Diffusion相比较起前辈GAN,在生成质量上已经得到了大幅度的提升,之前的文章介绍过虽然通过prompt配合上classifier-free guidance技术能够从一定程度达到控制生成内容的目的,但是如何更加精确控制diffuison结果,例如定制化生成指定的目标对象,控制生成目标的姿态、形状、颜色等,也成为后续研究的重点,当然这些控制性生成目前也已经能够达到下图所示的非常好的效果了,本篇文章也将重点介绍些这些控制diffusion生成的大杀器。

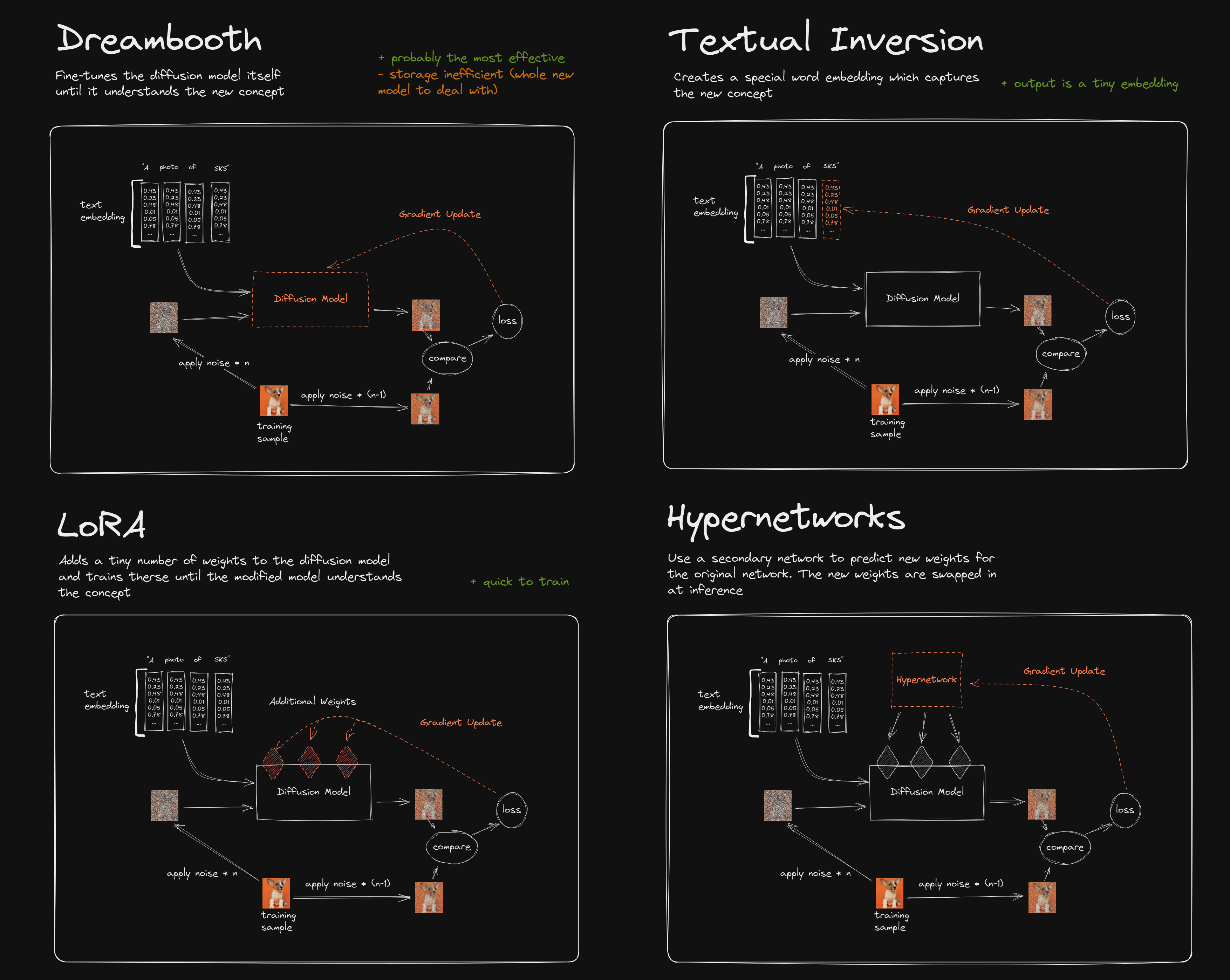
DreamBooth
《DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation》
【主页】【论文】【官方仓库-无code】【Dreambooth-Stable-Diffusion】
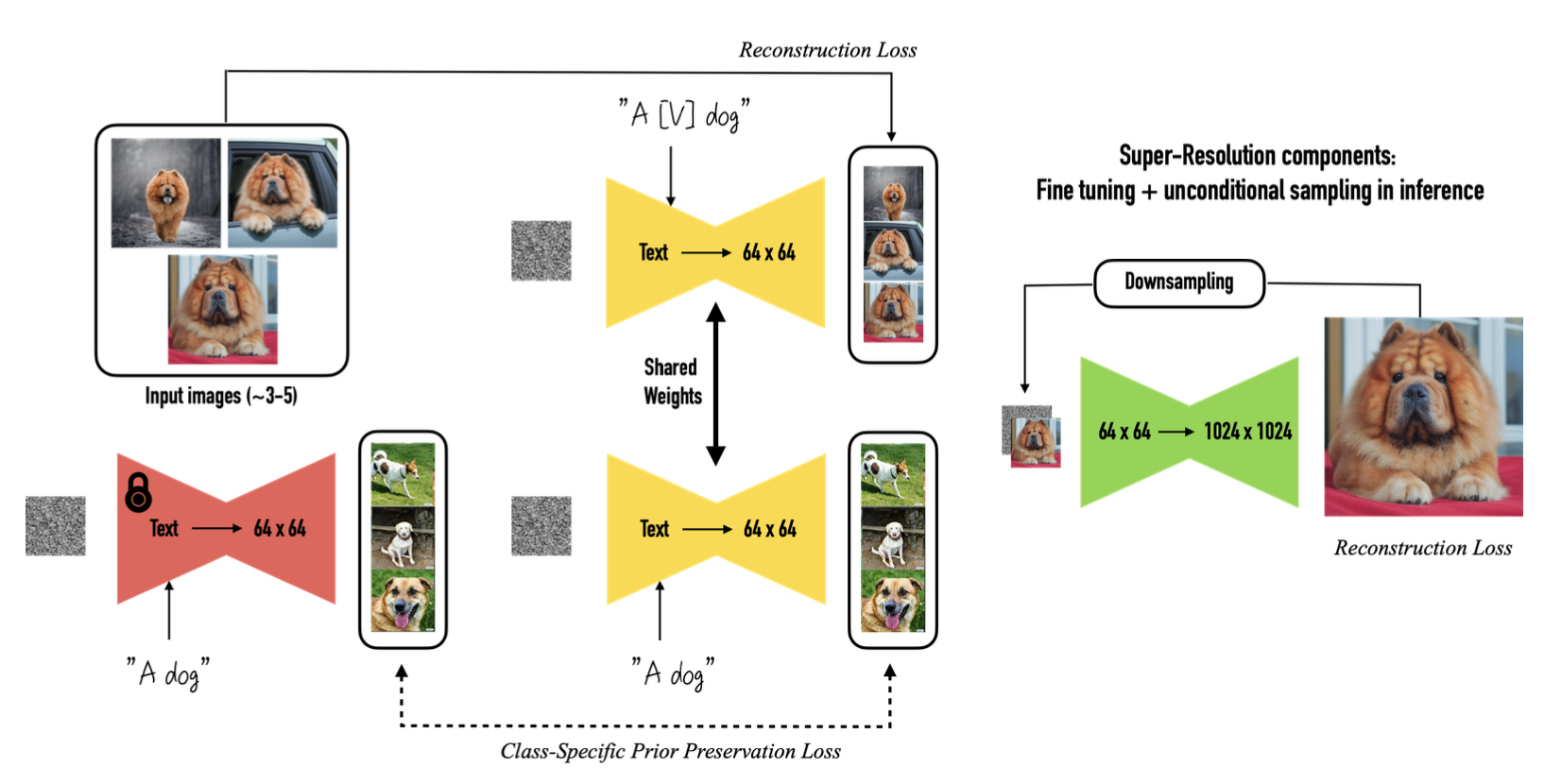
算法初衷:为了实现文生图模型能够生成我们指定的目标(比如你家的狗狗),通常可以把这些数据放进训练集中一起训练,但是通常这会导致"Language Drift":模型过拟合的一种,即模型只能生成你家狗狗的图像,而不会生成其他狗狗的图像。
算法细节:
首先要知道的是,该算法会对整个文生图模型都进行参数更新,让其学习到指定的新概念
数据准备:3~5张指定目标的图像(不同姿态、角度),并将其绑定到一个特殊promt,格式如"a [V] [class]"
- [V]表示目标特有的名字,这里有两个注意点:
- 不要用常见的英文单词,如"unique"/"special"等,因为这些单词在原文图数据集中是已经出现的,如果强行将这些词绑定到指定的目标上,会导致训练时间增加而且效果也不一定好。
- 不要用完全无意义的随机字母组合,如"xuehglajl"/"i74jdbi"等,不然模型可能会拆开这些字母,有可能会生成字母相关的概念/图形,如艺术字。
- [class]表示目标所属的种类,如"Dog"、"Cat"等。
- [V]表示目标特有的名字,这里有两个注意点:
为了防止模型只会生成指定图像而不会生成该类别的其他目标,本文还提出了"class-specific prior preservation loss":
该损失可以拆开成两个部分看: - 前半部分表示使用指定目标的图像和构造的新prompt-“a [V] [class]”作为新概念的图文pair进行训练
- 后半部分则表示使用“a [class]”作为prompt表示
,在配合上原来生成的图像 作为总体大类别的图文pair对
算法应用:
- 语义重构:主体换pose、换背景、换材质
- 艺术渲染:在保留目标id的情况下进行风格迁移
- 表情编辑
- 新视角生成
- 附件化:给目标添加装饰品或换装
- 属性修改:换颜色、纹理等
LoRA
《LoRA: Low-Rank Adaptation of Large Language Models》
预备知识:
- 矩阵的秩: 指矩阵行列式中无法通过其他行/列线性组合得到的行/列数,简单点说就是对矩阵包含的真正信息量。
- 满秩与秩亏:当矩阵中任何行/列都无法通过其他行/列经过线性组合得到时,此时称矩阵是满秩的且秩
,否则称矩阵是秩亏的。
算法初衷:LoRA起初是用在自然语言处理领域,用来对大语言模型进行微调,但是其基本思想是通用的并在文生图领域大火了起来。简单来说LoRA是大模型的低秩适配器,在文生图领域可以代表某个指定的目标或指定的风格、场景。
算法细节:
动机:该算法认为深度神经网络模型通常是过参数化的(over-parametrized),其具有更小的内在维度(low intrinsic dimension),模型真正运行主要依赖于这些低维度信息。
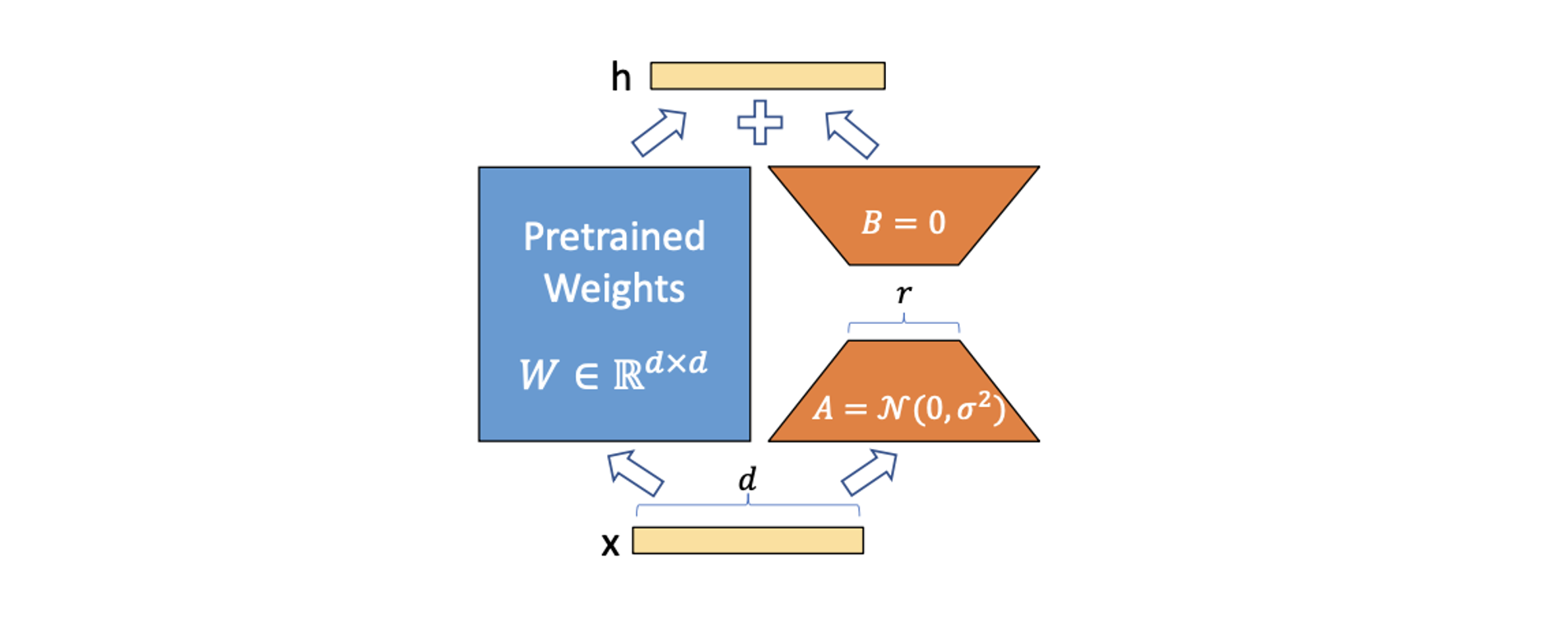
具体做法:在拥有一个已经训练好的大模型下,LoRA会引入一个远小于原模型参数量的小网络,以极小的参数在指定的数据上进行微调,具体做法如下:
在原模型(如上图的蓝色区域)旁边增加一个支路(如上图橘黄色区域),通过低秩分解(即先降维再升维)来控制额外引入的参数量。
训练时固定住原模型参数(如
),只更新旁路的参数(即降维矩阵 和升维矩阵 ),其中 表示为“低秩”,一般取 使用高斯分布初始化,$B使用全0初始化,保证训练开始时旁路为0矩阵(这其实和之后要提到的ControlNet很像了,全0初始化能最大程度保留原预训练模型的能力) 推理之前,可以直接将参数
