
pytorch数据加载常用torch.utils.data.Dataset和torch.utils.data.DataLoader两个类进行实现,简单来说:
- torch.utils.data.Dataset:完成数据的初步读取和加载,其内的每一条数据是"零散"的
- torch.utils.data.DataLoader:对torch.utils.data.Dataset中"零散"的数据进行打包,同时也可以进行一些后处理操作和采样操作。
下面就通过代码的方式详细介绍上面的两个类。
torch.utils.data.Dataset
Dataset类简单来说就是完成数据的读取操作【当然也可以做一些简单操作】,pytorch中也内置了很多常用的计算机视觉的数据集【如如MNIST、CIFAR10、ImageNet】,通常是通过torchvision.datasets块来实现。
import torch
from torchvision import datasets, transforms
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True)
# 加载CIFAR10数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, transform=None)
...除了上面torchvision中已经有的数据库,用Dataset类来完成自己的数据集的读取也是很重要的,比如现在手里手里有一批用于训练ControlNet模型的数据,每一组内包含【RGB图像,Conditioning图像,promot】,数据的目录结构如下:
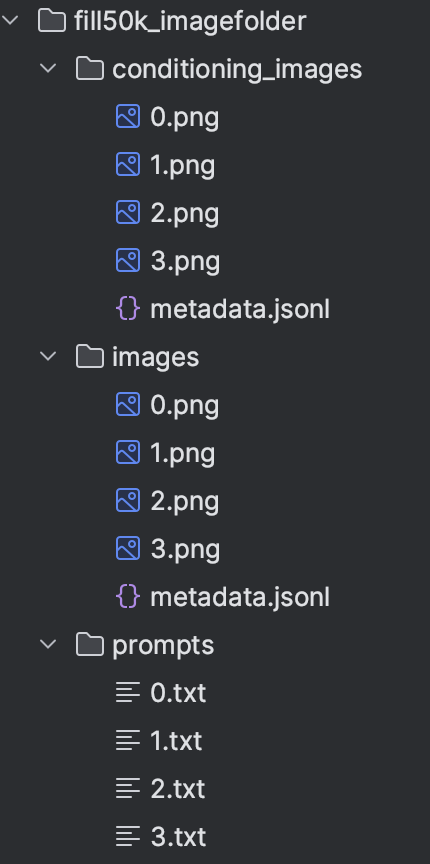
读取的示例如下:
'''
data.Dataset是pytorch数据加载的基准,一般我们要重写其三个方法:
__init__方法:进行类的初始化,一般是用来读取原始数据。
__getitem__方法:根据下标对每一组数据进行处理。return:对dataset[index]处理后的一组数据
__len__方法:return:数据集的数量(int)
'''
class Custom_Dataset(data.Dataset):
def __init__(self, data_root):
self.image_dir = os.path.join(data_root, "images")
self.conditioning_image_dir = os.path.join(data_root, "conditioning_images")
self.prompt_dir = os.path.join(data_root, "prompts")
self.paired_data_paths = self.get_paired_data_paths()
# 进行一些简单的数据预处理,比如这里的缩放和灰度化
self.image_transforms = transforms.Compose([
transforms.Resize(512, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.Grayscale()
] )
def get_paired_data_paths(self):
pair_data_paths = []
image_paths = glob("{}/*.png".format(self.image_dir))
image_paths.sort()
for img_path in image_paths:
img_name = os.path.basename(img_path)
cond_img_path = os.path.join(self.conditioning_image_dir, img_name)
prompt_path = os.path.join(self.prompt_dir, img_name.replace(".png", ".txt"))
pair_data_paths.append((img_path, cond_img_path, prompt_path))
return pair_data_paths
# item_idx表示整个数据集中当前读到的数据下标
def __getitem__(self, item_idx):
img_path, cond_img_path, prompt_path = self.paired_data_paths[item_idx]
image = self.image_transforms(Image.open(img_path).convert("RGB"))
cond_image = self.image_transforms(Image.open(cond_img_path).convert("RGB"))
with open(prompt_path, "r") as fr:
prompt = json.loads(fr.read())["text"]
# 1.这里的返回形式没有要求,可以是tensor、np.darray、numbers、dicts、lists、PIL.Image等各种形式
# 2.【后面会说可先跳过】若包在DataLoader中且collate_fn为None,则这里不能有PIL.Image类型,比如可以换成np.darray
# return np.array(image), np.array(cond_image), prompt
return image, cond_image, prompt
def __len__(self):
return len(self.paired_data_paths)
if __name__ == "__main__":
data_root = "./fill50k_imagefolder"
custom_dataset = Custom_Dataset(data_root)
# 可以直接对Dataset进行一个个样本的遍历
for image, cond_image, prompt in custom_dataset:
image.save("img.png")
cond_image.save("cond_img.png")
print(prompt)torch.utils.data.DataLoader
DataLoader是对Dataset类的进一层封装,其将零散的数据进行打包,同时有一些常用的参数更近一步规范数据形式:
- batch_size:每批数据共有多少组零散的数据
- shuffle:是否将dataset中的元素打乱
- drop_last:当batch_size无法整除dataset的数量,那么是否要舍掉最后一个不完整的batch
- collate_fn:取出batch_size组元素然后组成一个batch送到collate_fn函数中进行后处理,最终DataLoader每次迭代返回的batch就是collate_fn的返回值
- sampler:表示从dataset中采样的规则,比如逆序、只要前80%等...
