中使用多embedding:本文使用多张和target图不同的ID图像作为引导,并配合target图的caption,用于生成target图。消融实验探索了额外两种方式:1. 用一张图像(可以和GT target图像不同)提取embedding。2.将GT target图像图像也作为input ID 图。实验证明方法1的ID保持不好;方法2可能会记住target图中ID之外不相关的特征,,影响生成质量。
应用:
- ID保持的风格化生成:指定ID,通过prompt控制风格、背景等
- 人脸老照片艺术化
- 改变人脸性别和年龄:对ID图像使用不同的class word进行描述,比如男ID使用"woman"的class word
- 多ID人脸融合:训练时候对同一个ID的多张图像作为batch进行训练,但是在推理的时候可以用不同人脸ID的图像作为输入达到多ID混合的效果(Identity mixing )。
补充✅ :该团队在2024.7.22 推出了PhotoMakerV2版本,该版本使用更新的训练策略、更多人像数据、更强的ID encoder,提升了单图的ID保持能力,同时也极大提升了亚洲人脸的ID效果。
InstantID
《InstantID : Zero-shot Identity-Preserving Generation in Seconds》
【主页】【论文】【代码】【HuggingFace】
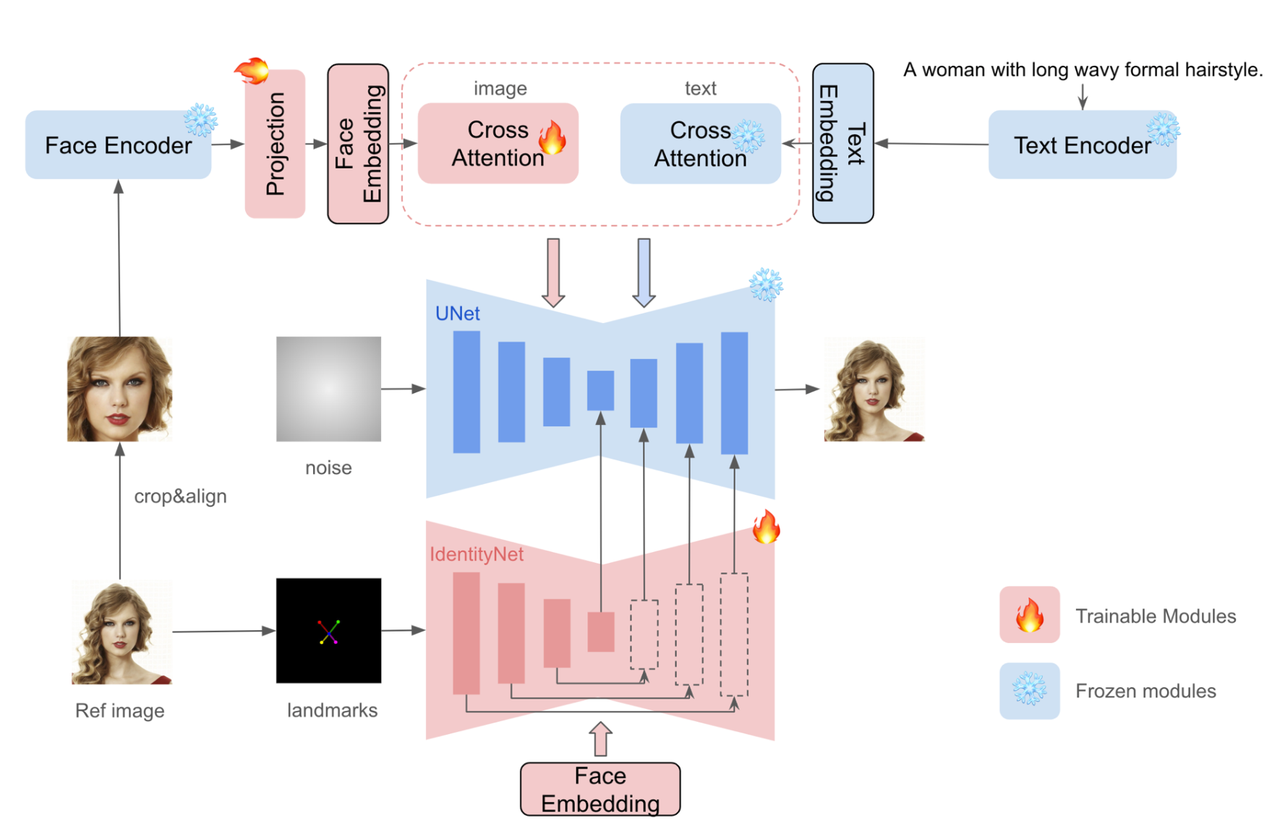
算法流程:该算法提供了一种zero-shot的ID保持算法,具有即插即用、Tuning-free的特点。其总体思路和IP-Adapter比较接近,但是使用了专门的Face Encoder提取cropped人脸图像,同时使用了人脸landmark作为控制条件的ControlNet来提升生成结果。
写在前面:
本文属于ID Preserving Image Generation类的算法,是专注做人像的ID保持,其可以看做Subject-driven Image Generation【代表算法AnyDoor和IP-Adapter】的一个细分类别。论文首先回顾了之前两种在T2I生成过程中,保证生成图像具有指定Subject或Style的方式:
- 对整个T2I模型进行Finetune:【代表算法:DreamBooth、Textual Inversion、LoRA】对整个或部分模型权重重新训练,以将模型输出映射到reference images。该类算法针对每个ID需要重新训练模型导致灵活性比较低,并且每次甚至需要多张图片作为数据集。
- 额外训练Adapter:【代表算法:IP-Adapter、AnyDoor】冻住原T2I基模的权重额外训练一个轻量级插件用于提取图像特征,通过cross-attention的方式注入到T2I模型中。该类算法多使用CLIP提取特征,导致无法提取更加细粒度的特征从而最终结果也会丢失很多细节(比如人脸特征)。
算法细节:
整个算法包含ID embedding 、Image Adapter 、IdentityNet 三个部分:
ID Embedding:之前的人脸保持算法使用CLIP来提取图像特征,不过受限于CLIP的训练和数据集,该类特征无法提供像人脸ID一样更加高级和细粒度的信息。所以本文使用人脸识别、人脸重建等专门的人脸任务中的pre-trained模型用来提取人脸特征。
Image Adapter:使用类似IP-Adapter中的decoupled cross-attention方式,将提取到的ID Embedding注入到UNet中
IdentityNet:作者认为仅仅使用上述IP-Adapter的方式将人脸信息注入到网络中,是仅仅不够的,这种image prompt通常会削弱text prompt的控制力度。于是作者额外使用了ControlNet进行生成控制,但是作者做了两点改动:
更换控制输入信号:使用人脸的5点landmarks【眼镜2点+鼻子1点+嘴巴2点】作为控制输入,有两点好处:a).该算法从real-world收集人脸信息,这类人脸图像通常是占据画面较小一部分,无法获取其他更加精细的人脸特征。b).避免其他过多冗余信息【如脸型、嘴巴张合等】对于生成过程的干扰,而更加关注人脸高级id信息。
将text prompt换成ID embedding:让网络更加关注人脸ID信息
实验细节:
- 训练损失:
其中
是text prompt, 是与任务相关的图像控制输入,本文则是含有人脸的图像 IdentityNet输入的人脸图像landmarks是不需要crop的
分别调节Image Adapter和IdentityNet的权重,提升编辑效果灵活性与多样性。
网络结构使用SDXL-1.0 作为backbone并冻住其权重,仅训练Image Adapter和IdentityNet权重
在48张H800(80G)上训练,batch_size=2
数据集使用LAION-Face【包含50M张image-text数据对】和网络收集的10M张高质量人脸图像并用BLIP2进行打标
使用antelopev2进行人脸检测和特征提取
可与现有的ControlNet模型配合使用
该方法在仅使用一张人脸图像时就能取得比较好的ID保持了,此外使用多张同ID人脸能够进一步提升ID保持
通过对比试验,作者发现IP-Adapter-FaceID 和IP-Adapter-FaceID-Plus虽然也是使用ID Embedding,但是会影响text prompt的控制最终同时图像在风格、背景等维度上的多样性减少。
下游应用:
- Novel View Synthesis under any given pose
- Identity interpolation between different characters
- Multi-identity synthesis with regional control.
- 训练损失:
PuLID
《PuLID: Pure and Lightning ID Customization via Contrastive Alignment》
【论文】【代码】【HuggingFace】
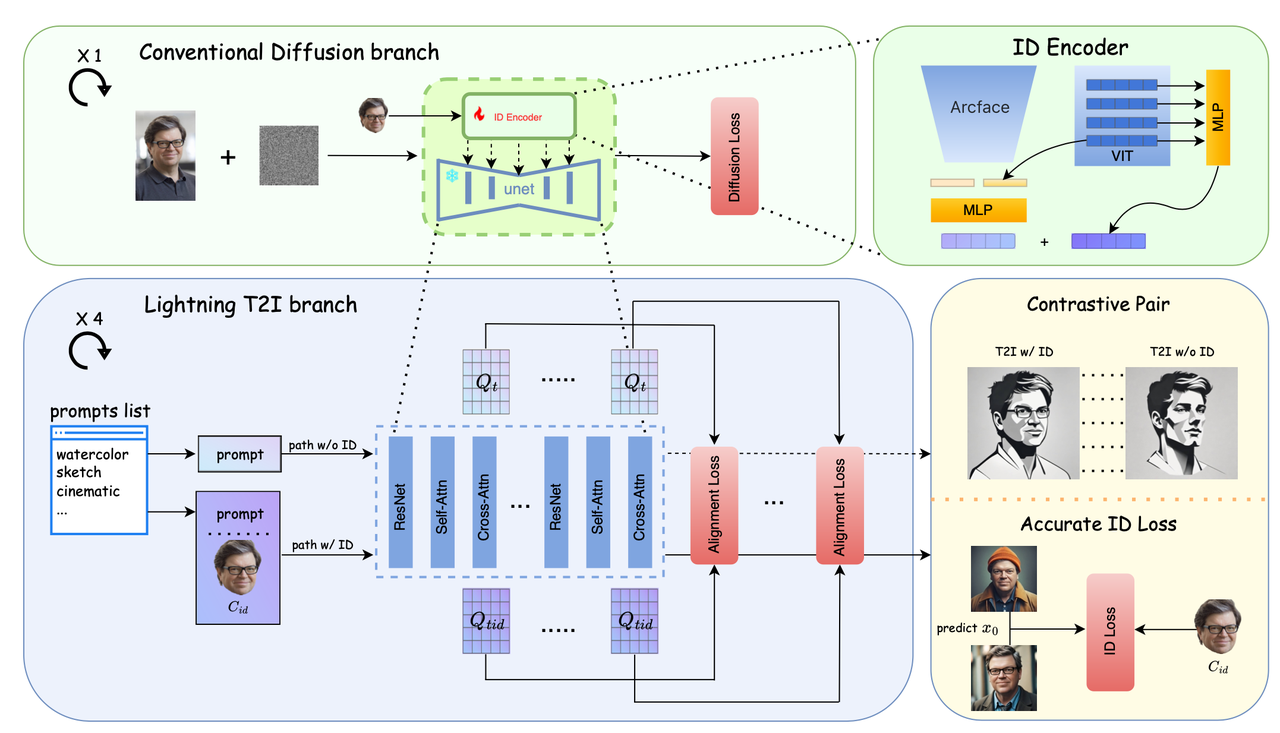
算法流程:本文提出了一种干净的ID生成算法,保证在使用ID图像引导T2I生成时不会破坏原本T2I的风格、布局、背景,尽可能仅仅修改图像中的人脸。本算法在原本Diffusion的基础上提出了Contrastive Alignment损失以实现这种干净的ID生成同时也提升了prompt的可控编辑性(生成结果不会偏离原本只用prompt的结果)。此外也提出了使用快速生成算法(SDXL-Lightning)以恢复到图像层面以计算准确的ID损失,进一步提升最终ID生成的保真度。
写在前面:诸如IP-Adapter-FaceID、PhotoMaker、InstantID等算法使用插件的形式将ID信息注入到T2I网络中,它们虽然不用像DreamBooth、LoRAG一样为每个ID训练一个模型,但是这类算法都存在以下两个问题:
- 会破坏原T2I的生成结果:即理想的ID生成应该对原本T2I生成的图像只会修改ID相关的内容(比如头发、人脸、性别、年龄等),而不会修改背景、风格、光照等ID无关的元素。这类算法虽然保证了ID相似度,但是ID之外的元素也会发生很大的改变。此外也会进一步导致很多生成内容就不符合原prompt控制条件了。