添加到原权重上: 在真正推理时只是相当于更换了原权重的数值,所以不会引入额外的推理耗时 可插拔式的快速切换任务,当前在任务
时,可先减去新加的LoRA权重,换成新LoRA权重 即可快速实现任务切换。
参考:
Textual Inversion
《An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion》
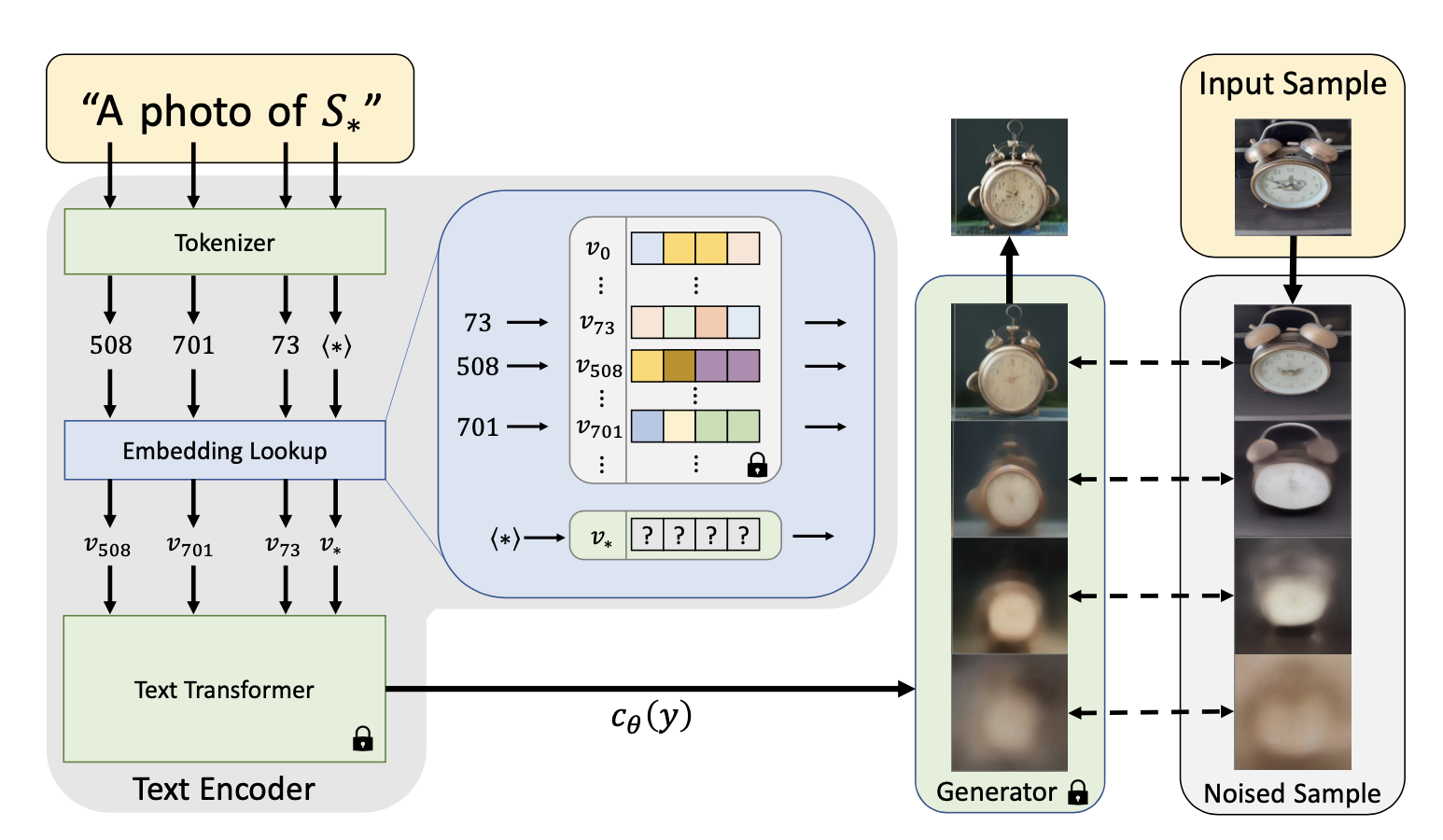
算法流程:Textual Inversion用一句话介绍就是:通过几张目标图像将指定的文本绑定到text embedding空间内某个特殊的向量,让文生图模型能够学习到新的概念,可以理解为Embedding的一种。不同于上面介绍的DreamBooth、HyperNet、LoRA,该方法最大的特点是其仅仅在prompt空间找到合适的embedding,不会改变原文生图模型的网络权重(即属于“Prompt tuning”大类)。
算法细节:
预备知识-文本编码:
- 使用tokenizer将输入语句中的每个单词/子词转换为一个token,它代表预先定义的查找表(Embedding Lookup)的索引;
- 根据每个token下标找到查找表中对应的embedding,这些embeddings也是后续文本编码器的输入;
算法具体流程:
本算法以embedding空间作为Inversion的优化目标,在文本输入时先指定一个占位符字符串 S* 来表示希望模型学习的新概念;
用优化找到后的新向量- v* 替换与新概念关联的embedding,具体公式为 :
其中 分别表示噪声预测网络、文本编码网络,在该过程中是完全固定的。通过这一步优化则新概念S*被关联到了词汇表中的新向量 v* ;
随机文本选择:抽取偏中性的上下文文本,这些文本源自 CLIP ImageNet 模板,形如:"a photo of a S∗." / "a rendering of a S∗." / "a close-up photo of a S∗."