- ...
比如我们要对上面零散的ControlNet训练数据进行“打包”,示例如下:
# 这里定义了一个collate_fn的传入参数(是一个函数),第一个参数表示从dataset中取出的一个batch的数据
def centercrop_collate_fn(batch_item, crop_size=256):
# 这里模拟了一个对batch中每组数据进行CenterCrop的后处理操作
gray_trans = transforms.CenterCrop(crop_size)
image_batch = []
cond_image_batch = []
prompt_batch = []
for image, cond_image, prompt in batch_item:
image_batch.append(gray_trans(image))
cond_image_batch.append(gray_trans(cond_image))
prompt_batch.append(prompt)
# 返回数据的类型只能是tensors, numpy arrays, numbers, dicts 或 lists
return image_batch, cond_image_batch, prompt_batch
# return {"gray_image": image_batch, "cond_image": cond_image_batch, "prompt": cond_image_batch}
# collate_fn的传入参数也可以是一个类
class CenterCrop_Collater():
def __init__(self, crop_size=256):
self.crop_size = crop_size
# 在__call__函数中实现对batch的后处理,这里也是实现同样的CenterCrop操作
def __call__(self, batch_item):
gray_trans = transforms.CenterCrop(self.crop_size)
image_batch = []
cond_image_batch = []
prompt_batch = []
for image, cond_image, prompt in batch_item:
image_batch.append(gray_trans(image))
cond_image_batch.append(gray_trans(cond_image))
prompt_batch.append(prompt)
return image_batch, cond_image_batch, prompt_batch
# return {"gray_image": image_batch, "cond_image": cond_image_batch, "prompt": cond_image_batch}
# 这里定义了一个sampler的传入参数(是一个类):
class my_sampler(data.Sampler):
# data_source是一个可迭代的数组类型, 可以是data.Dataset类型也可以是一般的list类型
def __init__(self, data_source):
self.data_source = data_source
# __iter__是Sampler的主要函数,其返回一个可迭代对象【是一个数值类型的下标集合】,即表示每次采样的下标
def __iter__(self):
# 比如这里自己规定了四个简单的采样:
return iter(range(len(self.data_source))[::-1]) # 逆序采样
# return iter(range(len(self.data_source))) # 顺序采样,也是默认的采样方式
# return iter(range(len(self.data_source))[:10]) # 只采样前10个(这种切片形式其实就可以从一整个数据集中划分训练/测试集合等)
# return iter(torch.randperm(len(self.data_source)).tolist()) # 随机不重复采样
# 此外还可以根据每个类别的比例进行加权采样....
def __len__(self):
return len(self.data_source)
if __name__ == "__main__":
# 2.对DataLoader一组的图像进行遍历
custom_dataloader = torch.utils.data.DataLoader(
custom_dataset, # 表示要对哪个dataset进行打包,【复用了上面的custom_dataset】
batch_size=2,
shuffle=False,
drop_last=True,
# collate_fn=functools.partial(centercrop_collate_fn, crop_size=384),
collate_fn=CenterCrop_Collater(crop_size=384),
# sampler=my_sampler(custom_dataset),
# batch_sampler = None
)
for custom_data in custom_dataloader:
# images, cond_images, prompts = custom_data["gray_image"], custom_data["cond_image"], custom_data["prompt"] # collate_fn的返回类型是dict则可以用这一行
images, cond_images, prompts = custom_data
images[0].save("img.png")
cond_images[0].save("cond_img.png")
print(prompts[0])其他要注意的事项:
DataLoader最终返回的每个batch中的元素必须是在
tensors, numpy arrays, numbers, dicts or lists中,而不能包含PIL.Image.Image等其他类型,所以'要么Dataset的__getitem__返回就是符合要求的,要么collate_fn的返回类型是符合要求""的。比如把collate_fn置为None,那么就会报错"TypeError: default_collate: batch must contain tensors, numpy arrays, numbers, dicts or lists; found <class 'PIL.Image.Image'>",这时候如果再将Dataset的
__getitem__的返回从PIL.Image变成np.darray就又ok了但是可以把其他不符合要求的类型打包在dicts或者lists中,比如上面collate_fn中返回的tuple或者dict
如果每组数据之间没有关联,那么其实在dataset的
__getitem__中把数据都单独处理完就行了(比如resize、crop、to_tensor等),那么collate_fn写成None就行DataLoader其实还有
batch_sampler参数,其是对sampler生成的indices再打包分组,得到一个又一个batch的index,不过一般用不到这么复杂的sampler参数定义每次从dataset中采样的规则,在其不为None时候则要求shuffle必须为False
pytorch中也提供了多种采样方式:
SequentialSampler: 顺序采样
RandomSampler: 随机采样
WeightedSampler: 权重采样
SubsetRandomSampler: 子集部分采样
...
