
DALLE系列
DALLE
《Zero-Shot Text-to-Image Generation》
DALL·E的名字是为了向艺术家萨尔瓦多·达利和皮克斯的机器人WALL-E致敬
DALLE-2
《Hierarchical Text-Conditional Image Generation with CLIP Latents》
DALLE-3
《Improving Image Generation with Better Captions》
GLIDE
《GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models》

算法流程:本篇论文并没有做过多的算法创新,更多的是验证性和实验工程相关的内容,其提出可以用文本当做条件去合成、控制和编辑图像。
算法细节:
比较了两种文本引导图像生成的方式:
Classifier-Free-Guidance:
虽然该技术介绍过很多次,但是为了保证相对独立性,这里还是把本篇文章下的CFG公式写一下:
其中这里的 专门代表文本条件。 CLIP Guidance:
其中 分别表示从CLIP提取的图像特征和文本特征,两者相乘表示图像 和文本 之间的语义相似度 (其实就是CLIP中的相似矩阵),然后本文使用这个相似矩阵对 计算梯度再和预测的均值 、方差 得到最终的结果,这里其实和Classifier-Guidance是一样的思路,只是计算原本是使用专门的分类器计算梯度,这里换成了CLIP。 作者通过实验证明仍然还是Classifier-Free-Guidance效果好一点,原文的说法是:
We hypothesize that CLIP guidance is finding adversarial examples for the evaluation CLIP model, rather than actually outperforming classifier-free guidance when it comes to matching the prompt.(简单说就是图文匹配度不够)而且CLIP Guidance方式有一个致命的缺点就是其和Classifier-Guidance一样都是需要专门在含噪声的图上训练
。所以就是一句话:用Classifier-Free Guidance就完事了!
模型构成:64x64大小的基于文本控制的的Diffusion(参数量3.5B),256x256的文本控制的上采样Diffusion(参数量1.5B)。其中对于CLIP Guidance作者训练了一个在64x64噪声图上的CLIP模型。
算法应用:基本文生图+图像Inpainting
Imagen
《Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding》
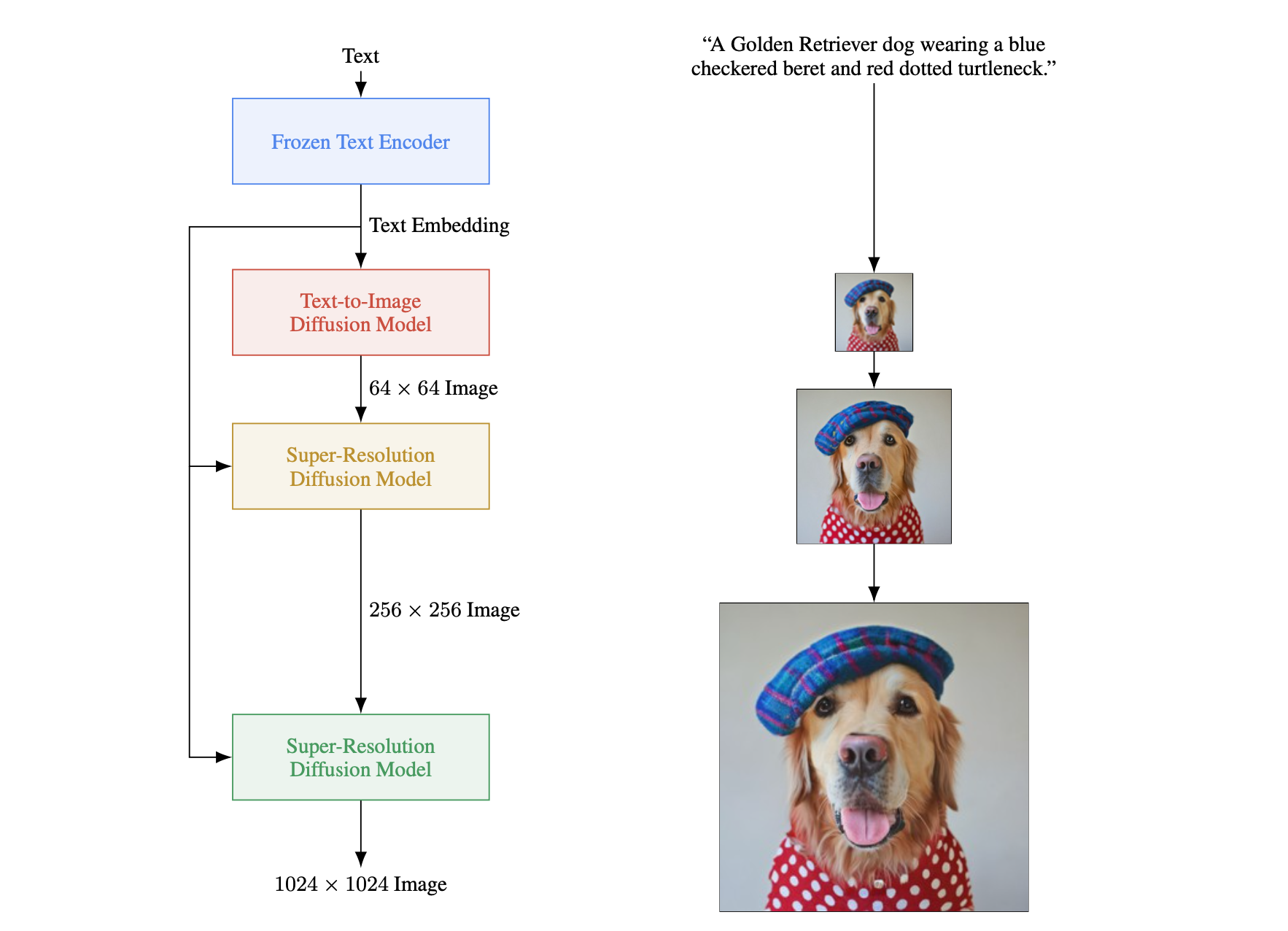
Imagen是谷歌的工作,其相比同时期的其他方案(如DALL-E2、GLIDE、DDIM、VQ-GAN等)要好,主要得益于其在大语料下的预训练语言模型-T5对文本的强大的编码能力以及Diffusion本身在高保真图上的优质效果。另外本文的另一个贡献还是提出一个text-to-image的benchmark,为后来的文生图模型提供了一个评判基准数据集。
算法流程: 在使用预训练好的文本编码模型(T5)提取文本Embedding后,该算法的整体流程包含三个部分:一个文生图Diffusion模型(文本到
图像)和两个超分Diffusion模型(从 超分到 再到 ),这三个模型同时都接收文本条件进行控制。 算法细节:
Text Encoder:文章对比了三种文本编码器:Bert(参数量0.11B)、T5(参数量11B)、CLIP(参数量63M),最终实验下来发现11B的T5效果更好。
Diffusion生成部分:该部分是Imagen中文生图的核心部分,负责生成
大小的图像,同时也使用了Classifier-Free Guidance技术进行文本控制,不过不同于GLIDE的事,这里unconditional部分直接不指定空字符串: Diffusion超分部分:该部分包含两个超分网络,负责将生成的
大小的图像先超分到 ,再超分到 ,这两个超分模块能够避免生成模块直接生成超清大图,减小生成部分的压力,这部分使用的网路是在原本U-Net基础上做了一些改动,称为Efficient-UNet,具体改动点如下: - 对低分辨率使用更多的残差快,将参数量转移到低分辨率上。这因为低分辨率有着更多的通道数,这能在不夸张地增加计算量和显存的情况下,提升模型的容量。
- 对跳跃连接进行缩放
- 反转上/下采样层和卷积层的顺序。在标准UNet中,下采样层在卷积后,上采样层在卷积之前,这里对这两个均做了反转,速度提升了且并未发现效果下降。