算法应用:
- 图像多样性变换(Image variations)
- 文本引导的个性化生成(Text-guided synthesis)
- 风格迁移(Style transfer)
- 偏见修正(Bias
reduction):修复类似
“a CEO”倾向于生成男性职场人这种案例
参考:
HyperNet
【论文】【NovelAI开发文档】
HyperNet最初是NLP技术下的一个微调技术,其通过设定一个额外的RNN网络来预测原始网络中的某些权重,这里不做单独的算法分析,将其与上面的三种技术做对比分析
| 算法 | 如何修改原网络权重 | 结果大小 |
|---|---|---|
| DreamBooth | Finetune全部修改 | 同原网络权重(2~3G) |
| Lora | 加上一部分额外权重 | 几百兆 |
| Textual Inversion | 不修改权重 | 几十K |
| HyperNet | 预测原网络权重 | 几百兆 |
参考:
ControlNet
《Adding Conditional Control to Text-to-Image Diffusion Models》
【论文】【Supplementary】【代码】【HuggingFace】
写在前面:ControlNet可谓是打响了Diffusion可控性第一枪,其凭借大道至简的设计思路和爆炸的控制效果在算法一开源后就引爆了整个文生图的AIGC圈,该博客的最开始那些效果图也是controlnet的结果。
✅ 在2024念8月重读这篇论文又有了新的角度和之前没关注到的点,此外在看了源码后也有了更深的认识,所以重新补充了这部分内容。
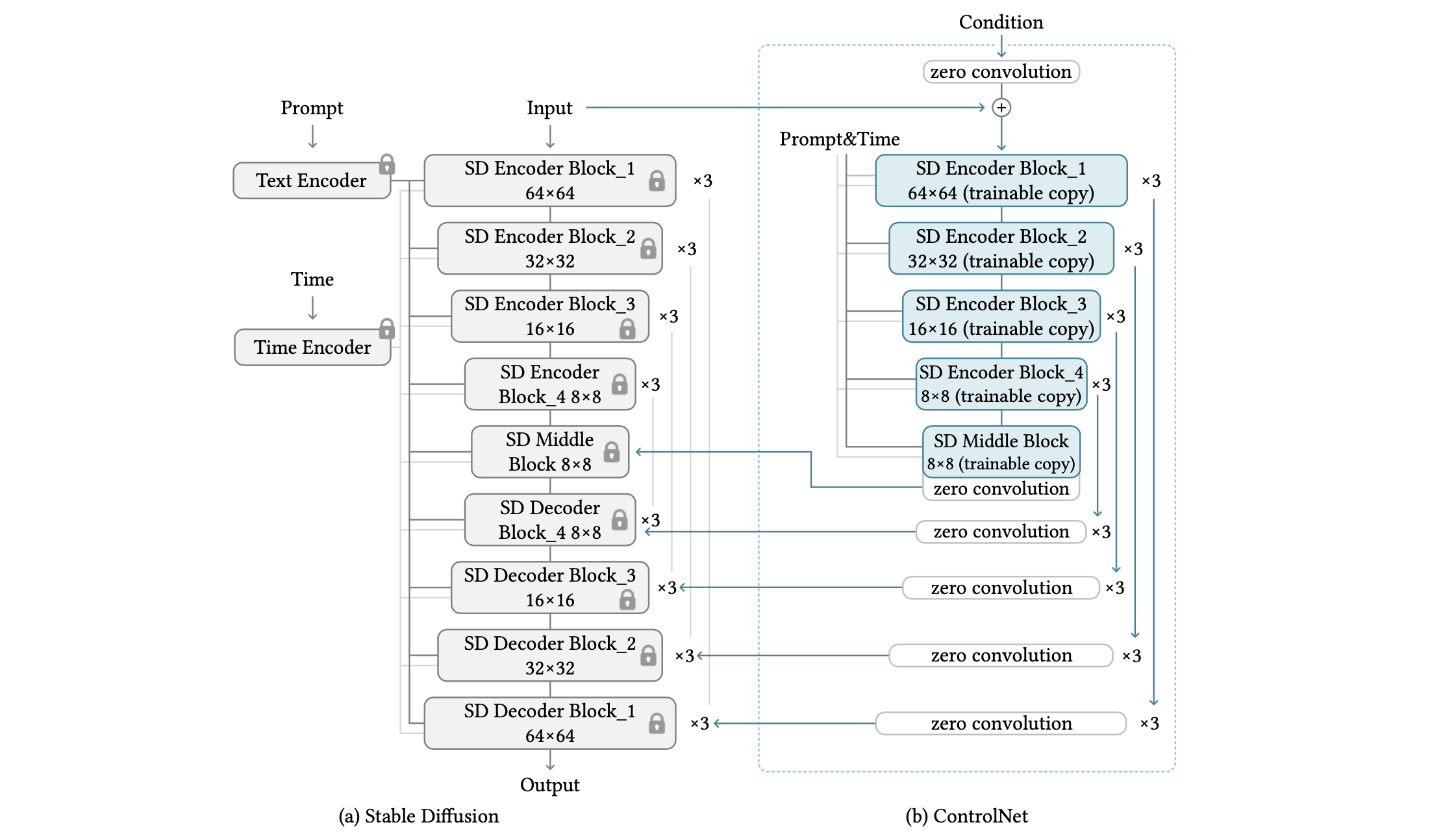
算法流程:该算法整体设计思路简单但有效,其保留原本Stable Diffusion权重不变的情况下,拷贝了和Diffusion的Unet中的部分权重,通过zero convolutions的方式初始化网络,并引入控制条件(如线稿图、分割图等)将中间特征图加到原UNet部分对应的特征上,完成控制生成。
算法细节:
控制条件提取与注入:
如何提取控制特征:如上结构图所示:ControlNet复制了SD-UNet的encoder和middle blocks部分进行训练提取控制特征,并通过Zero Convolution将控制特征注入到UNet中。总的输入包括【condition latent,noisy latent、time embedding以及prompt embedding】。其中condition latent是通过一个额外的小卷积网络从控制图(如canny边缘图、深度图)提取到的,后面会介绍。
''prompt"和"time"的注入:controlnet添加的那部分权重在UNet中是需要引入''prompt"和"time"信息直到参数更新的,其中引入"time"能够保证在diffusion去噪的初始阶段控制low-level的效果(如颜色、结构),之后不断提升控制的细粒度(如纹理细节),其实这是和sd-webui中的“guidance_start”与“guidance_end”是对应的。
如何将控制条件注入到原UNet网络:
回顾:
SD-UNet的Encoder结构包括一个简单conv_in、3个CrossAttnDownBlock2D和1个DownBlock2D。其中CrossAttnDownBlock2D构成则是2组(ResnetBlock2D+AttentionBlock)和1个Downsample2D;DownBlock2D则是两个ResnetBlock2D;
SD-UNet的的MiddelBlock包括 (ResnetBlock2D、AttentionBlock、ResnetBlock2D)的结构。
上述的conv_in的输出(共1个)、CrossAttnDownBlock2D中的AttentionBlock输出(共6个)和DownBlock2D输出(共3个),还有DownBlock2D的ResnetBlock2D输出(共2个),一共12个结果会通过Concat的形式添加到Decoder上。
ControlNet则复制了SD-UNet的Encoder部分共得到12个特征,然后将这个12个特征加到原来UNet的Encoder的12个特征输出上,最后以skip connection方式拼接到UNet的Decoder中对应的部分;此外ControlNet也复制MiddelBlock部分并加在原始UNet的Middle Block的输出上,这样一来就一共就会有13个特征。具体可参考👉🏻ControlNet的特征注入。
Zero Convolution:零卷积是该算法重点强调的一个点,其是一个使用全零初始化权重和bias的1x1卷积。
基本流程: 如下图所示:其拷贝了SD网络的Encoder权重并在引入控制信号和融入控制条件到原特征前都了使用全零卷积进行计算。
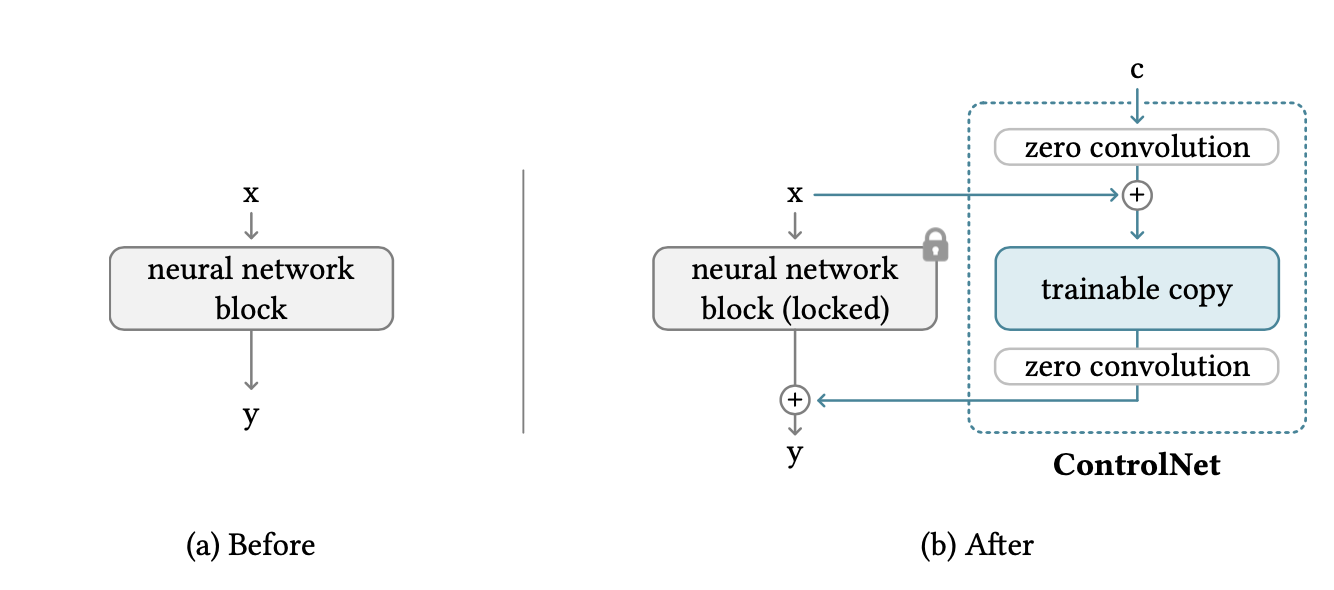
优点: 全零卷积能够保证其引入的控制条件在训练初始阶段输出为0,即一开始不会引入任何控制条件信息,能够最大程度保留原Diffusion模型的生成能力,然后在训练过程中逐步引入控制条件。
可能的疑问:全零卷积难道不会导致网络训练梯度消失吗?