HuggingFace的dataset库
除了上面介绍的pytorch中自带的数据加载API,随着HuggingFace在Transformers和Diffusers的影响力,其下的dataset库也逐渐受到学术界和工业界的重视。
自动下载社区已有数据集
dataset库允许我们使用load_dataset函数直接通过一句话在线下载HuggingFace社区已经有的数据集,一般有两种形式:
- 直接指定数据集名称。(一般是HuggingFace上的“用户名/数据集名”)
- 通过自定义的脚本,其实本质还是脚本内指定了数据集名称。(至于该脚本怎么写后面会进一步介绍,这里先用现成的)
比如下面一句话下载可用于ControlNet训练的数据集fusing/fill50k:
from datasets import load_dataset, load_from_disk
# 1.使用数据集名下载
my_dataset = load_dataset(path='fusing/fill50k' # 指定数据集名称
split='train', # 指定下在训练集合还是测试集合,不指定则全部下载
# 指定cache_dir下载到缓存路径,且下次在加载的时候优先从缓存中加载,避免重复下载
# 否则默认下载到hugging_face数据根目录下:~/.cache/huggingface/datasets
cache_dir="./dataset_demo/test/fill50k_auto_down")
# 2.使用自定义脚本下载
git_down_dataset = load_dataset(path="./dataset_demo/test/fill50k_git_down/fill50k.py", # 指定加载脚本
split='train',
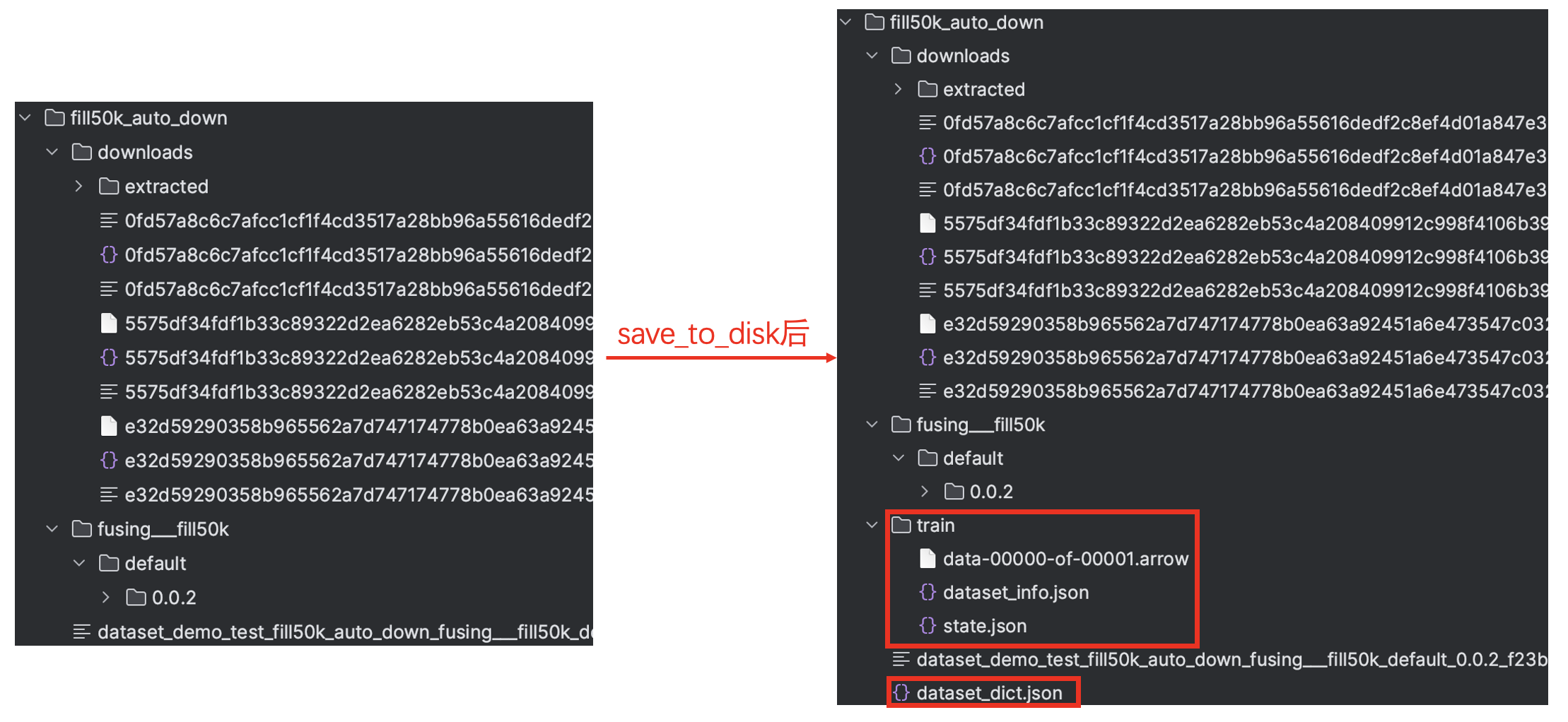
cache_dir="./dataset_demo/test/fill50k_auto_down_script")当然我们也可以通过save_to_disk将数据集保存到我们指定的位置,并通过load_from_disk再加载进来:
auto_down_dataset.save_to_disk("./dataset_demo/test/fill50k_auto_down")
auto_down_dataset = load_from_disk("./dataset_demo/test/fill50k_auto_down")其中save_to_disk会生成一些额外的数据和文件【因为该数据集只有训练集,所以没有test文件夹】,上面两中方式下载和添加后的文件是一致的,如下图所示:
Git下载好后本地加载
预先通过Git下载好数据集好,可以直接加载数据集
# 先git下载数据集:git clone https://huggingface.co/datasets/fusing/fill50k
git_down_dataset = load_dataset("./dataset_demo/test/fill50k_git_down")
git_down_dataset.save_to_disk("./dataset_demo/test/fill50k_git_down")
print(git_down_dataset)imagefolder加载
ImageFolder允许我们通过很简单的方式加载我们自定义的数据集,比如我们在"./dataset_demo/test/fill50k_imagefolder"目录下有如下的数据:
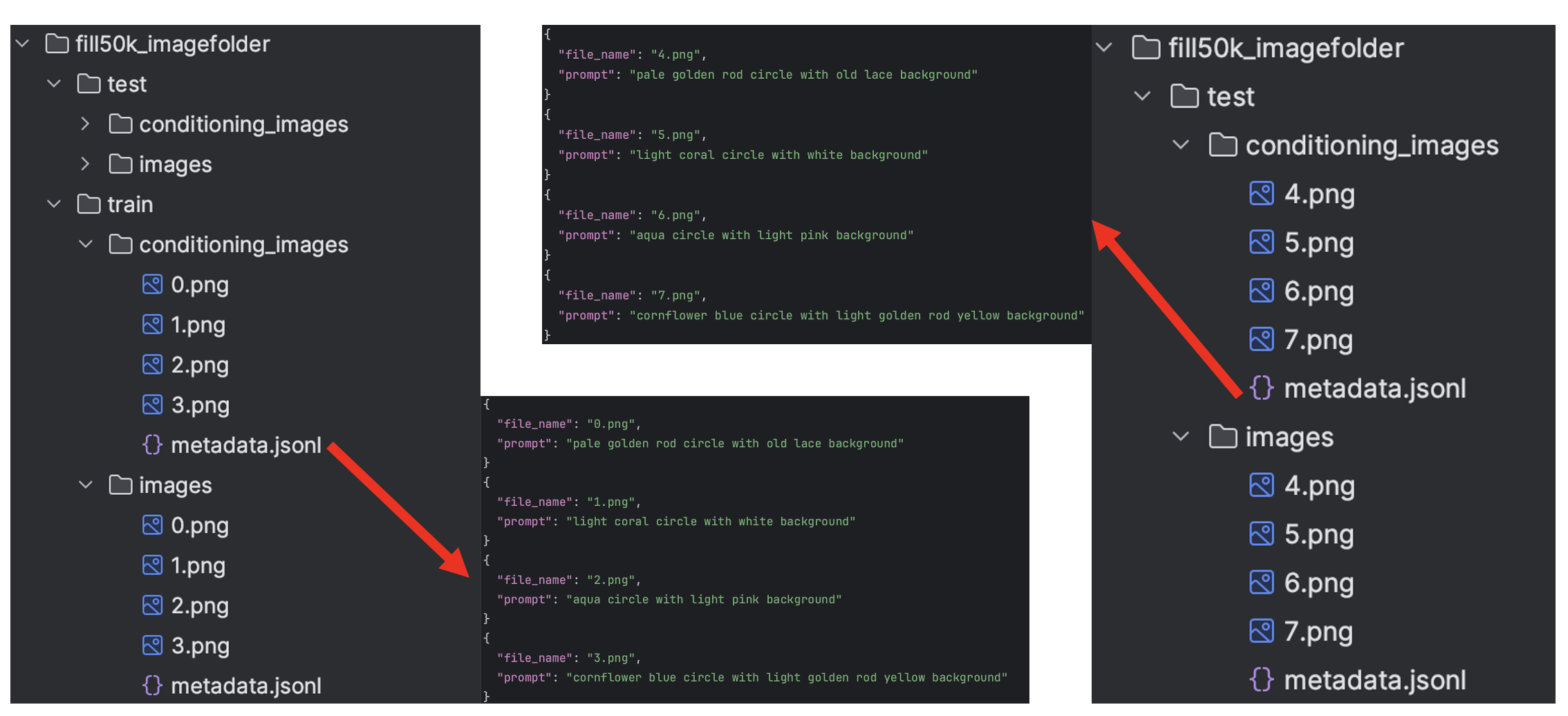
那我们就可以通过设置load_dataset的参数等于imagefolder进行加载,具体代码如下:
image_imagefolder = load_dataset( path="imagefolder",
data_dir="./dataset_demo/test/fill50k_imagefolder",
drop_labels=False # 设置为False,则train/test下根据文件夹分类别,得到"label"字段)
print(image_imagefolder)
print(image_imagefolder["train"][0])
'''
输出:
DatasetDict({
train: Dataset({
features: ['image', 'label', 'prompt'],
num_rows: 8
})
test: Dataset({
features: ['image', 'label', 'prompt'],
num_rows: 8
})
})
{'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=512x512 at 0x2A12C0040>,
'label': 0,
'prompt': 'pale golden rod circle with old lace background'}
'''要注意的是:imagefolder方式其实和pytorch原生的ImageFolder比较接近(比较适合图像分类任务),会自动遍历指定目录下的所有子文件夹,并将每个子文件夹视为一个不同的类别或标签。比如这里其实就是会将conditioning_images和images分别看成两个类别,分别赋予0和1两个类别标签。