- 缺少显式的ID约束:直接将ID embedding注入到Diffusion 的去噪过程,但是损失上仍然使用标准的Diffusion损失(即最小化预测噪声与真实噪声的MSE),没有明确ID相关的优化损失会多少会降低对最终生成的ID保真度。
算法细节:
作者先提了几个问题:
问:为什么诸如IP-Adapter、InstantID等算法会破坏原T2I的生成结果?
答:因为ID特征从原人脸的cropped图像进行提取并注入到UNet中,其会和prompt一起指导Denoise过程以精确预测噪声并重构原图像,这就会导致那些与ID不相关的图像信息也会被强制重构。最终就破坏了原本没有ID信息时候的T2I结果。
问:为什么生成结果可能和prompt不匹配?导致prompt的控制力度下降
答:这是因为训练和测试的数据是有差异的,具体地:在训练时使用成对的【prompt,ID图像】作为训练数据(其中ID图像是符合prompt描述的,且ID图像既作为ID控制信息,也作为GT来监督denoise过程),这就导致在测试的时候如果prompt和ID图像冲突(比如ID是男的,prompt要求生成女的)那么预测结果也是会偏向于重构男的,就导致prompt的控制力度下降。
使用Contrastive Alignment进行干净的ID插入
为了保证ID插入不会影响原T2I模型的效果,作者使用SDXL-Lighting为基础设计了Lighting T2I分支用 于Contrastive Alignment,具体做法是该SDXL-Lighting分支分别接收两种输入条件:“无ID图像,仅有prompt”和“有ID图像和prompt”,分别计算这两种输入下UNet的cross-attention特征记作
和 【注意这里的特征是在所有timesteps下所有layers的特征】,然后计算两种ID损失: semantic alignment loss
该损失的出发点是:如果ID插入没有影响原T2I模型(只有prompt控制时)的输出,那么T2I模型对于文本prompt的响应应该是不变的。
所以作者使用了一种类似attention的方式去计算该损失,具体做法是:将prompt embedding作为K而UNet特征作为Q和V,==计算的cross-attention值就代表UNet特征对于prompt的响应==。然后为了保证在ID插入前后响应是不变的,就可以如下的损失进行约束:
简单回顾下标准Attention公式是:
layout alignment loss
此外为了保证layout在ID插入前后不受影响,作者直接使用两个UNet特征的MSE损失进行优化:
从下图可以看出,baseline在没有两种损失的情况下虽然ID是和ID图像相同,但是对于prompt的响应和布局相比较原T2I结果都发生很大变化。而添加semantic alignment loss后对于prompt响应正确了(不仅有人也有自行车,风格也是sketh),在添加layout alignment loss后布局也和原T2I相同了(人骑在自行车上了)。
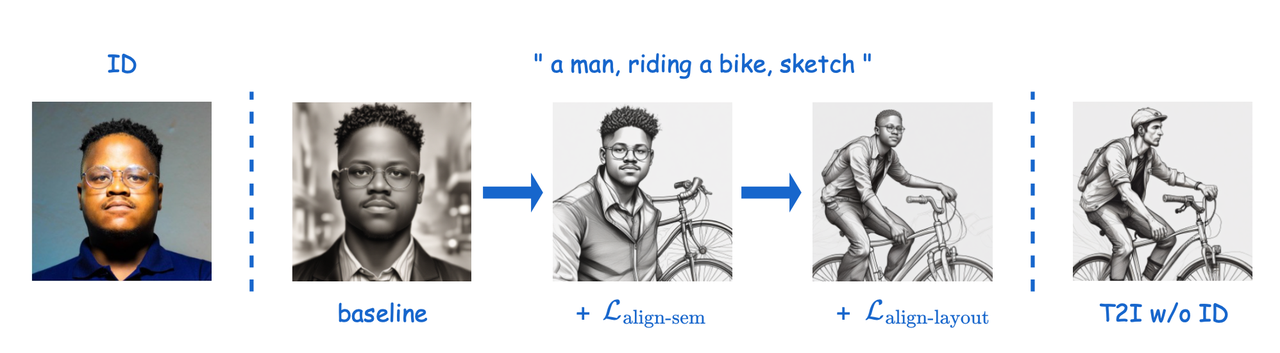
使用ID损失显式约束ID保真度
之前方案弊端:之前诸如IP-Adapter、InstantID等很多工作提升ID保真度基本都是使用更好的ID Encoder,但是仍然使用标准的Diffusion损失。而本文则提出使用之前在GAN-base方法中常用的ID损失来显示保证ID效果。
难点:但是有个问题是Diffusion网络是不断在迭代过程中预测噪声并在最后去噪后才能得到干净的输出图像。
之前方案尝试:之前Diffface、Photoverse等使用一步或者两步将demoise过程中的noisy image变成“干净”人脸图像,然后在图像层面计算ID损失。但是这类算出来的人脸图像仍然是含有一定噪声的,所以计算的ID损失也是没那么准确。