其实论文中也提到了,虽然全零卷积会导致输出全零但是对应的梯度不是零,能会保证参数的不断更新。这里网络权重的初始化其实我之前也有一篇博客介绍过可以作为参考。
图像空间转latent空间:
首先回顾下SD是先利用VAE的Encoder将
的图像转为 大小的latent,并在加噪后得到 大小的noisy latent作为UNet的输入(更多细节可见Diffusion学习5-高质量文生图模型),所以本文的ControlNet首先需要先将 分辨率的条件图(如3通道的canny图、depth图、normal图等)转成 ,具体做法是使用了一个由4层卷积层、ReLU作为激活函数、卷积步长为2、kernel_size=4的神经网络进行下采样,网络权重使用高斯初始化,具体实现可见ControlNetConditioningEmbedding。 然后该网络的输出再经过一层Zero Convolution后得到与noisy latent同大小的特征,再和原noisy latent相加后作为ControlNet-UNet-Encoder真正的输入。其实noisy latent还要过经过一层conv再相加,具体可见pre-process。
训练细节:
数据:【prompt,控制信号,结果图】,其中控制信号是直接对结果图进行特征提取(如使用canny提取的边缘图、使用深度估计预测的depth等)
损失函数:与原始Diffusion的训练损失基本是相同的,唯一变化的就是网络的输入多了一个控制信号
: 其中 分别输入噪声、时间戳、文本信息、控制信号。
Guess Mode:即仅仅使用控制信号生成图像而不使用任何prompt,作者说这样能够最大程度释放controlnet的能力。
Sudden Convergence:训练过程会有一个突然收敛的过程,如前6000step模型不收敛,生成结果与控制信号无关,但是到6000 step后某个step会突然收敛,保证生成结果和控制信号是对齐的。这是因为condition信息是在提取特征后又通过了一层zero convolutions注入到UNet中的,所以可能会存在”突然收敛“的现象,论文中说通常在10K步以内突然收敛。
Classifier-Free Guidance Resolution Weighting:
回顾:目前Classifier-Free Guidance技术已经成为Diffusion模型的标配了,其主要是为了达到prompt条件控制的目的,公式可以写成
,其中 和 表示不带prompt条件预测的噪声, 表示带有prompt条件预测的噪声,简单来说,CFG技术计算带有控制条件和不带控制条件的偏差,然后逐渐将预测结果往”有条件“的那一方移动得到最终预测的噪声 。而 则是移动的力度,越大表明控制越强。 在ControlNet中使用CFG存在的问题:在CFG的基础上加上ControlNet,就相当于有两个控制信号了,那么ControlNet的输出的控制信息是只用在
呢?还是 与 都用呢?答案都不正确。如果 与 都用,那么在ControlNet的Guess Mode下【即没有prompt控制】会导致ControlNet的控制信息被抵消了。而如果只用在 则会导致控制信号太强,进而影响最终生成结果的质量。 解决:在不同的连接处给定不同的控制力度。具体地将ControlNet特征添加到
中,但是在添加到UNet中时不同block下的的再乘以不同的权重 ,比如对于13个blocks, 分别为 ,具体代码好像有点不相同,实现如下: model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13) ''' Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01 输出:在strength=1.0时,control_scales从0.01增加到1.0 '''
使用该技术后,能够极大程度提高生成质量,如下:

多条件的控制:为了同时使用多个信号控制生成结果,首先要先训练各自的ControlNet部分(就是copy出来的那部分和新加的zero convolution部分),然后再推理的时候提取每个控制信号各自的ControlNet特征,然后直接相同分辨率的特征相加后再融合到原SD的特征中即可,该部分不需要任何其他权重和Linear层,具体可参考MultiControlNetModel。