此外,Efficient-UNet去除了Self-Attention模块,保留文本cross-attention模块。
总之以上本文提出的Efficient-UNet更简单、收敛更快、效率更高,更具体的细节可以看论文。
其他tricks:动态阈值、噪声增强等。
DrawBench:提出了包含颜色、数数、文本等11个类别的的prompt模板,验证文生图模型在这些末班上的图像生成效果
Muse
《Muse: Text-To-Image Generation via Masked Generative Transformers》
Stable Diffusion系列
Stable Diffusion1.x
《High-Resolution Image Synthesis With Latent Diffusion Models》
【论文 】【代码-V1.5 Git】【代码-V1.5 HuggingFace】【代码-V2.0 Git】【代码-V2.0 HuggingFace】
Stable Diffusion(下面简称SD模型)是CompVis、Stability AI和LAION等公司研发的一个文生图模型,可以说Stable Diffusion的优秀效果和开源精神完全引爆了AIGC的图像领域!!所以如果想要参与AIGC创作,那么Stable Duffusion是必须要了解的!!!该算法核心就是Latent Diffusion这篇论文:
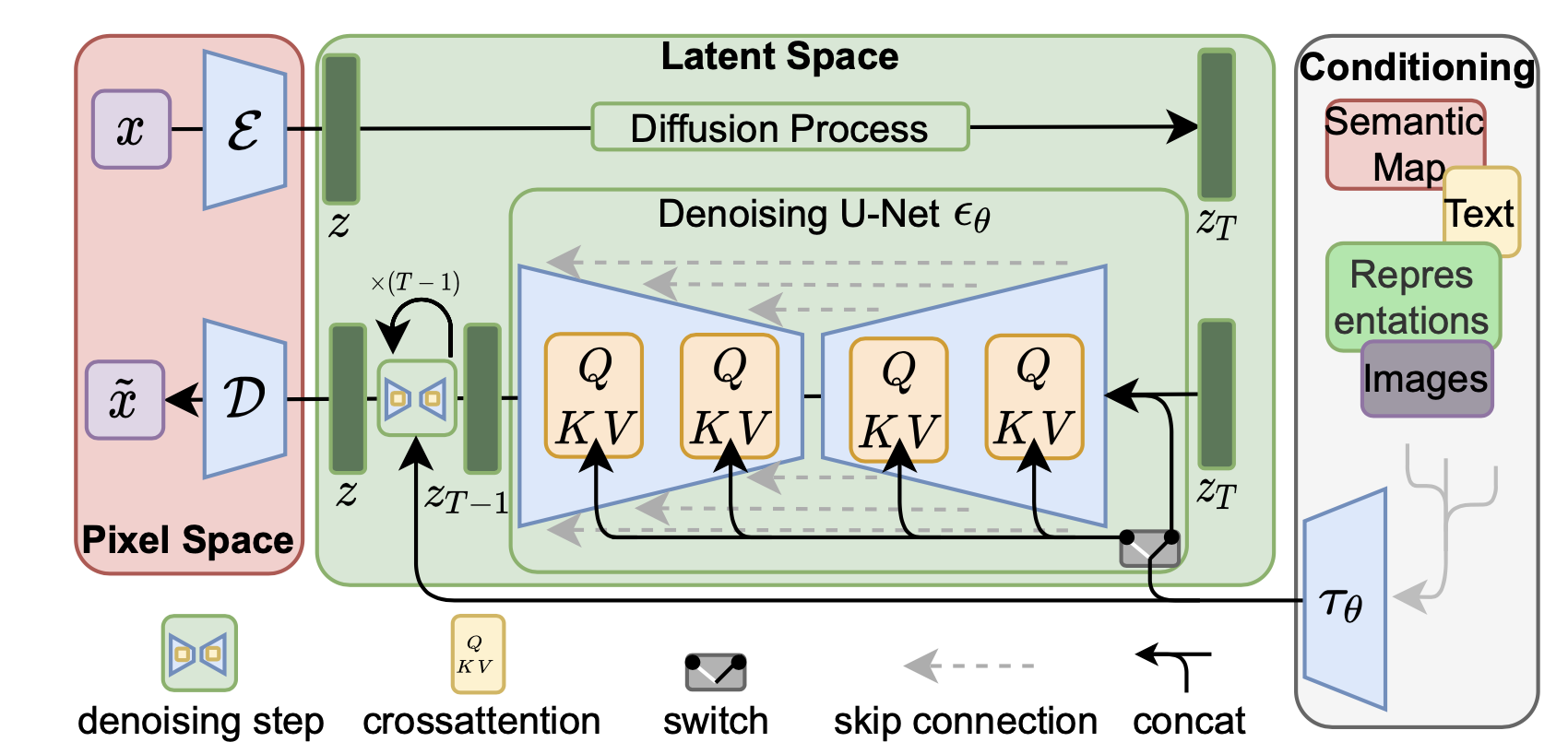
Stable Diffusion模型主要包含三个模块:
AutoEncoder:感知压缩网络,将图像压缩至维度更小的latent空间模型参数大小为84M
CLIP text encoder:将文本prompt转换成text embedding形式,采用CLIP ViT-L/14,模型大小为123M
UNet:Diffusion模块的去噪网络,参数大小为860M
所以SD模型的总参数量约为1B。(这里是Stable Diffusion的参数量,和原始论文中Latent Diffusion的参数量:1.45B还是有点区别的)。Latent Diffusion算法创新性地提出了在latent空间进行扩散操作,起相比较于之前DDPM之类的在图像空间做Diffusion的算法相比,在latent空间能够极大程度减少计算量,提高训练和推理效率。
Auto Encoder
除了采用L1重建损失外,还增加了感知损失(perceptual loss,即LPIPS损失)以及基于Patch的对抗训练,同时为了防止得到中间latent的标准差过大,尝试了两种正则化方法:第一种是KL-reg,类似VAE增加一个latent和标准正态分布的KL loss;第二种是VQ-reg,引入一个VQ (vector quantization)层,此时的Autoencoder可以看成是一个VQ-GAN,不过VQ层是在Decoder模块中,这里VQ的CodeBook采样较高的维度(8192)来降低正则化对重建效果的影响。最终采用KL-reg。
这里要明确的一点是,SD中感知压缩这部分用的是AutoEncoder,并非是VAE!即Encoder部分输出的就直接是维度更低的特征图而并非是VAE中的均值和方差,因为这部分主要的目的还是降维和重建,并非为了生成。
AutoEncoder对图像输入进行感知压缩,可以看到过小的压缩比例(比如1和2)导致模型收敛速度慢,扩散模型需要较长的学习;而过大的压缩比例导致数据损失大,生成质量较差。压缩比例在4~16取得相对较好的效果,论文中采用的是8倍压缩(即特征图尺寸从
) AutoEncoder是单独训练好的,其在后续Diffuison训练是完全固定住的!具体地,SD的Diffusion模块在训练过程只需要Encoder部分,而在推理过程只需要Decoder部分。
AutoEncoder既然是感知压缩的,那么不管是压缩比例多少最后的重建结果都是有损的,会存在轻微的变形(比如比如文字和人脸的畸变),为了改善这种畸变,Stability.Ai在发布SD 2.0时同时发布了两个在LAION子数据集上精调的AutoEncoder,注意这里只精调Autoencoder的Decoder部分
补充知识【选读】:由于SD采用的autoencoder是基于KL-reg的,所以这个AutoEncoder在编码图像时其实得到的是一个高斯分布的均值和方差,然后通过调用sample方法来采样一个具体的latent。但是由于KL-reg的权重系数非常小,实际得到Latent的标准差还是比较大的,这篇论文中提出了一种rescaling方法:首先计算出第一个batch数据中的了atent的标准差