本文方案:该算法使用SDXL-Lightning快速(仅需要4步采样)从纯噪声获得人脸图像以计算ID损失,具体ID损失计算如下:
其中 表示id图像、 表示纯噪声、 表示prompt【这里设定为“portrait, color, cinematic ”】, 表示人脸识别backbone、 人脸embedding损失
实验细节:
- 使用ArcFace和CLIP image encoder作为ID Encoder同时提取图像的ID特征,具体地:将这两个特征的最后一层拼接后过一个MLP得到长度为5的token作为global ID 特征;使用CLIP的多层特征再过一遍MLP得到长度也为5的token作为local ID特征。然后这些特征使用IP-Adapter的方式通过额外的cross-attention注入到UNet中。
- 使用Arcface-50计算人脸损失。
- 损失包括【标准diffusion损失、alignment损失、ID损失】进行训练。要更新优化的参数为新添加的MLP层、ID注入与cross-attentio相关的映射层。
- 使用SDXL作为backbone和4步推理的SDXL-Lightning【分辨率用768以减小内存】作为Lightning分支
- 构建了1.5M的高质量人脸图像,并使用BLIP-2进行caption
- 训练包括三个阶段:
- 先使用Diffusion损失训练
- 然后使用ID损失和Diffusion损失训练
- 最后添加Alignment损失使用全部损失训练
- 推理阶段全使用4步的SDXL-Lightning,配合DPM++ 2M采样器,cfg=1.2
其他:
- 应用:风格迁移、多IP融合、属性编辑等
RealCustom
《RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization》
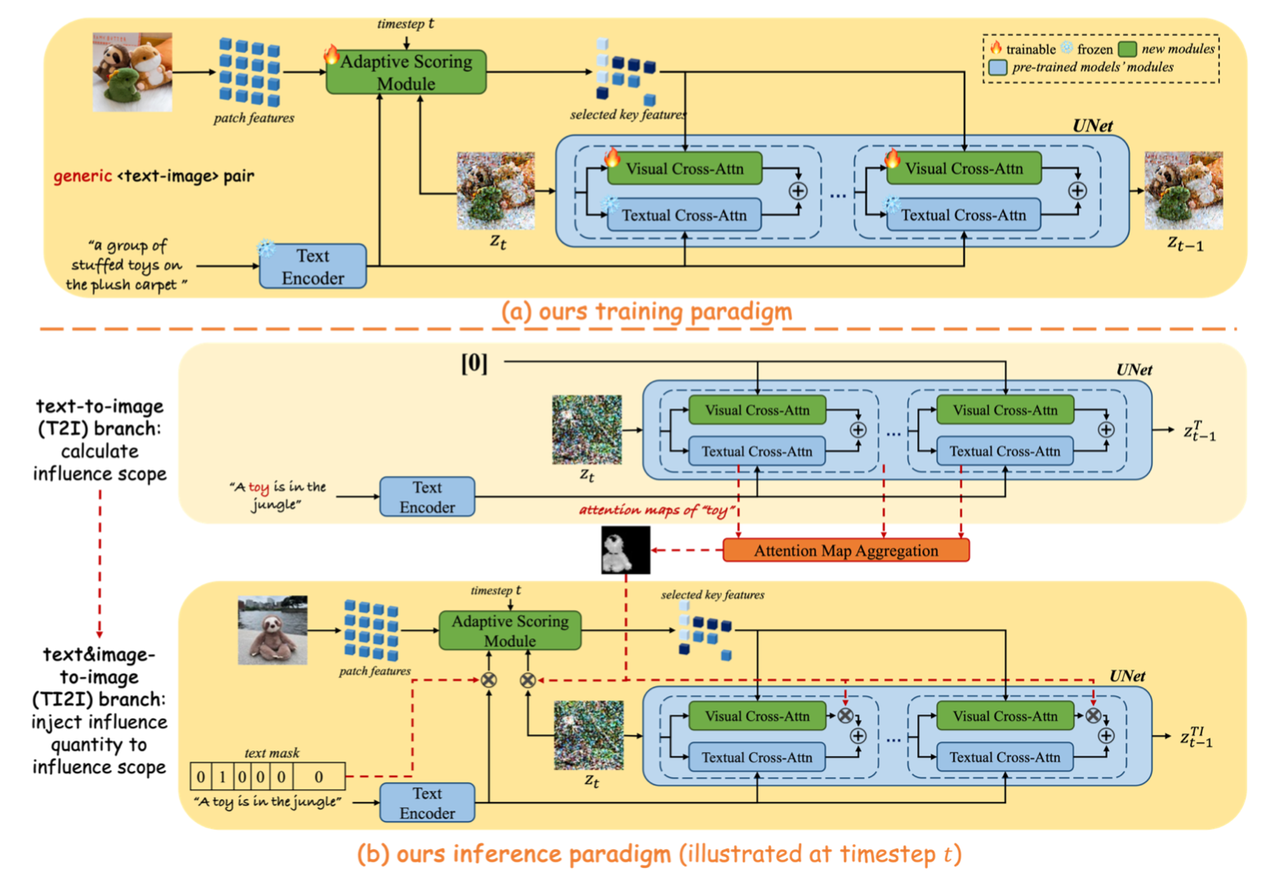
算法流程:本算法提出了一个新颖的“train-inference”解耦框架,用于提升图像生成时特征保持的相似性和可控性。具体地,在训练中提出了“Adaptive Scoring Module”模块用于筛选出给定subject图像中的部分特征,并通过类似IP-Adapter的的方式注入到UNet,而在推理过程中则提取传统T2I过程中subject相关的attention map,借此对Adaptive Scoring Module的输入和输出做掩膜进一步提取与subject有关的特征用于提升最终生成结果的相似性和可控性。
写在前面:
- 论文提出特征保持算法应该遵守两个原则:
- 相似度高:生成图像中的主体应该和原给定的主体具有较高的相似度。
- 可控性高:与主体无关的其他内容应该遵守prompt的描述。
- dual-optimum paradox(即双重最优悖论):之前的特征保持算法无法同时优化相似性和可控性。作者认为造成这种问题的原因在于“pseudo-word”【即类似DreamBooth和Textural Inversion用一个假词来代表某个主体】与prompt其他内容产生了耦合。具体地,带有“pseudo-word”的完整prompt通过cross-attention注入到网络中,每个区域的特征受到prompt中每个单词的影响是有权重的,增加相似度(即加大“pseudo-word”词的权重)就必然会相对性地减弱prompt中其他单词的权重,反之亦然。
- 论文提出特征保持算法应该遵守两个原则:
算法细节:
为了解决上面的问题,本算法提出了一个新颖的“train-inference”解耦框架同时提升相似性和可控性:
在训练阶段:
数据层面就是用最一般的【image,text】数据对进行训练。训练策略方面其实就是一种类似IP-Adapter的方式,使用CLIP提取图像的特征然后通过attention的方式将图像特征注入到UNet中(但并非将所有特征都注入,这也是本算法的创新点)。
本算法提出了“adaptive scoring module”的新模块,该模块的作用则是选择性地将CLIP image emeddingb注入到UNet的attention中。具体做法是:比如通过CLIP提取到的text condition和image condition特征分别为
和 ,其中 分别表示text和image 特征的数量和维度。然后通过“adaptive scoring module”对 进行“精简”后输出selected image key feature ,其中 。最后再将selected image key feature通过和IP_Adapter一样的方式注入到UNet中: 其中 表示从selected image key feature进一步映射得到的key和value用于cross-attention。 整个训练过程中只有“adaptive scoring module”(后面重点将介绍)和每个attention block中新增的projection 层的 是训练的。 Adaptive Scoring Module
Diffusion在不同的time step关注不同细粒度的特征,比如从全局结构特征到局部纹理细节特征。所以该算法认为额外提供的image 特征(比如代表主体的图像)也应该在不同去噪step发挥不同程度的影响。 作者认为在训练阶段,使用同一张图像作为image condition特征和noisy image,而在推理阶段,noisy image和image condition通常不是同一张图像,这个gap也会最终导致相似性和可控性都会下降。受此启发,作者则提出了Adaptive Scoring Module,该模块接受4个输入【text特征
,image特征 ,timestep ,noisy latent 】并输出“精简选择”后的image特征 ,其中 。具体结构如下:
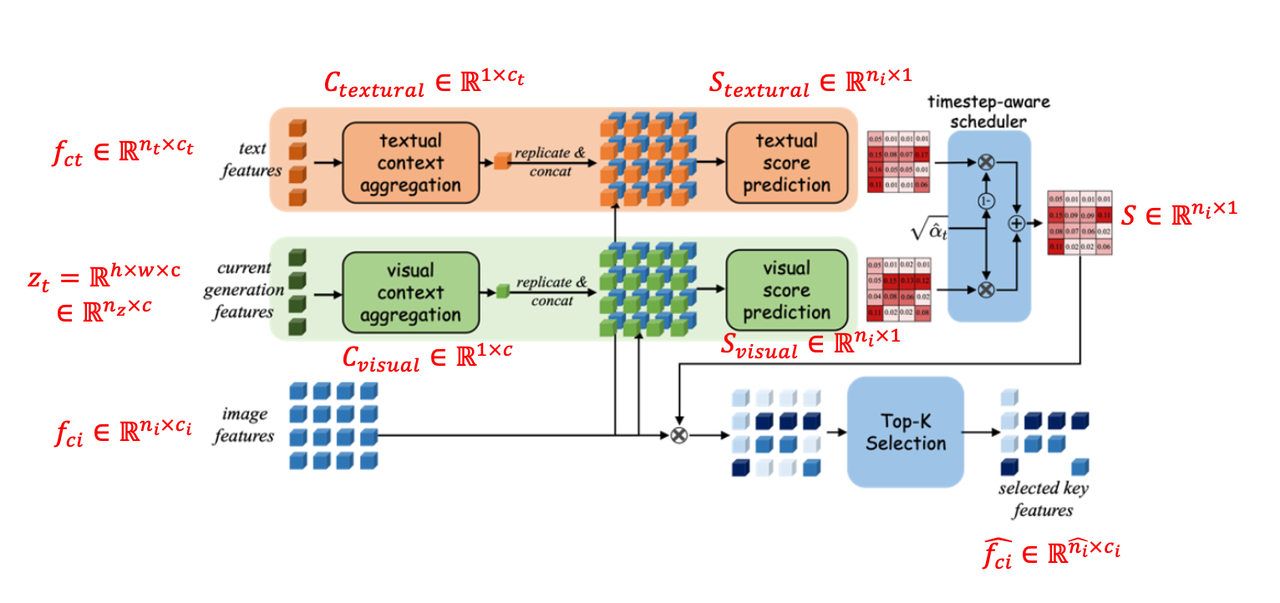
整个具体的过程如下:
text特征
和noisy latent 通过以下公式得到各自的aggregated特征: 其中 是映射权重,Softmax在number维度操作。 将上面的两个aggregated特征在空间维度repeat并与image特征
拼接后分别经过两个2层的MLP得到各自的预测分数 将两个分数经过下面的线性插值再经过一个softmax得到最终的分数
: 将最终分数与原image特征
相乘,计算Top-K选择前 概率的特征作为最终的selected image key feature 。其中 在[0.3, 1.0]范围均匀采样。
在推理阶段:
提出“adaptive mask guidance strategy”,通过不断迭代更新给定subject的影响范围和数量来缩小真实单词的范围。【比如pipeline图中的"toy"就是real word,而真正要插入的主体则是"the unique brown sloth toy"】。该阶段包含两个分支:
- Text-to-Image (T2I) 分支:其接受的视觉条件为空,其实就是传统的文生图。
- Text&Image-to-Image (TI2I)分支:其接受的视觉条件即为给定的subject图像
两个分支通过本算法提出“adaptive mask guidance strategy”进行连接,具体步骤如下:
在给定的denoise step
下的,noisy latent 经过T2I分支得到 提取上述过程中所有corss attention层中对于主体的attention map【如流程图中 对“toy”单词的attention map】并全部缩放同一个尺寸(比如SD中latent的最大尺寸