消融实验:
zero convolutions的必要性:设计了其他两种条件注入形式:1.使用高斯初始化来代替全零初始化;每个block只用一个简单的卷积层来提取特征。
在推理的时候使用了4种形式prompt 进行验证:1.空prmpt,即Guess Mode;2.不全面的prompt(只有一些类似
high-quality, detailed, and professional image的套词);3.和控制条件完全冲突的prompt;4.完全匹配控制条件的prompt。3种网络结构在4中prtmpt控制的结果:
可以看到算法提出的zero convolutions效果最好,其在各种prompt下都能有很好的控制效果。
其他注入结构:
当前的方案,拷贝Encoder和MiddelBlock并使用zero convolutions加到encoder完整特征上。
结构不变,但是去掉zero convolutions
使用一个额外的卷积网络提取控制特征并加到原UNet-Encoder上
和c.一样但是提取的控制特征并加到原UNet-Decoder上
和d.一样但是加到UNet-Decoder之前使用了zero convolutions
只加一个卷积提取特征,并且微调整个SD-UNet

同样也使用了4种形式的prompt进行效果对比,最终也是表明目前提出的a结构效果最好。
控制形式:
ControlNet1.0提供了如下集中控制信号: Canny边缘图、建筑直线图(M-LSD)、HED边缘、手绘线稿图、动漫线稿图、姿态图、分割图、深度图、法向图等,每一类使用到的俄数据量和训练GPU时间如下:
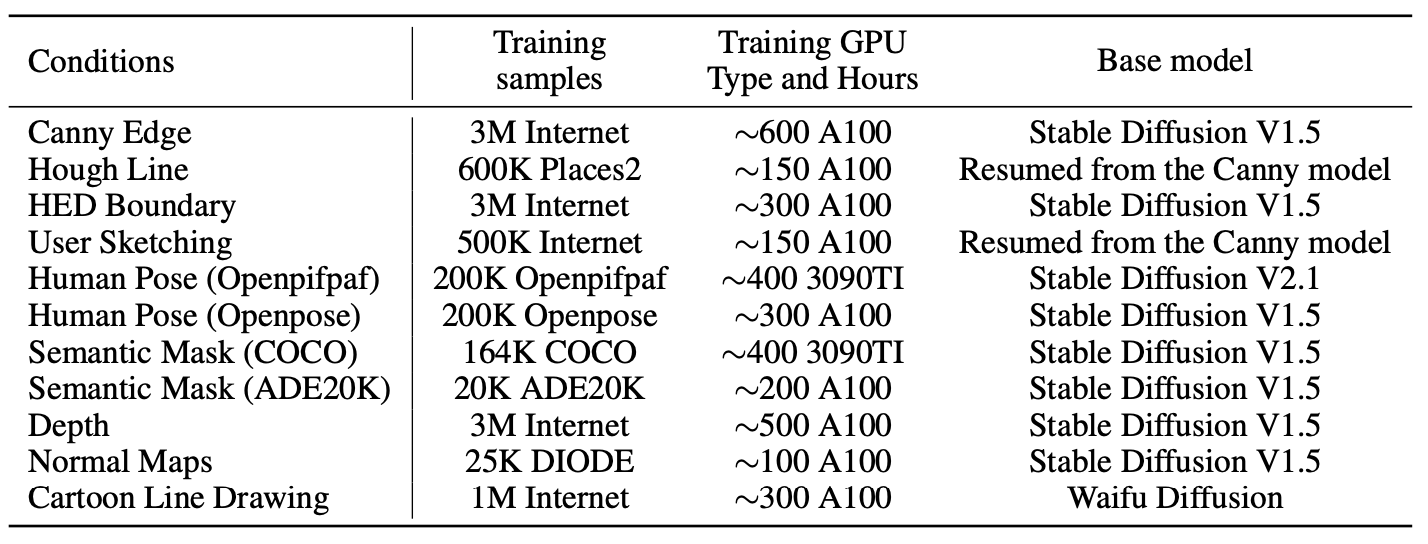
可以看到其实训练一个ControlNet的数据量并不需要很多,基本上100K级别就够了。其实我在训练的时候,最少1万张以内的图片,训练5、6万步左右就能达到一个比较好的收敛效果。
ControlNet1.1在以上控制信号基础上,又添加了下面几个比较重要且独特的控制信号:
- Shuffle:对图像重新排列生成风格类似但是内容有差别的其他结果
- Inpaint:对指定区域进行填充
- Tile:对模糊的图像补充细节(非图像超分)
- Reference-only:无需重新训练模型,通过attention共享的方式生成风格和内容都类似的其他结果
参考:
T2I-Adapter
《T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models》
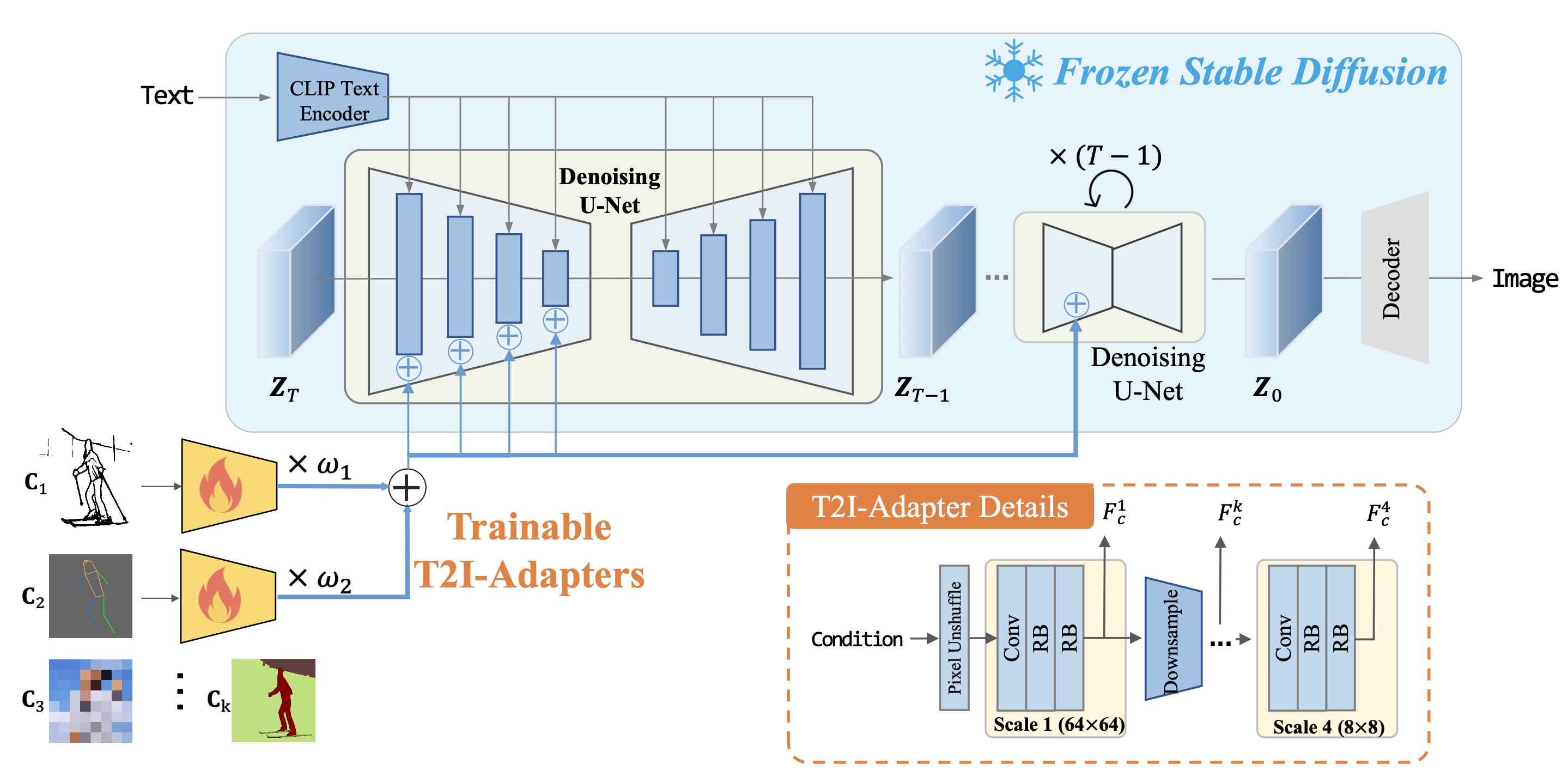
算法流程: T2I-Adapter的整体思路感觉和ControlNet的想法还是比较接近的,首先两者目的都是为了使用边缘图、姿态图等控制Diffusion的生成结果,其次两者也都是在Denoise过程下Unet的encoder中融入控制信号。
算法细节:
核心模块-T2I-Adapter:首先原512x512大小的控制信号通过pixel unshuffle降采样到64x64大小,然后T2I-Adapter模块包括4个特征提取模块和3个降采样模块,最终降采样到8x8大小,然后将这个过程中的4种分辨率特征(64、32、16、8)依次添加到原SD模型的UNet的Encoder特征上。
其中 表示UNet的encoder特征和adapter网络特征。 原SD的权重在整个训练过程中是固定的,只对新添加的adapter模块进行参数更新,整个训练过程的损失函数和原Diffusion也是一样的:
其中 分别表示带噪声图像、时间戳、文本信息、控制信号。 多条件控制: 该算法类似ControlNet一样可以支持不同控制信号的自由组合,指定每种控制信号的的比例权重然后加权求和后直接添加到原SD特征上。
和ControlNet一个比较大的不同点在于,该算法的adapter是不接受时间戳信号的,即其在整个denoise的不同阶段都是会控制生成结果的,至于该方式的优劣暂未有一个明确的说法。