,然后采用 的系数来缩放 latent,这样就尽量保证latent的标准差接近1,然后扩散模型也是应用在缩放后的latent上,在解码时只需要将生成的latent除以 ,然后再送入AutoEncoder的Decoder即可。对于SD所使用的AutoEncoder,这个rescaling系数为0.18215。
Text Encoder
- SD采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。
- 值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入prompt的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。在训练SD的过程中,CLIP text encoder模型是冻结的。在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
Unet
SD的扩散模型是一个860M的UNet网络,输入和输出latent的尺寸均为64x64x4。
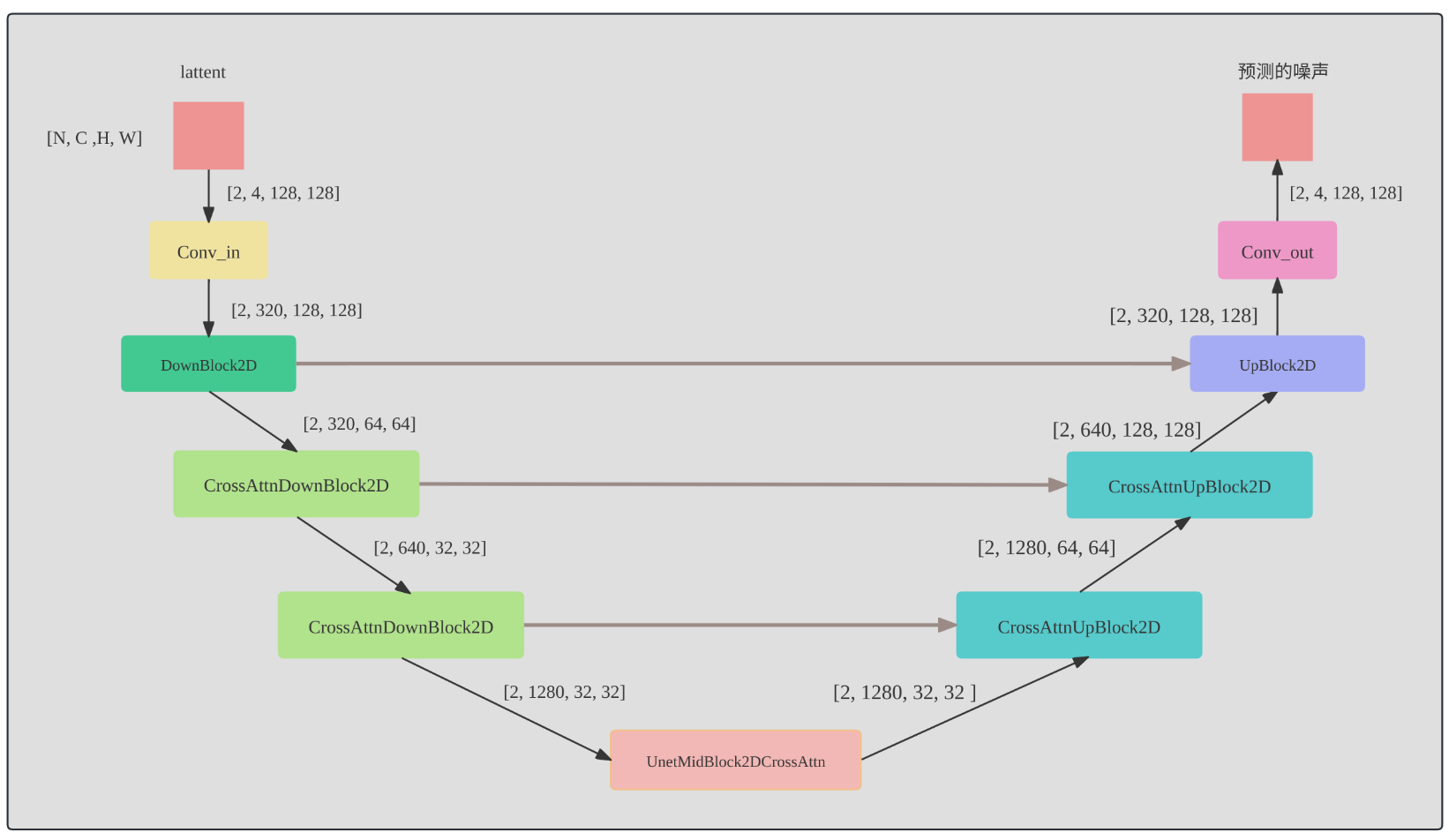
encoder部分包括3个CrossAttnDownBlock2D模块和1个DownBlock2D模块,
decoder部分包括1个UpBlock2D模块和3个CrossAttnUpBlock2D模块,
中间还有一个UNetMidBlock2DCrossAttn模块。encoder和decoder两个部分是完全对应的,中间存在skip connection。
3个CrossAttnDownBlock2D模块最后均有一个2倍的downsample操作,而DownBlock2D模块是不包含下采样的。
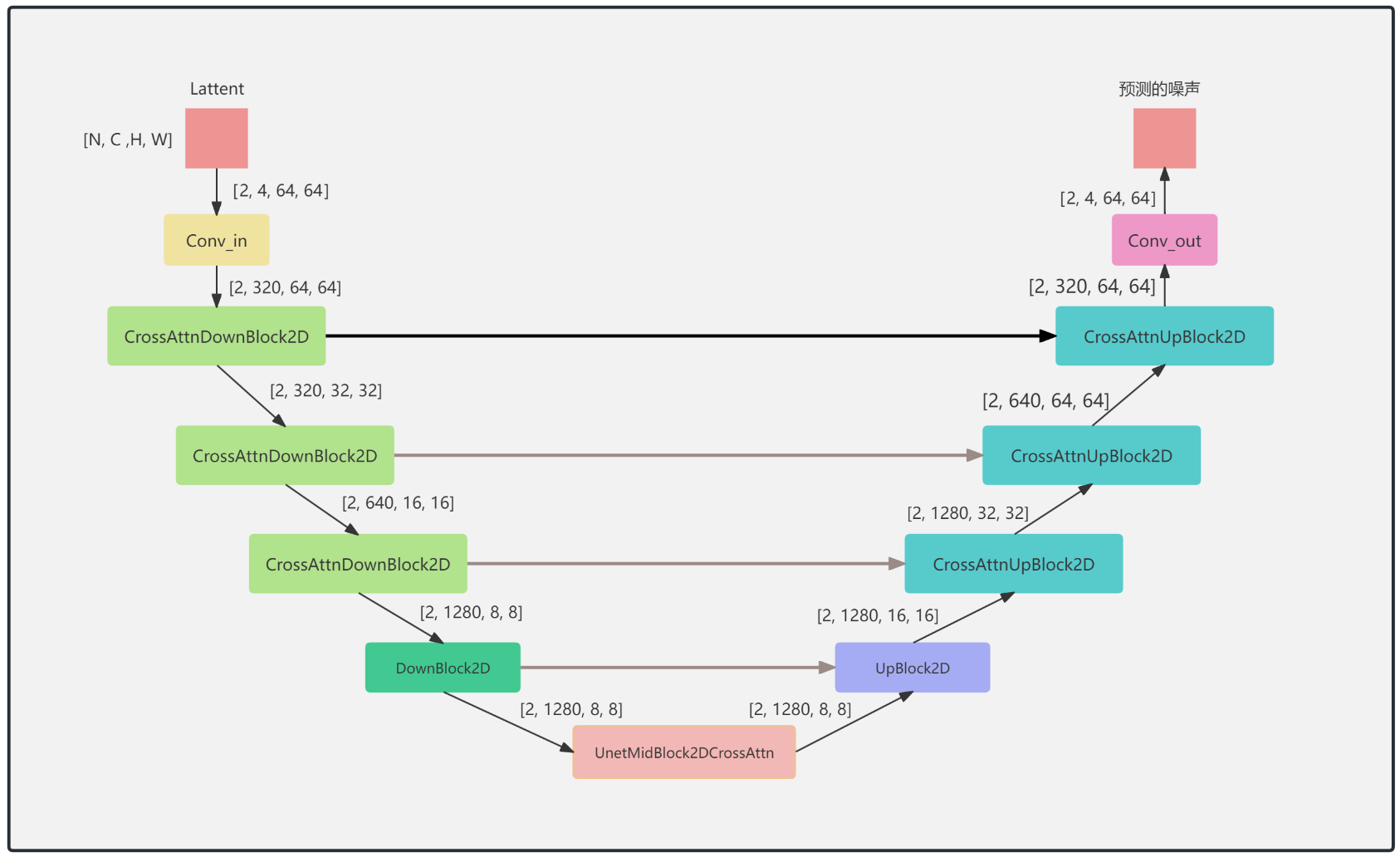
其中每个CrossAttnDownBlock2D的结构如下:
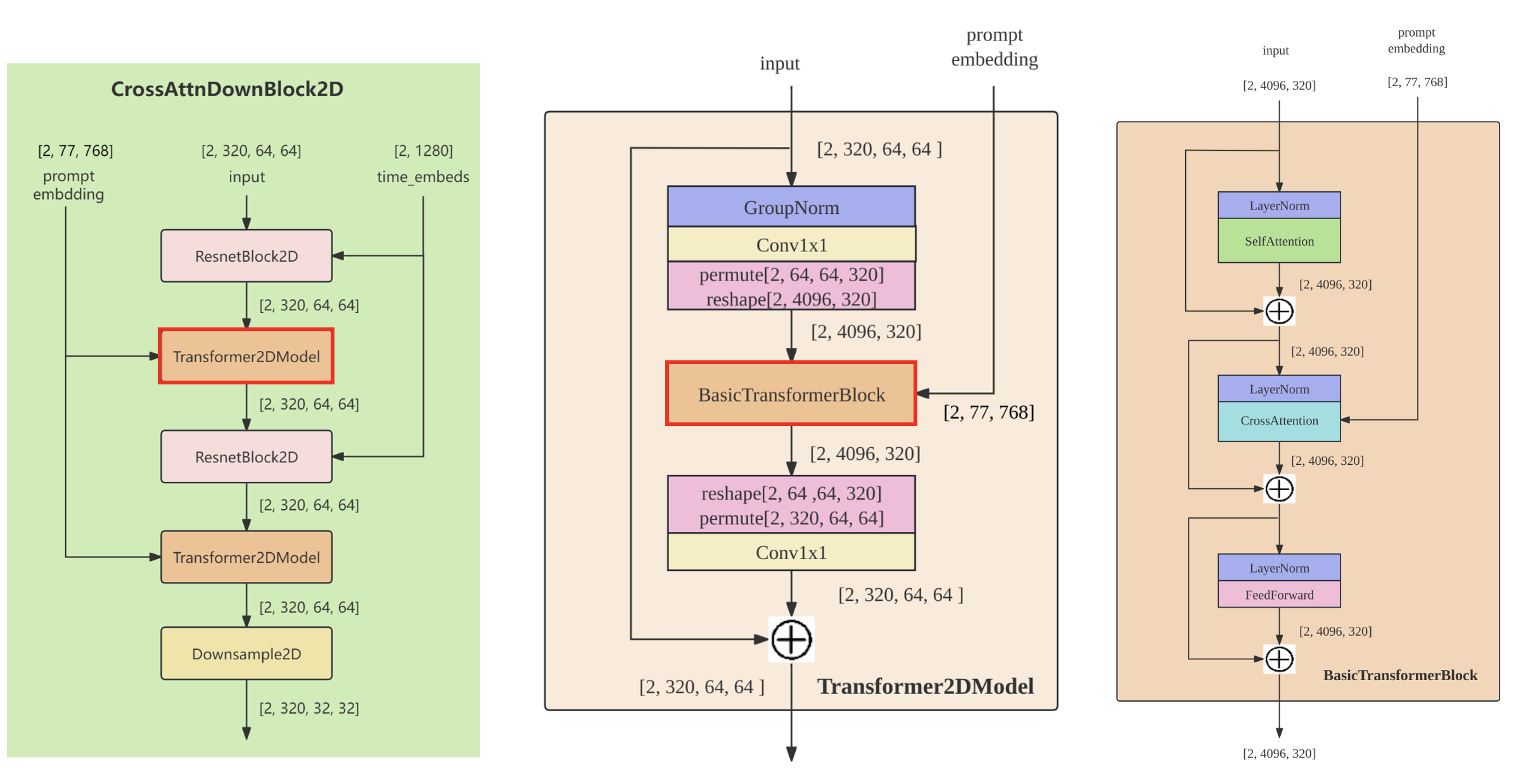
即每个CrossAttnDownBlock2D包含两组[ResnetBlock2D,Transformer2DModel],而Transformer2DModel就是包含[SelfAttention, FeedForwardNetwork, CrossAttenion]。
从CLIP获取的Text Condition信息则通过CrossAttention模块嵌入进来,其中Attention的Query是UNet的中间特征,而Key和Value则是Text Embeddings。
训练
训练数据:SD在LAION 2B-en数据集上训练的,它是LAION-5B数据集的一个子集,更具体的说它是LAION-5B中文本为英文的数据集。Laion-5B数据集是从网页数据Common Crawl中筛选出来的“图像-文本”成对数据集,包含5.85B的"图像-文本"对,其中文本为英文的数据量为2.32B,即LAION 2B-en数据集。
- LAION 2B-en数据集的基本信息统计:图片的宽高均在256以上的样本量为1324M,在512以上的样本量为488M,而在1024以上的样本为76M;文本的平均长度为67。
训练过程:训练主要分为两个阶段:1.训练一个AutoEncoder;2.在latent空间训练duffusion去噪网络。
训练超参(从该网址抄过来mark一下):采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs)。单卡的训练batch size为2,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x2=2048。训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间,文档上只说了用了150,000小时,这个应该是A100卡时,如果按照256卡A100来算的话,那么大约需要训练25天左右。
条件注入:SD允许接收CLIP的文本embedding或者图像作为引导控制生成结果,具体控制方法则是通过Cross Attention的方式送入UNet中:
其中: 以上 表示UNet网络展开后的中间特征, 则表示提取的条件特征(该条件 可以是CLIP提取的文本Embedding,也可以是图像、语义分割图等,每种特征有专门的编码器)。上式的 均表示可学习的映射矩阵用于将具体的特征转换到Q、K、V。 损失函数:SD在固定好AutoEncoder和CLIP Encoder的权重后,整个训练过程就是在优化UNet网络的权重,其损失函数在原DDPM的损失上做了两个改动:
- 红色改动:即LDM的核心,在latent空间进行扩散和去噪,使用AutoEncoder的编码器提取latent
- 蓝色改动:添加了条件控制,如文本、分割图等
在具体训练的时候使用了Classifier-Free-Guidance保证模型的条件控制能力,具体做法就是:在使用上述损失函数训练带条件扩散模型的同时也训练一个无条件的扩散模型(只需要随机概率10%将条件置空就行,比如文本设置为空字符串),然后在推理的时候使用带条件的噪声
进行去噪: 上面的guidance scale可以看成是引导权重,利用该参数对有条件和无条件的噪声做插值,或者从另一个角度来看改写上面公式: 即可以看成对无条件和有条件噪声作差作为条件的方向,然后将无条件的噪声沿着这个方向移动作为最终的噪声,其实有点类似于InterFaceGAN中利用latent空间差向量进行属性编辑。 不同的SD版本:
SD的训练是多阶段的(先在256x256尺寸上预训练,然后在512x512尺寸上精调),不同的阶段产生了不同的版本(直接从该网址抄过来mark一下):
- SD v1.1:在laion2B-en数据集上以256x256大小数据(共1324M)训练237,000步;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
- SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
- SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
- SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
- SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数,该版本也是目前使用最为广泛的SD模型。
SD v1.3、SD v1.4和SD v1.5其实是以SD v1.2为起点在improved_aesthetics_5plus数据集上采用CFG训练过程中的不同checkpoints,目前最常用的版本是SD v1.4和SD v1.5
我的理解是在SD1.1和SD1.2虽然没有用CFG进行条件控制,但是其内部的Cross-Attention机制已经做了条件控制的事情,只是效果可能没有显式的CFG效果好~
评估指标:
- FID(越低越好):衡量生成图像的逼真度
- CLIP score(越大越好):生成的图像与输入文本的一致性
当CFG的gudiance scale参数设置不同时,FID和CLIP score会随之发生变化,越大则CLIP score但是FID也会升高,SD模型默认采用7。
算法应用:
- text-2-image(文生图)
- layout-2-image或segmentation-2-image
- 图像超分
- Inpainting
参考
SDXL
《SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis》
✅2023.10.7补充
【主页】【论文】【代码Git】【代码HuggingFace】
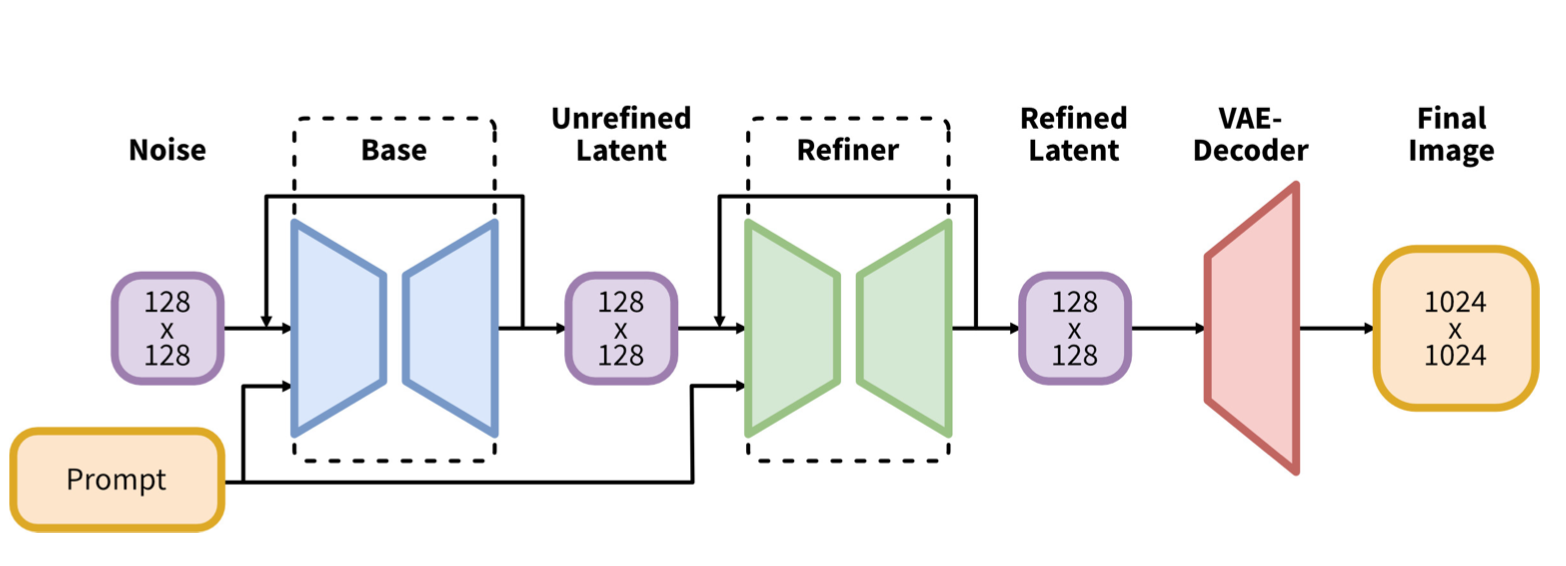
Stable Diffusion XL是一个二阶段的cascade 扩散模型,其相比之前的SD1.x和SD2.x在生成质量上有巨大的提升,其整体结构包括Base模型和Refiner模型。
相比较之前的SD模型,SDXL在VAE、U-Net、Text Encoder均有比较大的改动:
改善的VAE:更大的训练batch_size,更强的重构能力。
更大的U-Net结构:使用更多的Transformer Blocks (即self-attention 和 cross=attention),是之前SD的U-Net的3倍(
)。增强特征提取和融合能力。 更多的Text Encoder:用了两个Text Encoder(OpenCLIP ViT-bigG 和 CLIP ViT-L,共817M),而SD1.5只用了CLIP ViT-L/14(参数量123M)。提升文本理解和匹配能力。
创新的Refiner模块:新提出一个单独的基于Latent的Refiner模型,来提升图像的精细化程度,本质上是一个图生图的过程。
此外也用了其他训练技巧:
- 添加图像尺寸条件-Conditioning the Model on Image Size
- 添加图像裁剪参数条件-Conditioning the Model on Cropping Parameters
- 多尺度(宽高比)训练-Multi-Aspect Training
下面就一个个来介绍:
Auto Encoder