)构成aggregated attention map 使用Top-K按照
的比例保留前 个区域,而剩下的则被设置为0,此时得到selected cross-attention map 对selected cross-attention map做归一化:
上述归一化后的selected cross-attention map将被用在两个地方:
- 在adaptive scoring module之前对
进行mask - 在adaptive scoring module之后,对visual cross attention进行mask:
- 在adaptive scoring module之前对
经过以上步骤后得到TI2I分支的输出结果,然后使用CFG得到最终 t-1步的noisy latent:
其中 表示无unconditional denoised output【即无text也无image控制】
实验细节:
- 在SD上并使用Laion-5B的子集(使用美学评分过滤后)进行训练
- 使用16张A100训练16万步
- cfg的两个系数
,top-k的两个概率 - 评估指标:
- Similarity:使用SAM分割出参考图片和生成图片中的主体,并计算CLIP-Image embedding的cosine相似度
- Controllability:计算prompt和图像的clip embedding的cosine相似度
其他:文中一直提到的一个术语“gradually narrowing the real words into the given subjects”用下图表示:
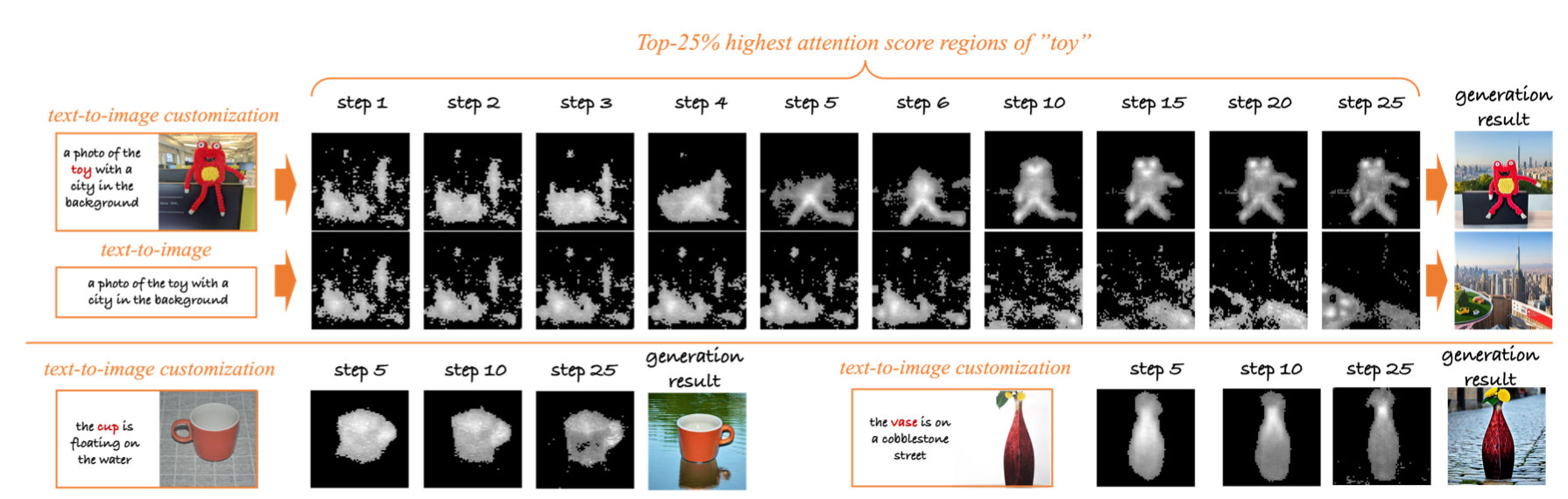
即在给定描述语句(带有subject)和subject图像时,该算法在推理过程中会逐渐将对subject单词(比如上述的"toy ")的attention map收敛到subject的形状(比如上面红色玩具)并在最终生成给定的subject。
✅2025.02.21补充
Diptych Prompting
《Large-Scale Text-to-Image Model with Inpainting is a Zero-Shot Subject-Driven Image Generator》
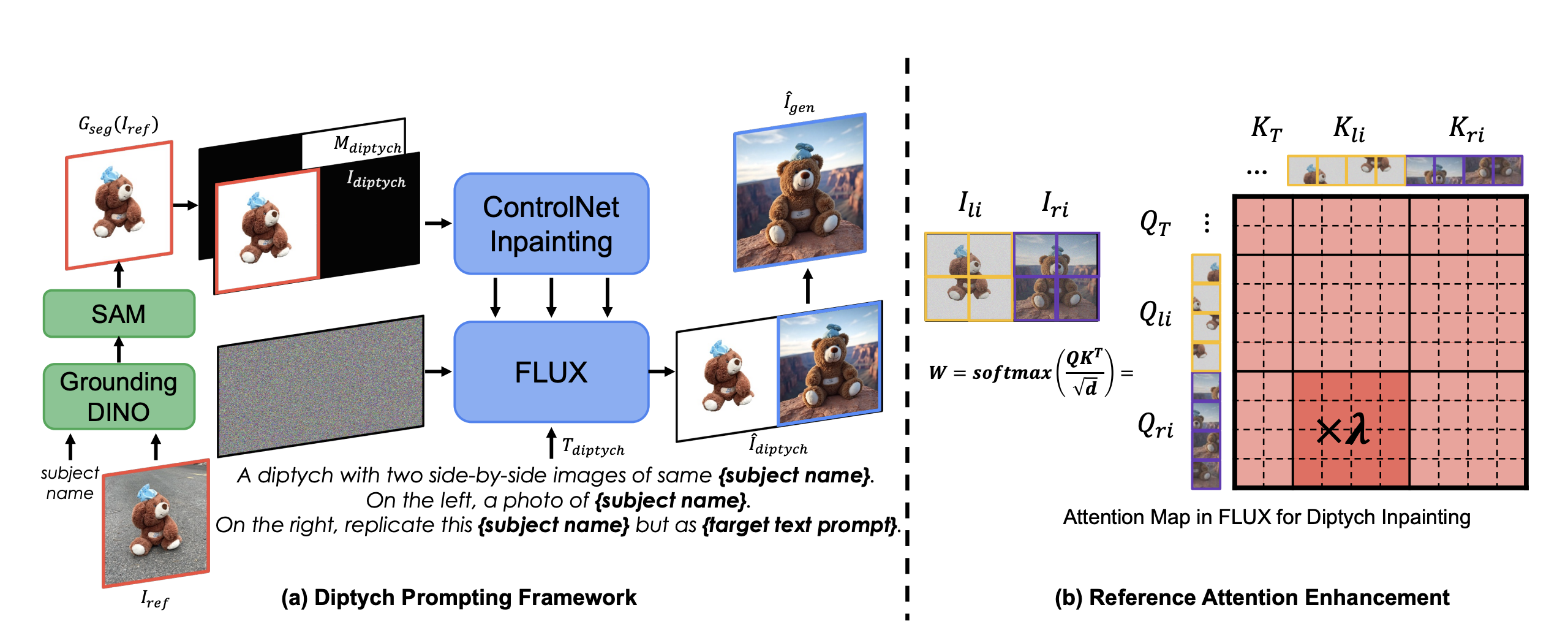
算法流程:
流程介绍:Flux模型具有生成双联画(diptychs)能力,该能力可以保证左右两个图像具有某种联系(如主体一致、风格一致等)。本文算法基于此先验提出了一种training-free的主体驱动生成方法[计作Diptych Prompting,即双联画prompting],是一种inpainting-based的方法,通过图像拼接的形式以左侧的图像作为引导并在右侧生成具有相同主体/风格的结果。此外算法在生成过程中通过attention权重加强的技巧进一步提升主体的细节保持。
Diptych Generation能示意图:
从下图可以看到,flux模型的双联画生成能力是最好的,其能够较好保证两个画面中的主体一致性:

算法细节:
推理流程:
该算法是一个training-free的方法,所以其直接在已有模型基础上进行推理,具体步骤如下
背景消除:为了消除复杂且无关背景的影响,先通过Grounding DINO和SAM依次对原主体图像
进行主体检测和分割,然后将结果右侧拼接一个纯黑图像,最终得到 构建Mask:和
相同尺寸,且左半纯黑,右半纯白表示对右侧进行inpainting,mask计作 构建prompt:使用类似以下模版的prompt分别描述左右两个图像,最终prompt计作