Dataset.from_dict加载
上面的ImageFolder支持我们快速加载数据,但是无法支持更加复杂的数据,而Dataset.from_dict则允许我们相对灵活的加载自己的数据集,同样的比如我们还是以controlnet-fill50k为训练数据集自定义加载:
from datasets import Dataset, Image
from torchvision import transforms
# 按照下面的形式定义数据,如果是图片数据则传入图像路径
# 沿用上面fill50k_imagefolder的数据
data_dict = {
"pixel_values":[
"./dataset_demo/test/fill50k_imagefolder/train/images/0.png",
"./dataset_demo/test/fill50k_imagefolder/train/images/1.png",
"./dataset_demo/test/fill50k_imagefolder/train/images/2.png",
"./dataset_demo/test/fill50k_imagefolder/train/images/3.png",
],
"conditioning_pixel_values":[
"./dataset_demo/test/fill50k_imagefolder/train/conditioning_images/0.png",
"./dataset_demo/test/fill50k_imagefolder/train/conditioning_images/1.png",
"./dataset_demo/test/fill50k_imagefolder/train/conditioning_images/2.png",
"./dataset_demo/test/fill50k_imagefolder/train/conditioning_images/3.png"
],
"prompts":["pale golden rod circle with old lace background",
"light coral circle with white background",
"aqua circle with light pink background",
"cornflower blue circle with light golden rod yellow background"]
}
my_vis_dataset = Dataset.from_dict(data_dict) # 加载数据
print(my_vis_dataset)
'''
输出:
Dataset({
features: ['pixel_values', 'conditioning_pixel_values', 'prompts'],
num_rows: 4
})
'''
print(my_vis_dataset[0]["pixel_values"]) # 这时候仍然是str类型的图像路径
my_vis_dataset = my_vis_dataset.cast_column("pixel_values", Image()) # 利用cast_column将路径转为PIL图像数据
print(my_vis_dataset[0]["pixel_values"]) # 转为PIL的图像形式了(当然是并未做过任何归一化等处理)
my_vis_dataset = my_vis_dataset.cast_column("conditioning_pixel_values", Image())
def custom_mapping(examples):
# 这里使用map对数据集进行操作,比如这里将图像缩放到256
examples["pixel_values"] = [image.convert("RGB").resize((256, 256)) for image in examples["pixel_values"]]
examples["conditioning_pixel_values"] = [image.convert("RGB").resize((256, 256)) for image in examples["conditioning_pixel_values"]]
examples["prompts"] = ["add_"+prompt for prompt in examples["prompts"]]
return examples
# 如果有必要可以使用map()函数对数据集中再进行处理(比如对这里将图像resize,或者修改prompt)
my_vis_dataset = my_vis_dataset.map(custom_mapping, batched=True)
# Dataset.from_dict返回的结果是可以直接作为DataLoader的dataset
# 当然也要符合基本的要求,比如上面提到的,如果dataset返回形式有PIL,则需要转为tensor或numpy等符合要求的形式
# 比如这里可以提前使用with_transform进行一些变换
def prepare_train_dataset(dataset):