SDXL的AutoEncoderh和原SD没有额外区别,而是基于同样的架构采用了更大的batch size(从9提成到256 )重新训练,同时对模型的参数采用了EMA(指数移动平均),从而改善生成图片的局部和高频细节,此外其重建能力也相比之前的VAE有比较大的提升:
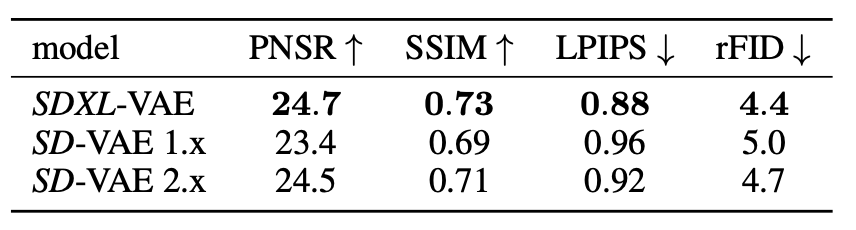
上表中的三个VAE模型的模型结构完全一样:
- SD-VAE 2.x在SD-VAE 1.x的基础上冻住encoder权重并重新微调了decoder部分【所以两者的latent分布是一样的,两个VAE模型是都可以用在SD 1.x和SD 2.x上的】
- SDXL-VAE是完全重新训练的。【它的latent分布发生了改变,不可以将SDXL-VAE应用在SD 1.x和SD 2.x上】
- 惯例在将latent送入扩散模型之前,我们要对latent进行缩放来使得latent的标准差尽量为1,由于权重发生了改变,所以SDXL-VAE的缩放系数也和之前不同(之前是0.18215,SDXL_VAE是0.13025)。
Text Encoder
| SDXL | SD1.x | SD2.x | |
|---|---|---|---|
| 类型 | CLIP ViT-L/14 & OpenCLIP ViT-bigG | CLIP ViT-L/14 | OpenCLIP ViT-H/14 |
| 参数量 | 123M+694M=817M | 123M | 354M |
| 特征维度 | 768+1280=2048 | 768 | 1024 |
此外,SDXL还提取了OpenCLIP ViT-bigG的 pooled text embedding(用于CLIP对比学习所使用的特征),将其映射到time embedding的维度并与之相加。
UNet
SDXL的UNet相比较之前有两点改动:
从4 stage变成3 stage:
SDXL只用了3个stage【即Conv_in后的模块】,只进行了两次2倍下采样,而之前的SD使用4个stage,包含3个2倍下采样。SDXL的网络宽度(channels)相比之前的版本并没有改变,3个stage的特征channels分别是320、640和1280。
增加了Transformer2DModel数量:
回顾下SD1.5中CrossAttnDownBlock2D模块,其包含两组[ResnetBlock2D,Transformer2DModel]和一个DownSample2D,而其中Transformer2DModel包含一组[SelfAttention, FeedForwardNetwork, CrossAttenion]。
SDXL的第1个stage采用的是普通的DownBlock2D,而不是采用基于attention的CrossAttnDownBlock2D。
SDXL的第2个和第3个stage的Transformer2DModel分别从原本SD1.5的1个提升到了2个和10个,以第2 stage(即第1个CrossAttnDownBlock2D)为例,其结构如下:
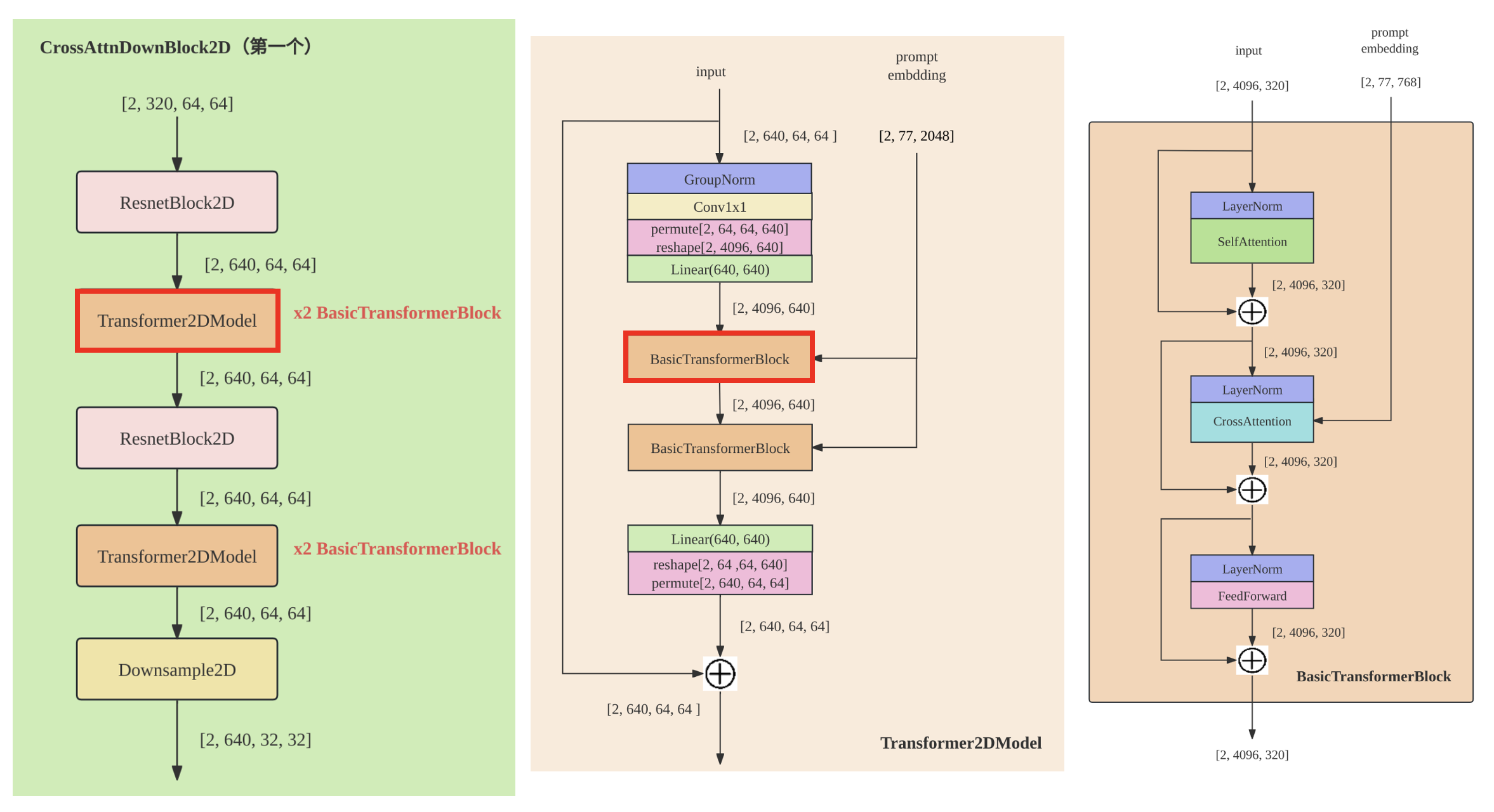
SDXL中间的MidBlock2DCrossAttn的transformer blocks数量也设置为10
这也是为什么SDXL的stage少了但是其参数量反而增加的缘故,具体参数量比较如下:

Refiner
该模块是 SDXL中提出来专门用于进一步提升生成质量的模块,其本质是一个图生图的过程,具体的训练和推理过程如下:
使用高质量和高分辨率的图像在相同的隐空间(latent space)中又训练了一个单独的LDM(通常称之前训练的LDM是base模型,现在训练的LDM是refiner模型)。
训练:Refiner模块采用和base模型同样的VAE,其接受base模型降噪后的latent,并再添加少量的noise(比如只在前200 timesteps)作为输入进行训练。
推理:noise先经过base模型进行去噪得到图像 latent,然后添加少量noise后再送入refiner模块进行最终去噪得到最终的latent后送到VAE的decoder得到最终的图像,其接受的prompt和base模型是一样的。
结构:
Refiner模块也同样是采用U-Net结构,但是其和base模型稍有不同,而且其参数量也稍微小一点,有2.3B。
- Refiner model采用4个stage,第一个stage采用没有 Attention的DownBlock2D,通道数为384。
- Attention模块中transformer block数量均设置为4
- 其Text encoder只使用了OpenCLIP ViT-bigG,也是提取倒数第二层特征以及pooled text embed.