: A diptych with two side-by-side images of same {subject name}. On the left, a photo of {subject name}. On the right, replicate this {subject name} exactly but as {target text prompt}最终生成过程可以描述为:
最终模型直出的也是一个左右拼接的结果 ,其中右半部分 是生成的有效结果
Reference Attention Enhancement:
为保证在inpainting右侧的时候能够完美捕捉左侧图像的细节信息,作者在attention上做出了增强。
原网络中的attention是连接图像中两两部分的特征进行信息交互,但是这里是拼成一整张图送到网络中,并且其实对生成我们真正想要的结果(即生成的右半部分),有帮助的是“左侧inference图像对右侧图像的影响”,论文原话是:
This leads us to enhance reference attention−the influ- ence of the left panel on the right−to better capture granular details of the reference subject. 在修改attention之前,我们先来回顾下Flux中多模态的attention机制,其和SD3一样使用了MM-DiT架构,即将文本和图像特征拼接在一起进行attention,如下:
其中 是文本相关特征, 是图像相关特征。 而本算法中这里拼接的图像,其中的图像相关的attention特征又可以细分成2份,于是拆写成如下:
其中 是文本相关特征, 和 分别是左图和右图的相关特征。 于是作者得到了生成过程中的 attention weight,即 ,然后再手动增强该矩阵中左图特征对于右图特征的影响权重(其实有点类似OmniControl中的做法),即如本节的流程图中右半部分所示。
实验细节:
- 整个算法无训练细节,推理使用Flux-Dev作为骨干网络,使用ControlNet-Inpaining作为inpainting控制插件
- 拼图大小为768×1536,ControlNet 控制力度为0.95,cfg为3.5,推理步数为30步
- 本文提出的reference attention控制权重为1.3
其他细节:
- 消融实验:
- 主体抠图消融实验:如果不先对reference进行主体抠图,可能产生对主体进行简单粘贴复制的现象,此外导致背景内容泄漏,背景等无关的信息会反映在生成的结果中,并且也降低了主体姿势和位置的多样性
- Reference Attention权重消融:适当增加该权重能提升对于纹理、毛发的细节保持,但是过大又会导致主体看起来有点模糊或表现出轻微的色差。
- 应用:
- Subject-driven text-to-image generation:也是本算法首要解决的问题,即主体保持生成。
- Stylized Image Generation:将prompt中的subject
name换成
style并且不使用reference attention增强 - Subject-Driven Image Editing:对拼图的右半mask值并非全部设置为1,而是只对要编辑的区域设置为全1的mask
- 限制:
- 受限于Flux的生成分辨率,无法生成更大分辨率(如2048×1024)的双联画图像
- 论文中没提到的,其实生成结果的细节部分(如小纹理、logo等保持还是没那么好)
- 消融实验:
In-Context LoRA
《In-Context LoRA for Diffusion Transformers》