image_transforms = transforms.Compose(
[
transforms.Resize(512, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples["pixel_values"]]
images = [image_transforms(image) for image in images]
examples["pixel_values"] = images
conditioning_images = [image.convert("RGB") for image in examples["conditioning_pixel_values"]]
conditioning_images = [image_transforms(image) for image in conditioning_images]
examples["conditioning_pixel_values"] = conditioning_images
return examples
return dataset.with_transform(preprocess_train)
my_vis_dataset = prepare_train_dataset(my_vis_dataset)
my_data_loader = torch.utils.data.DataLoader(my_vis_dataset, shuffle=True, batch_size=1)
for step, batch in enumerate(my_data_loader):
pixel_values = batch["pixel_values"].permute(0, 2, 3, 1).numpy()[0]
pixel_values = (pixel_values * 0.5) + 0.5
pixel_values = (pixel_values * 255.0).astype(np.uint8)
conditioning_pixel_values = batch["conditioning_pixel_values"].permute(0, 2, 3, 1).numpy()[0]
conditioning_pixel_values = (conditioning_pixel_values * 0.5) + 0.5
conditioning_pixel_values = (conditioning_pixel_values * 255.0).astype(np.uint8)
prompt = batch["prompts"]
print("prompt:", prompt)
cv2.imshow("pixel_values",
cv2.cvtColor(np.concatenate([pixel_values,
conditioning_pixel_values], axis=1),
cv2.COLOR_RGB2BGR))
cv2.waitKey()自定义脚本加载
其实上面Dataset.from_dict已经能够满足我们大多数的需求了,但是HuggingFace中很多有通过脚本下载数据的例子,包括上面通过脚本自动下载社区数据。
这里我们定义一个脚本来处理下面这种结构的数据:

dataset_script = load_dataset(
# 1.通过指定的py脚本进行数据生成
path="./fill50k_script/fill50k_custom.py",
# 2.如果是指定的文件夹路径,那么会在该文件夹下寻找和文件夹同名的py文件作为生成脚本。
# 比如这里将上面fill50k_custom.py复制一份得到fill50k_script.py,并简单修改其中的一些路径,就可以直接通过下面只通过指定文件夹的形式加载数据
# path="./test/fill50k_script",
cache_dir="./dataset_demo/test/fill50k_script")
print(dataset_script)
'''
输出:
DatasetDict({
train: Dataset({
features: ['image', 'conditioning_image', 'text'],
num_rows: 4
})
})
'''
dataset_script["train"][2]["image"].save("./tmp.png")
dataset_script.save_to_disk("./dataset_demo/test/fill50k_script")其中fill50k_custom.py中主要是定义了继承datasets.GeneratorBasedBuilder的类,该类要重写三个方法:
- 函数_info(self) : 用于描述该数据集,比如homepage、license等,
- 函数_split_generators(self, dl_manager) : 用于划分数据集(训练/测试等)
- 函数_generate_examples(self, dl_manager): 对每个数据集进行处理(比如读取图片等)
完整的fill50k_custom.py代码如下:
from PIL import Image
import pandas as pd
import datasets
import os
import logging
_VERSION = datasets.Version("0.0.2")
# 数据集路径设置(因为这里是从本地读取数据,所以这里要指定数据集路径)
META_DATA_PATH = "train.jsonl"
IMAGE_DIR = "./"
CONDITION_IMAGE_DIR = "./"
# 定义数据集中有哪些特征,及其类型
_FEATURES = datasets.Features(
{
# 定义数据名称和类型,注意这里数据名称不一定要和train.jsonl中的一致,
# 但是这个key是最为最终dataset的column_names
"image": datasets.Image(),
"conditioning_image": datasets.Image(),
"text": datasets.Value("string"),
},
)
_DEFAULT_CONFIG = datasets.BuilderConfig(name="default", version=_VERSION)
# 定义数据集
class My_Fill50k(datasets.GeneratorBasedBuilder):
BUILDER_CONFIGS = [_DEFAULT_CONFIG]
DEFAULT_CONFIG_NAME = "default"
def _info(self):
return datasets.DatasetInfo(
description="None",
features=_FEATURES,
supervised_keys=None,
homepage="None",
license="None",
citation="None",
)
def _split_generators(self, dl_manager):
metadata_path = dl_manager.download(META_DATA_PATH)
images_dir = dl_manager.download(IMAGE_DIR)
conditioning_images_dir = dl_manager.download(CONDITION_IMAGE_DIR)
# 上面的操作其实就是利用dl_manager.download下载hf_hub_url,并且拼接一些路径
# 所以这里如果就是从本地下载可以抛弃dl_manager.download,直接赋值三个路径就行:
'''
metadata_path = "./dataset_demo/test/fill50k_script/train.jsonl"
images_dir = "./dataset_demo/test/fill50k_script"
conditioning_images_dir = "./dataset_demo/test/fill50k_script"
'''
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
# These kwargs will be passed to _generate_examples
# 这里是将图像全部用于训练集合了,当然也可以读取每个路径下的文件路径,然后划分训练/测试,重新传参数
# 下面的参数是和_generate_examples函数的入口参数对齐的
gen_kwargs={
"metadata_path": metadata_path,
"images_dir": images_dir,
"conditioning_images_dir": conditioning_images_dir,
},
),
]
# 输入参数是和_split_generators返回的dict中的gen_kwargs参数对应的
def _generate_examples(self, metadata_path, images_dir, conditioning_images_dir):
metadata = pd.read_json(metadata_path, lines=True)
for _, row in metadata.iterrows():
text = row["text"] # 这里的key是和train.jsonl文件中对应的
image_path = os.path.join(images_dir, row["image"])
image = open(image_path, "rb").read() # 保存成二进制形式
conditioning_image_path = os.path.join(conditioning_images_dir, row["conditioning_image"])
conditioning_image = open(conditioning_image_path, "rb").read()
'''
当然我们也可以对已有的数据做一些操作后再作为真正dataset数据
1.先读取pillow图像数据
image_pil = Image.open(image_path).convert("RGB")
2.然后对image_pil做一些自定义的操作,比如取反...