图像尺寸条件
之前原始SD1.x或SD2.x存在的问题:
均是先在256x256的图像上预训练,然后再在512x512图像上继续训练,但是这个训练过程对于训练数据的分辨率是比较严格的,为了保证每个阶段使用对应的分辨率进行训练,通常有两个做法:
- 直接舍弃小于目标分辨率的图像: SDXL论文中统计了如果按照这种方法,那么在第一阶段就要舍弃大量长或宽小于256的图像【大约占整个数据集39%】,这会极大减少训练数据,对训练效果也会产生比较大的影响。
- 使用upscale技术:对分辨率小的图像直接upscale到指定的分辨率。但是这种方法也会导致产生一些artifacts或者模糊问题。
为了保证训练不受数据集图像尺寸的限制,那么自然而然想法就是我们能不能就保证图像原始的分辨率?这样我们就能有多少数据就用多少数据训练。
反正VAE、U-Net本来就是image2image而且全卷积的,对分辨率也严格没有要求。
SDXL则使用了图像尺寸条件化方法【Conditioning the Model on Image Size】:
核心思想:将图像的原始尺寸
作为控制条件嵌入UNet模型中 嵌入方式:height和width分别用傅里叶特征编码,然后将特征concat后加在Time Embedding上;
好处:相当于额外引入了一个控制条件,让模型学到了图像分辨率参数。在训练过程中我们可以不resize图像、不破坏原始图像的信息;在推理时,我们只需要指定目标分辨率而保证生成指定分辨率的图像。
图像裁剪参数条件
之前原始SD1.x或SD2.x存在的问题:
受限于Pytorch的训练机制:在一个batch中的图像数据得是相同的尺寸,所以之前SD1.x或SD2.x等一些列工作通常会这么做: 先将短边resize到指定的尺寸(如512),然后沿着长边随机裁剪。
上面这么做就会导致训练集中主体有可能被随机裁剪,进而就会导致训练好的模型最终生成的图像中一些主体会被截断(比如动物肢体不完整等)
为了保证图像不被随机裁剪以保证图像的完整性,SDXL提出了图像裁剪参数条件【Conditioning the Model on Cropping Parameters】:
- 核心思想:将训练过程中裁剪的左上顶点坐标作为额外的条件注入到UNet模型中
- 嵌入方式:像上面图像尺寸一样,将裁剪信息
通过傅里叶编码后concat在Time Embedding上 - 好处:能够让模型间接知道当前的数据是不是已经被裁剪了,相当于明确告诉模型我给你的数据就是完整的或者不完整的。在推理的时候,我们传入这个定点坐标为(0,0)给到模型就行,相当于告诉模型我现在要生成一个主体完整没有缺失的图像。
SDXL在训练过程中,可以将上述两种条件(size and crop conditioning)结合在一起使用:首先在通道维度将两者特征向量连接,然后加到Time Embedding上面,伪代码如下:

多尺度(宽高比)训练
之前原始SD1.x或SD2.x存在的问题:
模型训练尺寸比例多是1:1,比如512x125或者1024x1024,但其实这个并不合理,因为不同的宽高比例其实才有着更广泛的应用范围,比如16:9。
为了保证模型能够生成不同宽高比的图像,SDXL提出了多尺度(宽高比)训练【Multi Aspect Training,该方法主要用在微调阶段[即使用上述size和crop条件训练好的模型之后]:
核心思想:借鉴NovelAI所提出的方案,将图像按照不同的长宽比划分到不同的buckets上(按照最近邻原则),并且将宽高比信息注入到模型中。注意每个bucket的图像尺寸通常都是64的倍数,如512x1948、1792x576等,且总像素书都基本接近 1024x1024。
嵌入方式:提取buckets 尺寸
的傅里叶特征然后和size和crop一样注入到模型中。 训练过程:每个trainging step可以在不同的buckets之间切换,每次数据都是从相同的bucket中采样得到。
其他:
- 该方法让模型能够显示地学习到多尺度(或aspect ratio)
- 在该多尺度微调阶段,SDXL依然采用前面所说的size and crop conditioning,虽然crop conditioning和多尺度微调是互补方案,但是这里也依然保持这个条件注入。经过多尺度微调后,SDXL就可以生成不同aspect ratio的图像,SDXL默认生成1024x1024的图像。
所有条件注入
到此为止我们回顾下有哪些东西要加到time embedding?
- OpenCLIP ViT-bigG的 pooled text embedding
- Image Size
- Cropping Parameters
- Aspect Ratios
训练
SDXL训练是一个多阶段过程:
- Base模型预训练:在内部的数据集上训练,使用255x256分辨率的图像,batch size设置成2048,训练60万个step,这里同时使用了上文所述的size和crop conditioning。
- 在512 x 512 分辨率的图像上继续训练20万step
- 最后在图像总分辨率约为1024x1024的图片上进行多尺度训练,这里训练同时使用了noise-offset技巧
- 技术报告中并未涉及Refiner模块的训练过程,只是提到该模块有助于对于提升图像的细质量。
这里使用的Noise-offset其实是来自这篇Blog,该技术主要是用来解决生成过量或者过暗的图像的。
问题描述:让SD生成过量和过暗的图像时,其总是偏向于生成中间色度0.5(全白为1,全黑为0)
问题来源:该问题主要因为在加噪的过程,图像从
开始加噪,最终并没有变成完全随机的噪声(在加噪次数足够多的情况下,确实会变成完全随机的噪声,但是整整加噪可能只有1000部左右)。这使得训练过程中是有偏差的,但是测试过程中又是从一个完全随机噪音开始生成的,这种不一致就会导致这种问题。 问题解决:训练过程中给采用的噪音加上一定的offset即可,如下:
noise = torch.randn_like(latents)
noise += args.noise_offset * torch.randn((*latents.shape[:2], 1, 1), device=latents.device)局限性
- 生成复杂结构的物体(如人手)仍然不够好。
- 还是无法达到完美的逼真度,如微妙的灯光效果或微小的纹理变化。
- 可能会无意中引入社会和种族偏见。
- 包含多个对象或主题的情况下,模型可能会出现一种称为“概念混淆(concept bleeding)”的现象(即不同视觉元素的合并或重叠)。
- 生成清晰且比较长的文字仍然比较困难,生成的文本可能包含随机字符。
参考:
- https://blog.csdn.net/weixin_47748259/article/details/135541372
- https://mp.weixin.qq.com/s/9pwsvPj5jA3h0RMGeIO7-g
- https://blog.csdn.net/xd_wjc/article/details/134530784
Stable Diffusion 3
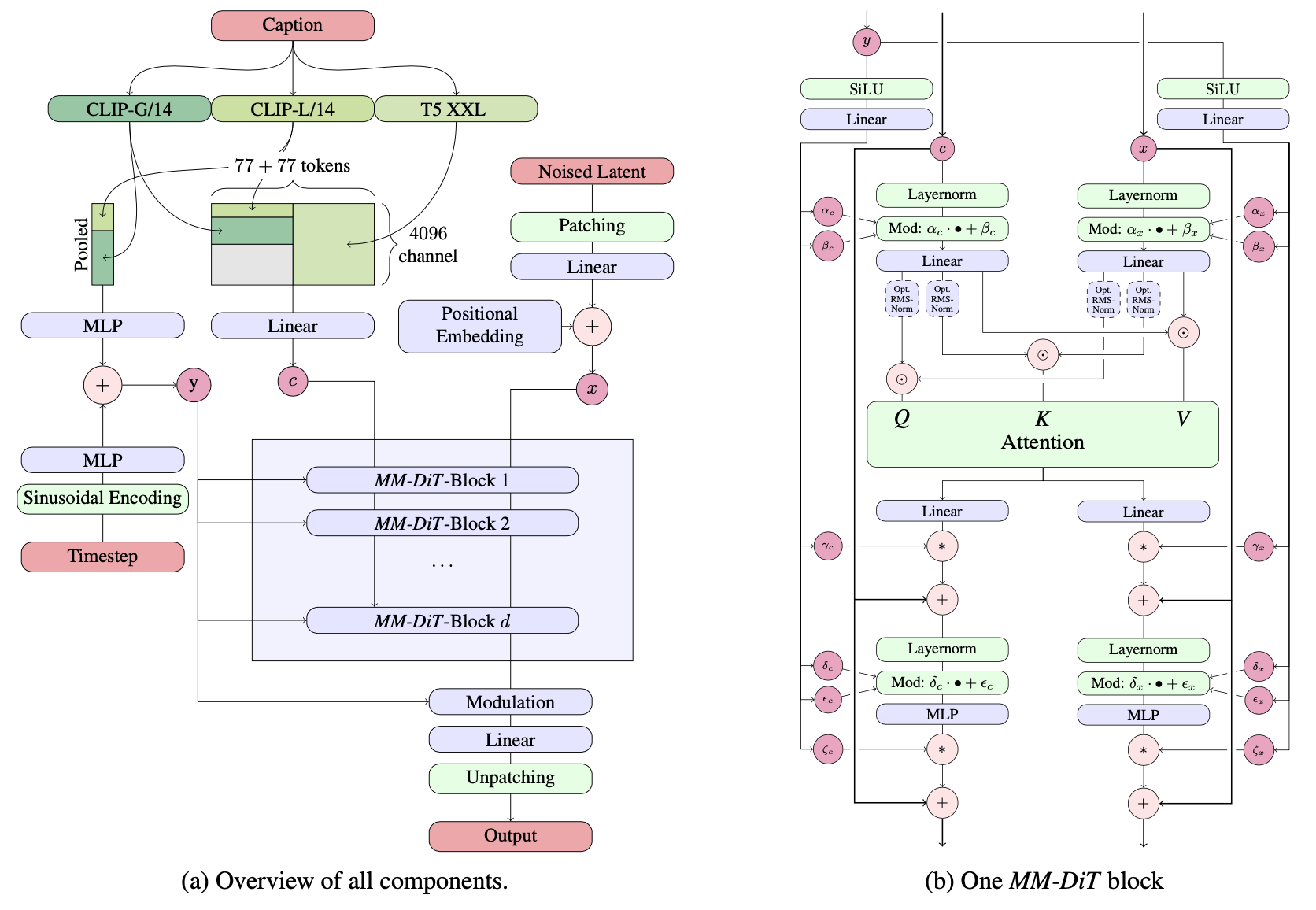
《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》
PixArt系列
PixArt-alpha
《PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis》