【主页】【论文】【代码】【Hugging-Face】
算法流程:本算法提出了一个非常简单但是很有效的方法,可以在一次去噪中同时生成一组图像并保证这组图像具有相近的光照、风格、主体、色系,生成过重中将该组中每张图像的caption直接拼接成一个完整prompt送到去噪过程中。每个任务只需要20~100张左右图片训练一个专门的lora。
写在前面:
- 先验:
- In-context Generation Capabilities: T2I下的DiT图像生成框架具有上下文生成能力,只需要使用高质量的数据进行最小程度的finetune即可激活这种能力
- Multi-Panel Images Generation: T2I模型具备能够根据单个prompt生成多面板图像的能力(即一张图中分成好几个子图)
- 之前工作:Group Diffusion Transformers指出,具有内在联系的图像可以通过拼接的形式在一次denoise的过程中同时生成,其具体做法是在生成过程中拼接每个区域的attention tokens然后一次性生成。该方法虽然简单有效但是泛化性仍然存在局限。
- 先验:
算法细节:
prompt拼接:将每张要生成图片的prompt直接拼接(如下图绿色底线),然后并在整个prompt最开始接上一个整体的描述(如下图红色框)

图像拼接:训练过程中只需要将多个具有关联的图像(比如电影分镜图)拼成一张大图作为图像输入;而在测试的时候,生成完后直接对整图进行split得到每张子图。
具有图像条件的生成:随机mask掉一组图像中的某张或者多张图像(及其对应的prompt),然后通过SDEdit等inpainting的方法让剩下的图像来修复它,这就有点像上面介绍的Diptych Prompting
其他细节:
- 应用领域:电影故事板生成、字体设计、人物多角度肖像、视觉设计(把指定logo/纹理装饰到物体上)、家庭装修、视觉特效生成、肖像插图、PPT生成、情侣头像生成
- 实验细节:
- 以 FLUX.1-dev为backbone
- 每个应用任务使用大约20~100张图像进行LoRA训练
- 训练时batch_size为4,单卡A100训练5000步,LoRA rank为16。
- 测试时step数为20,cfg为3.5
- 与Group Diffusion
Transformers的区别:
- Image Concatenation:该算法直接在一开始输入的图像级别对输入进行拼接,而非在denoise过程中对attention tokens拼接。
- Prompt Concatenation:也是直接在输入级别对每个图像的prompt进行拼接,这样该组中的每个图片都是能够看到其他图片的prompt的,而并非只能看到自己那部分的caption。
- Minimal Fine-Tuning with Small Datasets:因为其本质就是训练lora不会修改原backbone,所以只需要少量的图像(20~100张左右)就能满足一个任务。
- 局限性:
- 有时候还是会出现服装、人脸不一致的情况
总结
本章节主要介绍了AIGC下对生成结果进行特征保持的算法,主要包括通用物体特征的IP-Adapter、AnyDoor、CustomNet、RealCustom然后对于特征保持下一个重要的分支-“人脸ID保持”又重点介绍了三篇论文PhotoMaker、InstantID、PuLID,最后还介绍了基于当前先进的文生图模型Flux下两个简单有效的特征保持生成方法Diptych Prompting和In-Context LoRA
这类算法相比较以DreamBooth、LoRA、Textual Inversion等为代表的算法不仅训练成本低,效果也有一定提升。