image_pil = Image.eval(image_pil, lambda x: 255 - x)
3.最后再保存成bytes类型
image_bytes = io.BytesIO() # 注意:这里不要使用cv2.imencode保存成bytes类型!!!不然会导致RGB顺序错乱
image_pil.save(image_bytes, format="JPEG")
image = image_bytes
# with open("./show_img.png", "wb") as fw:
# fw.write(image_bytes.getvalue()) # 这里可以保存后查看操作后的数据是不是符合预期的
'''
yield row["image"], {
"text": text, # 这里的key要和_FEATURES保持一直,也是用来作为最终dataset的column_names
"image": {
"path": "", # 如果原始数据是经过操作的了,那么这里可以不指定'path'
"bytes": image,
},
"conditioning_image": {
"path": conditioning_image_path, # 同理这里也可以不指定'path'
"bytes": conditioning_image,
},
}webdataset加载
webdataset是一种tar压缩包形式的数据存储形式,比较适合数据量比较大的情况下:
比如我们有以下一组数据,其中image后缀和conditioning_image后缀就是直接将png图片后缀从png改过来的,prompt后缀也是从txt/jsonl后缀改过来的,每一组的数据使用相同的文件名,相同特征的数据用相同的后缀名:

我们先用tar命令将数据打包:
tar --sort=name -cf tar1.tar tar1 # --sort=name命令一定要加将数据集打包后就可以直接用load_dataset("webdataset",...)进行读取了:
webdataset_data = load_dataset("webdataset",
data_files={"train": ["./dataset_demo/test/fill50k_webdataset/tar1.tar"]},
split="train",
streaming=True
)
print(webdataset_data) # IterableDataset类型,也是可以直接用DataLoader包装的
'''
输出:
IterableDataset({
features: ['__key__', '__url__', 'conditioning_image', 'image', 'prompt'],
n_shards: 1
})
'''
for item in webdataset_data:
# 所以数据都会保存为bytes形式,这里进行decode还原数据
image = cv2.imdecode(np.asarray(bytearray(item["image"]), dtype="uint8"), cv2.IMREAD_COLOR)
conditioning_image = cv2.imdecode(np.asarray(bytearray(item["conditioning_image"]), dtype="uint8"), cv2.IMREAD_COLOR)
json_info = item["prompt"].decode('utf-8')
print(json_info)
cv2.imshow("result", np.concatenate([image, conditioning_image], axis=1))
cv2.waitKey()多分辨率数据集构造
✅2024.11.30补充
当前主流Diffusion框架下的文生图模型都支持生成多尺寸、不同宽高比的图像,这就要求在训练过程中也要有不同尺寸不同宽高比的图像数据喂给模型,而pytorch中的Dataset类和直接的DataLoader类都是只支持单一尺寸的,所以需要我们做一些改动。
比如我们现在有一批数据,构成【图像、caption、16进制色卡信息】的pair对(其中图像数据是尺寸、分辨率不限的),如下所示:
{
"image1.png": {
"caption": "xxxxxxxxxxxxx",
"palette_rgb": [
"#c1dfc5",
"#496e4d",
"#84b890",
"#3d3218",
"#a77a2d"
]
},
"image2.png": {
"caption": "xxxxxxxxxxxxx",
"palette_rgb": [
"#260c09",
"#51231c",
"#754e3f",
"#b76e65",
"#e0d7c6"
]
},
......
}构造多分辨率训练数据集的整体思路如下:
- 分组:在预设的一些尺寸集合中(如512x512,448x576等)找到与当前图片的宽高比最接近的尺寸作为该图片的桶尺寸,并将具有相同同尺寸的图片归为一组
- 构建Dataset:将具有相同桶尺寸的的图像全部缩放到该桶尺寸构成一个dataset【就是常规的dataset构造方式】
- 构建DataLoader:使用pytorch原生的DataLoader再包一层(指定batch_size、shuffle等参数)
- 整合多尺寸DataLoader:将上述构造的所有DataLoader封装在一个大类中(同样也是DataLoader类)
- 重写函数:重写DataLoader的三个函数
__len__、__iter__、__next__函数
完成上述操作后,获得的大类就是普通的DataLoader类,可以直接使用。
完整的具体代码如下:
import json
import os
import torch
import random
import numpy as np
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
from torchvision.transforms import Compose, Resize, Normalize, ToTensor
from dataset.dataset_utils import find_nearest_bucket_size, convert_to_palette
# 预设一些尺寸集合(称为桶尺寸)
buckets = [(256, 768), (320, 768), (320, 704), (384, 640), (448, 576), (512, 512),
(576, 448), (640, 384), (704, 320), (768, 320), (768, 256) ]
def find_nearest_bucket_size(input_width, input_height, ratio=1.0):
'''
给定原图的宽高,从预设尺寸集合中挑出与之宽高比最接近的那个桶尺寸,作为该图像最终的尺寸)
'''
aspect_ratios = [w / h for (w, h) in buckets]
asp = input_width / input_height
diff = [abs(ar - asp) for ar in aspect_ratios]
bucket_id = int(np.argmin(diff))
gen_width, gen_height = buckets[bucket_id]
return (int(gen_width * ratio), int(gen_height * ratio))
class ColorPaletteSingle(Dataset):
def __init__(self, bucket_size, pair_infos):
'''
将具有相同桶尺寸的的图像全部缩放到该桶尺寸构成一个dataset
bucket_size=(bucket_w, bucket_h)
pair_infos=[(img_path11, prompt11, ["#xxxxx", "#xxxxx", "#xxxxx", ,"#xxxxx", "#xxxxx"]), ....]