【主页】【论文】【代码】【HuggingFace】
PixArt-delta
《PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models》
【主页】【论文】【代码】【HuggingFace】
PixArt-sigma
《PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation》
【主页】【论文】【代码】【HuggingFace】
Playground系列
Playground v2.5
《Playground v2.5: Three insights towards enhancing aesthetic quality in text-to-image generation》
【主页】【论文】【HuggingFace】
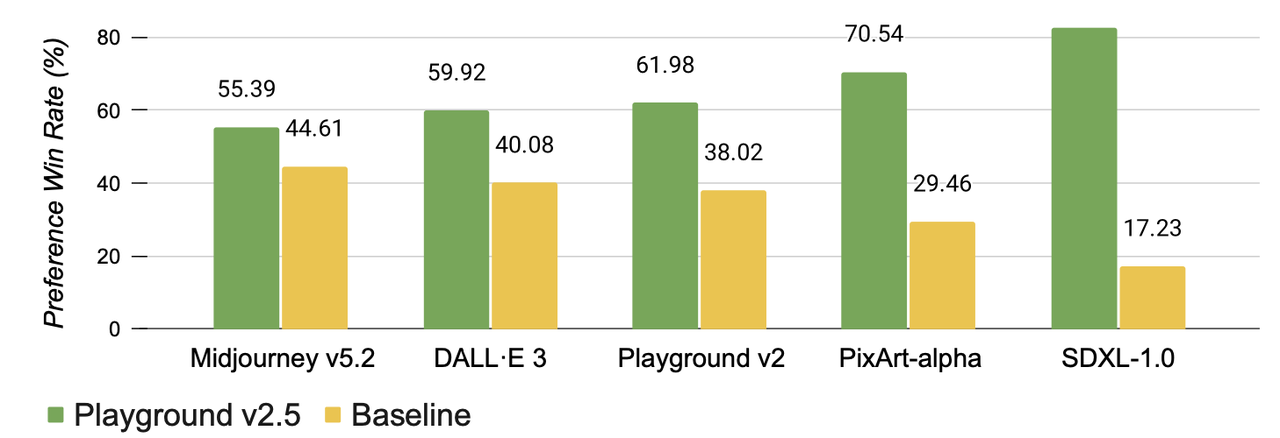
算法流程:本论文未介绍具体的模型框架和训练细节,更多像是一个简略的技术报告,从三个维度来提升文生图的质量:鲜艳颜色和对比度、多分辨率生成、人像细节。最终通过user study的方式表明新提出的Playground v2.5战胜了之前各种先进的开源和闭源文生图模型,诸如Midjourney 5.2、DALL·E 3、Playground v2、PIXART-α和SDXL。
算法细节:
- 提升颜色和对比度(enhancing color and contrast)
【之前模型存在的问题】
SDXL仍然难以生成纯色的图片或者纯色背景的图片(具体可见之前的博客),而这篇论文指出该问题的主要原因在于:在diffusion扩散过程中,即使离散的噪声水平达到最大值,但是stable diffusion的信噪比仍然太高了(即不是完全的纯噪声)。虽然SDXL和PlaygroundV2.5的前一个版本(Playground v2)中都尝试使用了noise-offset的方式来缓解这个问题,但是该问题仍然没有被彻底解决。
【本论文的解决方法】
PlaygroundV2.5则使用了EDM算法来解决这个问题,该算法有两个明显的优点:
与Zero Terminal SNR一样,EDM在最后一个去噪步骤达到了接近于零的信噪比。
EDM采用第一性原理方法来设计训练和采样过程,以及UNet的预处理。这能够帮助获得更好的图像质量和更快的模型收敛速度。
想更详细了解该算法的公式和细节可去读原论文。同时playgroundv2.5还受到Simple diffusion启发,在对高分辨率图像进行训练时将noise schedule向整体噪声更大的方向倾斜。
【达到的效果】
在与SDXL和PlaygroundV2对比,本文的PlaygroundV2.5能够根据 Prompt生成完全纯色的图像和背景,同时在颜色的鲜艳度和对比度上也有很大的提升。

- 生成多种宽高比图像(Generation Across Multiple Aspect
Ratios)
【之前模型存在的问题】
之前Diffusion图像生成模型普遍在方图上进行训练,理论上在推理时是适用于任何输入分辨率,即使它没有在特定分辨率上进行训练,这主要是得益于卷积神经网络的转移不变性。可是正如NovelAI指出的那样,在实践中当仅在方形图像上训练时,扩散模型并不能很好地推广到其他宽高比图像的生成。
NovelAI和SDXL模型为了解决该问题则提出了桶采样(Bucketed Sampling),即具有相近宽高比的图像被放在一个batch中送入模型,此外SDXL为了让模型更好地感知输入图像的分辨率,还额外输入了原图和目标图的size,有兴趣的也可以见我之前的博客。
然而上述的桶采样也并非能完美解决该问题,主要SDXL数据集中宽高比桶的分布仍然是不平衡的,即数据集的大多数图像仍然都是方形的,所以最终推理时非方形图像仍然比方形的质量低得多。
【本论文的解决方法】
PlaygroundV2.5总体上还是遵循了类似于SDXL的桶采样策略,但是精心设计了数据流程以确保在各种宽高比下能够达到更好的采样,并最终帮助模型不偏向于某一种宽高比。
【达到的效果】
在与SDXL和PlaygroundV2对比,本文的PlaygroundV2.5的prompt-image对齐性更好,生成的图像更满足prompt中的细节描述(如下图中虚线框的prompt),同时在细节上也更好。

- 人类偏好对齐(Human Preference Alignment)
【之前模型存在的问题】
人类对手、脸、身体等人类特征的视觉错误特别敏感且容错度比较低。如果人脸畸形或身体结构扭曲,那么即便人像之外的画面具有完美照明、构图和风格,该图像仍然大概率会被评为低质量。
之前的生成模型,无论是语言还是图像,都容易产生幻觉。在图像模型中,这可能表现为畸形的人类特征。产生该问题的原因有很多,但一个明显的解释是训练目标不一致:生成模型的训练是为了最大化log-likelihood,而不是最大化人类偏好。
【本论文的解决方法】
在LLM中,将预训练的生成模型与人类偏好对齐的一种常见策略称为监督微调(即SFT)。SFT使用小但非常高质量的数据集对预训练的基础模型进行微调。这种简单的技术通常优于RLHF等更复杂的方法[33]。
Playground v2.5的目标之一是尽可能降低人类特征中出现视觉错误的可能性。Emu为T2I模型引入了一种类似于SFT的对齐策略。受Emu的启发,PlaygroundV2.5开发了一个系统,使我们能够通过用户的评级从多个数据来源构造高质量的数据集。然后采用了一种迭代的、人为控制的循环方法来选择最佳的数据集候选者。
【达到的效果】
通过上述粗略介绍的对齐方法,playgroundv2.5号称在人脸细节、眼球形状、头发纹理、整体灯光等方面具有更好的效果。

- 提升颜色和对比度(enhancing color and contrast)
与其他先进模型的效果对比:
Playground v3
《Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models》
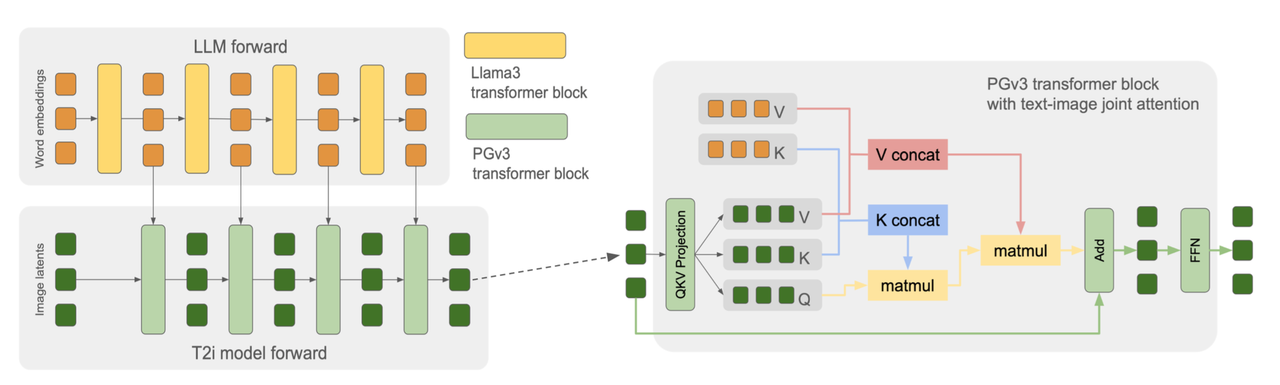
算法流程:PlaygroundV3是对前版本PlaygroundV2.5的升级,在text-encoder、backbone和VAE的主要架构上都做了改进,并使用了ELLA技术增强了image-text alignment 能力;其次内部设计了一个caption模型,能够精准描述图像中多种级别的细节信息;应用场景包括贴纸、海报、logo等各种艺术设计;功能上在图像真实度、文字渲染生成、指令跟随、颜色控制、多语种生成等均有极大的效果提升;
算法细节:
Captioning Model
专门开发了一个caption模型,包含一个vision encoder, 一个vision-language adapter, 和一个decoder-only的language model。并且作者认为高分辨率的vision encoder更有助于捕捉图像的细节信息。
Text Encoder
之前对于传统T2I模型text-encoder的改进,要么使用LLM模型替换普遍使用的T5或CLIP模型,要么使用LLM对prompt进行改写以更加适配预训练好的T5或CLIP模型。本算法使用前者:直接抛弃T5和CLIP模型而单独使用Llama3-8B作为初始权重进行训练。