算法优势:
泛化性强:一次训练可以在不同版本的SD模型下达到控制效果
即插即用:轻量化(最大版本的t2i-adapter也只有77M参数量+300M存储空间,最小的则是5M参数量+20M存储空间)
控制形式:
支持包括像ControlNet也使用的线稿图、深度图、分割图、姿态图、inpainting
T2I-Adapter还支持色彩盘(Spatial Color Palette)控制,即通过颜色块来控制整个生成结果的颜色布局,色彩盘的制作方式就是对原RGB图先进行64倍bicubic下采样然后再64倍nearest上采样回原分辨率。
改进:
该算法团队收到Composer的启发,提出了CoAdapter,联合训练各个adapters和一个额外的融合模块,该模块允许对不同的adapter控制赋予不同权重,并且支持诸如"Style"的全局控制。
和ControlNet的区别:
该算法作为和ControlNet几乎同期出现的T2I控制算法,并且都是在冻住原SD模型的情况下训练额外的插件。两者主要区别点在于:
- 网络结构不同:T2I-Adapter采用一个轻量级网络来提取condition的特征,而ControlNet则是拷贝并重新训练了原SD-UNet的部分权重进行特征提取。
- 输入内容不同:T2I-Adapter的condition网络(即adapter)仅接受condition图像为输入,不接受time embedding和prompt embedding的,而ControlNet则是都接受。
- 特征注入方式不同:T2I-Adapter提取的特征是串行加到UNet-Encoder上的,即Encoder的当前block特征是经过上个block特征和adapter特征共同得到的【这个思路其实就有点像ControlNet在Supplementary中提到的c.结构】,而ControlNet提取的特征和原UNet-encoder特征是并行计算互不影响的,两者只是在concat到deocder前才会相加。具体可以看源码👉🏻unet_2d_condition.py
Composer
《Composer: Creative and Controllable Image Synthesis with Composable Conditions》
阿里的论文,据说是支持其文生图大模型-通义万相的强大算法
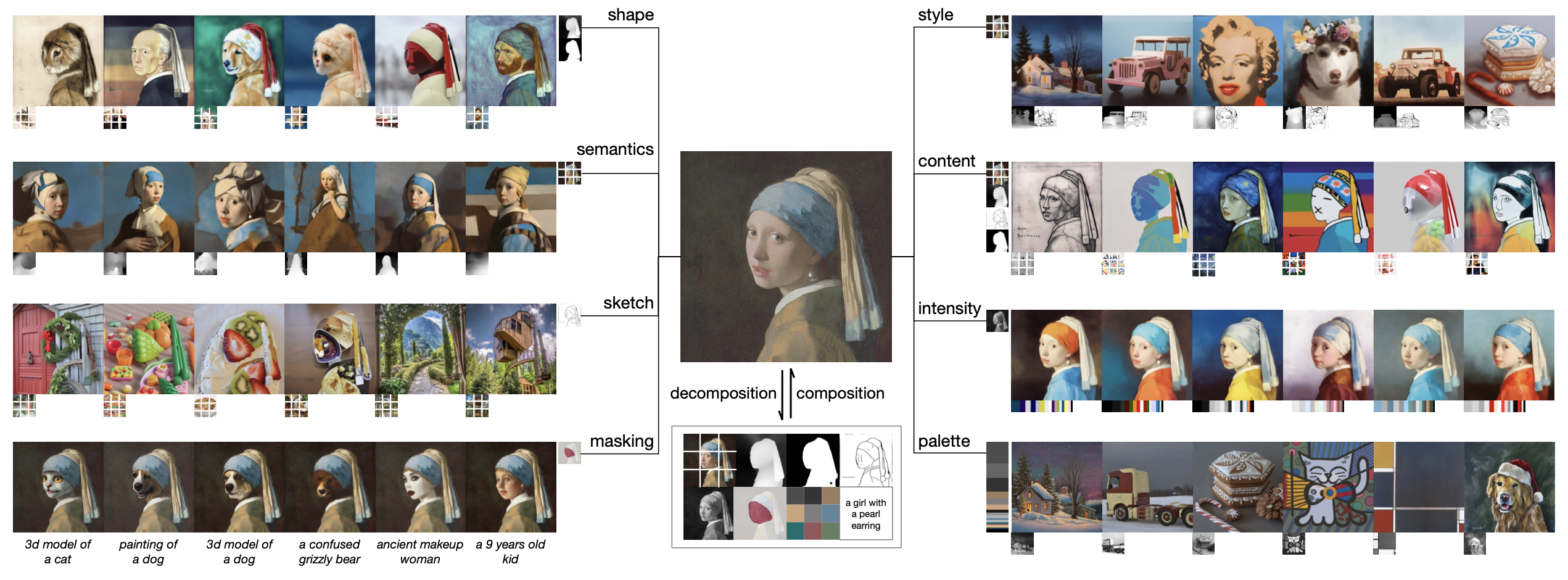
算法流程:将一张图像拆解(Decompose)成8种独立的表征,再将这些表征的embedding或feature map通过自由组合(Compose)的方式嵌入到SD的网络中来控制生成结果,通过这种输入条件的自由组合,可以获得指数级别的多样性。
算法细节:
模型组成:
- Conditional Image Generation : 参数量2B,输出256x256大小
- 上采样网络1:参数量1.1B,上采样至256x256大小
- 上采样网络2:参数量300M,上采样至1024x1024大小
条件生成:
引导方向(Guidance Directions): 不同于原始的classifier-free guidance,这篇论文为了支持多特征同时控制引导,对CFG稍作改动:
其中 表示两种图像表征信号, 表示控制力度 双向引导(Bidirectional Guidance):先使用
条件将原图像 加噪到 ,然后在去噪过程中使用 条件生成新图像。
图像表征拆解:
通过使用计算机视觉算法或预训练模型将一张图像分解成8个单独的表征:
描述(Caption):使用CLIP的text分支提取图像的sentence embedding
语义和风格(Semantics and Style):使用CLIP的image分支提取图像的image embedding
颜色(Color):统计色彩信息,包括11个色系+5个对比度+5个亮度
线稿(Sketch):提取边缘信息代表图像的局部信息
实例(Instances):使用YOLOv5进行实例分割得到目标类别和形状信息
强度(Intensity):使用灰度图表示(此外为了减少灰度图过强的控制,对RGB通道随机加权并在cfg时候随机dropout)