'''
self.pair_infos = pair_infos
self.trg_transformers = Compose([
Resize((bucket_size[1], bucket_size[0]), interpolation=Image.BICUBIC),
ToTensor(),
Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
self.conda_transformers = Compose([
Resize((bucket_size[1], bucket_size[0]), interpolation=Image.BICUBIC),
ToTensor(),
Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
def __len__(self):
return len(self.pair_infos)
def __getitem__(self, item):
image_path, prompt, palette_str_list = self.pair_infos[item]
trg_image = Image.open(image_path)
w, h = trg_image.size
#将16进制的颜色转为10进制并返回色卡形式(这里与本文章主旨不符,不做展开)
color_rgbs, conda_image = convert_to_palette(palette_str_list, h, w)
return {
'image_path': image_path,
'color_tensor': torch.from_numpy(np.array(color_rgbs)),
'color_palette': self.conda_transformers(conda_image),
'trg_image': self.trg_transformers(trg_image),
'prompt': prompt,
}
class ColorPaletteBucket(DataLoader):
def __init__(
self,
json_paths: list[str],
res_ratio=1.5,
batch_size=1,
num_workers=2,
shuffle=False,
drop_last=False
):
self.json_paths = json_paths
self.res_ratio = res_ratio
self.bucket_list = self.get_bucket_list()
self.bucket_datasets = self.get_bucket_datasets()
self.bucket_dataloaders = self.get_bucket_dataloaders(batch_size, num_workers, shuffle, drop_last)
def get_bucket_list(self):
'''
对所有图片按照宽高进行进行解析,把具有相同桶尺寸的图片归为一组,返回的bucket_infos的形式如下:{
(768, 768): [(img_path11, prompt11, ["#xxxxx", "#xxxxx", "#xxxxx", ,"#xxxxx", "#xxxxx"]), ....],
(256, 768): [(img_path21, prompt22, ["#xxxxx", "#xxxxx", "#xxxxx", ,"#xxxxx", "#xxxxx"])....],
....
}
'''
bucket_infos = {}
for dataset_json_path in self.json_paths:
with open(dataset_json_path, "r") as fr:
cur_json_info = json.load(fr)
# cur_image_dir = dataset_json_path.replace(".json", "")
cur_image_dir = dataset_json_path[:dataset_json_path.rfind("_")]
for image_name, image_info in cur_json_info.items():
image_path = os.path.join(cur_image_dir, image_name)
prompt = image_info["caption"]
palettes_str_list = image_info["palette_rgb"]
cur_image = Image.open(image_path)
w, h = cur_image.size
cur_bucket_size = find_nearest_bucket_size(w, h, ratio=self.res_ratio)
cur_pair = (image_path, prompt, palettes_str_list)
if cur_bucket_size not in bucket_infos.keys():
bucket_infos[cur_bucket_size] = [cur_pair]
else:
bucket_infos[cur_bucket_size].append(cur_pair)
return bucket_infos
def get_bucket_datasets(self):
'''
对每组图像构造一个dataset
'''
total_num, datasets = 0, []
for bucket_size, pair_data_infos in self.bucket_list.items():
print("bucket_size:{}--->{} samples".format(bucket_size, len(pair_data_infos)))
total_num += len(pair_data_infos)
datasets.append(ColorPaletteSingle(bucket_size, pair_data_infos))
print("There are {} images total........".format(total_num))
return datasets
def get_bucket_dataloaders(self, batch_size, num_workers, shuffle, drop_last):
'''
对每个dataset再用原生的DataLoader封装一下
'''
dataloaders = []
for dataset in self.bucket_datasets:
sampler = DistributedSampler(dataset) if torch.distributed.is_initialized() else None
dataloader = DataLoader(
dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=shuffle,
pin_memory=True,
sampler=sampler,
drop_last=drop_last
)
dataloaders.append(dataloader)
return dataloaders
def __len__(self):
length = 0
for dataloader in self.bucket_dataloaders:
length += len(dataloader)
return length
def __iter__(self):
# 该函数只会运行一次
self.bucket_iteration = []
for dataloader in self.bucket_dataloaders:
self.bucket_iteration.append(iter(dataloader)) # 将dataloader变成iterable对象
return self
def __next__(self):
# dataloader每次取batch会运行该函数
while len(self.bucket_iteration) > 0:
# 随机选择一个bucket size的dataloader(变成iterable后的)获取数据
cur_idx = random.randint(0, len(self.bucket_iteration) - 1)
cur_iter = self.bucket_iteration[cur_idx]
try:
return next(cur_iter)
except Exception as e: # 当前dataloader取完就pop
self.bucket_iteration.pop(cur_idx)
raise StopIteration
if __name__ == '__main__':
json_paths = [ "/path/to/file1.json", "/path/to/file2.json"]
color_palette_bucket = ColorPaletteBucket(json_paths=json_paths, batch_size=4)
print("len(color_palette_bucket):", len(color_palette_bucket))
ind = 0
for data in color_palette_bucket:
show_ind = 0
print(data["image_path"][show_ind], data["prompt"][show_ind], data["color_tensor"][show_ind])
print(data["color_palette"].shape, data["trg_image"].shape)
target_image = (data["trg_image"][show_ind] + 1) * 127.5
cond_image = (data["color_palette"][show_ind] + 1) * 127.5
target_image = np.transpose(target_image.numpy(), (1, 2, 0))
cond_image = np.transpose(cond_image.numpy(), (1, 2, 0))
target_image = Image.fromarray(target_image.astype(np.uint8))
cond_image = Image.fromarray(cond_image.astype(np.uint8))
cond_image.save("conda_image{}.png".format(ind))
target_image.save("trg_image{}.png".format(ind))
print("-----image is saved!------")
ind += 1总结
本篇文章主要通过具体的实例,介绍了PyTorch中数据加载的机制,同时也介绍了目前dataset库常用的几种数据加载方式。最后通过详细的代码介绍了目前文生图模型普遍会使用到的多尺寸图像的数据构造与加载。这些强大的数据读取与加载机制,能够让我们极大程度减少在数据加载上的精力,而更加专注模型结构的设计与训练。