Transformer模型在不同的层能够捕捉不同级别的语义(word-level或者sentence-level),但是由于LLM模型的庞大和复杂,想要在其中找到最优的transformer层作为text-encoder特征是并不容易的。
作者认为LLM模型具有强大的生成能力,主要在于信息和特征在其内的流动具有完整和连续性,其中的知识跨越了所有layer,并非是某一层的特征就能完整概括的。
所以受此启发,作者在t2i模型时复制了LLM的所有transformer-block。这种设计允许模型将LLM中每个hidden embedding outputs作为t2i模型相应层的条件输入,能够充分利用LLM完整的“thinking process”。最终帮助模型在生成图像时实现了精准的prompt跟随和prompt连贯性能力。
回顾与对比:之前的T2I模型则是单独使用T5/CLIP的输出层或者倒数第二层作为text ebbedding,并且将这个特征复制后分别送到所有的UNet层中,而本文的PlaygroundV3则是LLM不同layer的text-embedding送到image model对应的层。
Model Structure
PlaygroundV3的图像生成的backbone采用DiT结构,完全复制Llama3-8B的transformer结构,包括hidden embedding尺寸, attention heads数量, attention heads 维度等。在训练过程中冻住LLM部分只训练图像部分的模型。在推理时LLM只需要推理一次得到所有中间状态特征就行。
PlaygroundV3图像模型的每个tranformer-block只包含一个atttention层和一个feed-forward层,具体做法正如流程图所示:在得到image feature的QKV和text embedding的QKV时,将两者的K、V对应拼接得到新的K、V后再配合用image feature的Q进行最终的attention。通过该操作能够将原SD或SDXL模型中的self-attention和cross-attention合并成一个attention,减少计算量。
回顾:原SD和SDXL架构中每个transformer-block包含一个self-attention(图像特征自己的QKV),一个cross-attention(图像特征的Q和text embedding的K、V)和一个feed-forward。
此外模型还使用了以下一些技巧提升最终图像模型的生成能力:
U-Net skip connections between transformer blocks:模仿UNet在transformer blocks之间使用跳跃连接。
Token down-sampling at middle layers:在所有共32层的transformer block中,对image特征的K和V也做了4倍下采样,提升训练和推理速度且发现对最终的生成质量没有影响。
Positional embedding:使用Rotary Position Embedding(RoPE)进行位置编码。具体探索了两种变体:
interpolating-PE: 保证起始和结束位置ID保持固定,而不管序列长度如何,并在其间插值位置ID——SD3和其他模型采用了这一想法。
expand-PE:根据序列长度成比例增加位置ID,不应用任何技巧或归一化(即传统位置嵌入)。
最终作者发现“interpolating-PE”有一个明显的缺点:会导致模型在训练分辨率上严重过拟合,无法推广到未见过的宽高比。相比之下,“expand-PE”方法表现更好,没有显示出分辨率过拟合的情况。因此最终选择使用传统的位置嵌入。
New VAE
Emu将VAE的latent通道数从SD/SDXL中的4增加到了16,提升了诸如小单词和小字的生成效果。借鉴该方法,PlaygroundV3也将通道数提升到了16并且分辨率从256增加到了512。
此外作者还做了一些探索:
- 借鉴Emu中的frequency method训练VAE但是没有效果提升
- 使用CLIP 的image encoder 或者DINOv2 的encoder 作为VAE的encoder,虽然重建效果有提升但是配合上diffusion生成后效果都没有提升甚至会导致不稳定。
模型训练:
Noise schedule:和PlaygroundV2.5一样,仍然使用EDM算法
Multiple Aspect-Ratio Support:也采用了和PlaygroundV2.5一样的策略
Multi-Level Captions per Image:团队内部训练了一个Vision Large Language Model (VLM) 用于对图像caption,能够对图像中高细节的部分进行描述(比如小物体、光照、风格和纹理),记作PG Captioner。此外该caption模型能够生成详细程度不同(即6种长度)的描述语句。利用该caption模型在训练T2I模型的时候随机选取其中一个作为text condition。该机制能够帮助模型在少量数据SFT的时候不会发生过拟合,同时在推理的时候也能够在即便输入很短prompt的时候,保证生成图像的多样性。
Training stability:作者在模型训练的后期观察到损失峰值(表现为损失很大但是没有NaN),这导致模型无法生成有意义的图像。尝试了几种方法,包括降低Adam优化器的beta值、梯度剪裁和降低学习率。但是都没效果。最终,作者使用以下方法进行解决:
在训练过程的每个iteration下都遍历了所有参数的梯度,并计算了梯度超过规定的梯度阈值的数量。如果这次training iteration下大梯度参数的数量超过预定义的计数阈值,就停止这次iteration的参数更新直接开始下一次iteration的训练。
该方法与梯度剪裁的区别:梯度剪裁不足以避免模型权重在出现异常值时的影响,其只会减小梯度的大小,但不会改变权重更新的方向,因此网络权重仍有可能坍塌。而通过丢弃整批梯度则能避免这种风险,并确保模型保持在稳定的训练轨迹上。
其他:
DPG-bench:
受DSG和DPG bench的启发,提出了一种用于image caption评估的反向方法。基于图像构建17个类别的“是-否”问答对:一般问题、图像类型、文本、颜色、位置、关系、相对位置、实体、实体大小、实体形状、数量、情感、模糊、图像伪影、专有名词、调色板和颜色分级。
具体评估过程中,使用LLM来回答“Yes”、“No”或“N/A”(当无法回答问题时)。然后将答案与参考答案进行比较,以计算结果的准确性。
最终构建了由200张图片和2471个问题构成的caption benchmark-CapsBench1,平均每张图片有12个问题。其中图像包含电影场景、卡通场景、电影海报、邀请函、广告、休闲摄影、街头摄影、风景摄影和室内摄影等各种场景。
应用和优势:
- Photo-realism:在皮肤纹理等细节上的真实感优于Ideogram-2 和Flux-Pro
- Prompt-Following:指令跟随能力提升,即便在很长prompt上也能具有比较好的响应
- Text Rendering:在海报、logo等具有很强的文字生成能力,82% 的准确率高于Flux-pro的69%和Ideogram-2的75%
- RGB Color Control:精确的颜色控制能力,能控制图像中指定部分具有指定的颜色
- Multilingual Prompt Input:支持多语种prompt输入