掩膜(Masking):指定可编辑区域
表征组合控制生成:
- 对于前三种全局控制(描述、语义风格、颜色),会映射至8个长度的token,然后拼接到CLIP的embedding。
- 对于其他局部的控制,则是将在diffusion过程中将这些控制图像提取和noisy的
相同尺寸大小的中间特征,然后将这些特征相加后concatenate到 上,再送入到U-Net网络预测噪声。
联合训练策略:
对于各种全局条件和局部条件,采用不同概率的dropout,具体地:首先对于每个条件有50%概率dropout,其次有10%概率丢弃所有条件,有10%概率保留所有条件。特殊地,对于强度(Intensity)表征,因为其具有过于丰富的信息,所以起dropout概率达到70%,防止淹没其他控制条件。
算法应用:
- 多样化(Variations):更换组合条件生成和原图相似但不同内容的图像
- 图像插值(Interpolations):对在embedding空间对全局条件进行插值
- 重配置(Reconfigurations):使用双向引导(Bidirectional Guidance)完成
- 可编辑区域(Editable region):通过mask限制可编辑区域
- 基于调色盘上色(Palette-based colorization):给出了两种方法,1.在采样过程中使用原图的灰度图和颜色引导;2.使用重配置方法)
- 风格迁移(Style transfer):使用原图的内容表征【depth+instance+semantics】和风格图的风格表征【semantics】进行控制生成)
- 图像翻译(Image translation):原图所有可用的内容表征,配合不同prompt进行图像转换
- 姿态迁移(Pose transfer):使用原图的CLIP embedding,配合指定姿态的分割图或线稿图完成姿态迁移
- 虚拟试衣(Virtual try-on):待试衣人体的衣服区域mask,配合上新衣服的CLPI image embedding控制完成试衣
Layout Diffusion
《LayoutDiffusion: Controllable Diffusion Model for Layout-to-Image Generation》
写在前面: 这篇论文细节和公式比较多,没有对其中每个细节理解很好,这里就从整体的角度简单介绍下这篇论文。
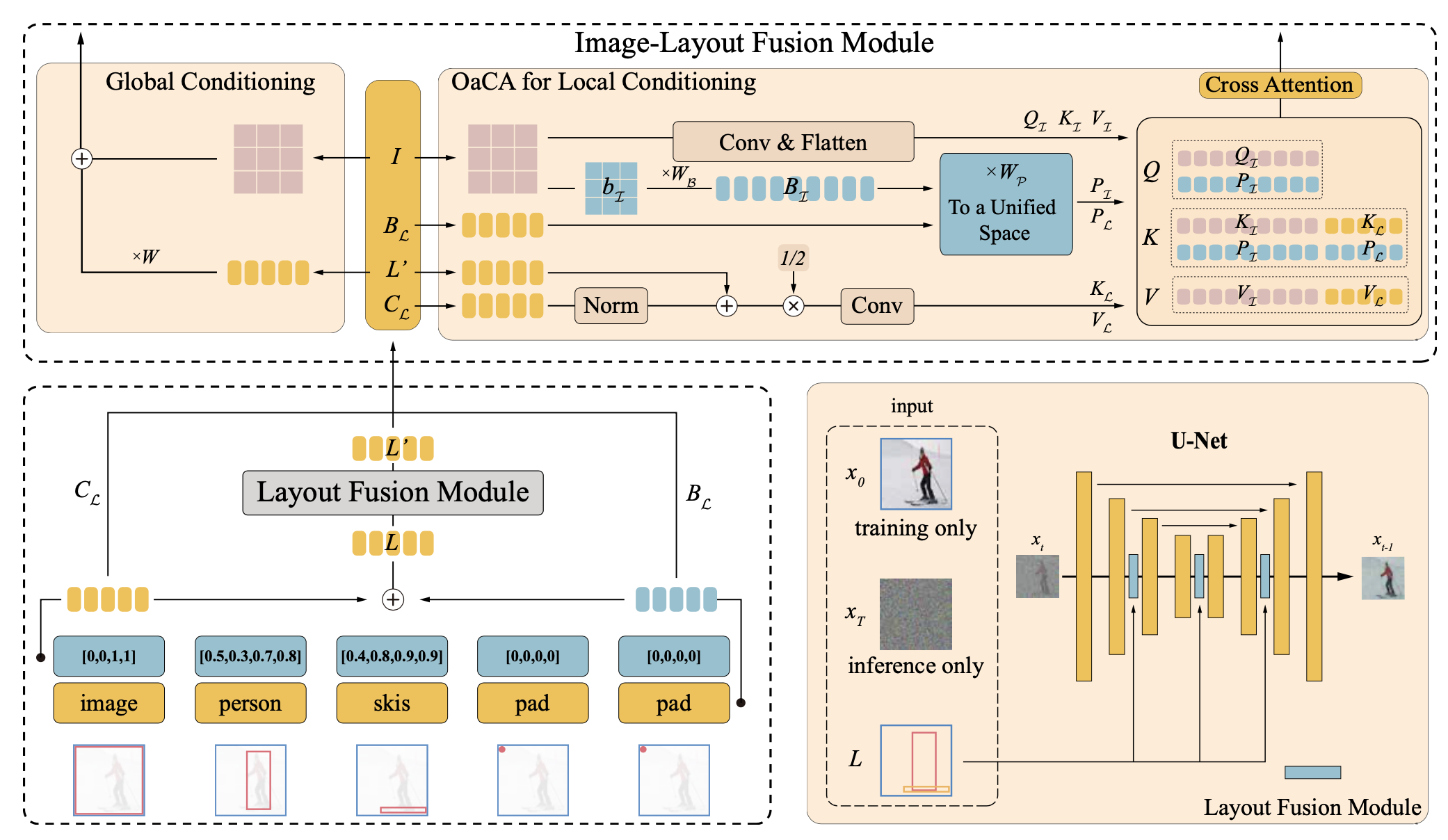
- 算法框架: 该算法在Diffusion模型下提出了一个使用包围框+类别+文本控制生成结果的算法,不仅能够控制生成结果的整体布局,同时能够保证每个目标的生成质量和各个目标之间的自然融合。
- 算法细节:
- 该算法主要包括四个主要模块模块:
- Layout Embedding: 对每个目标的包围框的坐标和类别信息进行编码
- Layout Fusion Module: 融合所有目标的信息,保证最终生成结果的自然性
- Image-Layout Fusion Module: 使用Object-aware Cross Attention融合图像和Layout信息
- Layout conditional diffusion moudel: 使用classifier-free guidance技术,将Layout作为条件控制Diffusion过程
- 使用比较全的评测指标验证模型效果:
- FID和Inception Score:生成任务重常用的指标,评估生成质量
- Diversity Score:使用LPIPS计算两个生成图像之间的差异性
- Classification Score: 将每个目标crop出来进行分类计算生成目标的准确性
- YOLOScore: 使用YOLO对生成图像进行目标检测并使用mAP指标可以作为layout控制准确性
- 该算法主要包括四个主要模块模块:
✅2023.7.31补充:
基于Layout控制Diffusion生成结果的论文还挺多,可以参考下面的额链接:
总结
上述文生图的各种控制生成算法使得文生图技术有了更强的落地和应用的可能性,而且效果也确实都很惊人。