下述效果的具体代码见: qzq2514/Diffusion
效果提升
这里简单实验和讨论了在训练DDPM过程中使用的损失函数(L1或L2损失),并且实验了Improved DDPM 中提到的Cosine Beta Schedule带来的效果提升。
Cosine Beta Schedule
首先回顾下DDPM在前向过程中的一个重要公式-利用重采样技巧从
torch.linspace(start=0.0001, end=0.02, steps=100)Improved DDPM则进一步分析了这种Beta设计的缺点,取出论文中的图3和图5:
| Linear和Cosine的Beta方式对于加噪的影响 | |
|---|---|
 |
 |
从上表格中的右图可以发现:在Linear的方式下,
Cosine形式的Beta采样设计如下:
效果提升实践
- 单通道较简单的数据集(如Mnist, Fashion_Mnist等)可以直接使用Linear的Beta采样,与Cosine采样无大区别
- 3通道相对复杂的数据集(如Cifar10, Flower102, StyleGAN_Face等)的Beta采样最好使用Improved DDPM中提出的Cosine schedule,不然会导致最终生成的图片偏白。
- L1损失和L2损失对比,L2损失下生成效果会更加"尖锐"有时候会稍显乱+脏,而L1损失则显得更加平滑。
上述提到的L1/L2损失、Linear Beta Schedule/Cosine Beta Schedule的效果对比如下:
| 配置 | L1 loss、Cosine Beta | L2 loss、Cosine Beta | L1 loss、Linear Beta |
|---|---|---|---|
| Cifar10 |  |
 |
 |
| Flower102 |  |
 |
 |
尝试其他可能有效的Tricks
此外又使用lucidrains 的代码验证了一下其中比较重要配置(如EMA、P2 loss、Clip_denoised)的必要性,对比效果如下:
| 配置 | EMA✅ P2 loss✅ Clip denoised✅ | EMA❌ P2 loss✅ Clip denoised✅ |
|---|---|---|
| 效果(26K steps) |  |
 |
| 配置 | EMA✅ P2 loss❌ Clip denoised✅ | EMA✅ P2 loss✅ Clip denoised❌ |
| 效果(26K steps) |  |
 |
上面看来无明显的大差别,所以在本仓库中未使用EMA和P2 Loss,但是用了Clip denoised。
其他重要的配置则使用lucidrains原代码仓库中默认的:
loss_type='l1' beta_schedule='cosine' objective='pred_noise' self_condition=False采样加速
推理加速主要使用DDIM 中的算法
DDIM公式推理
DDPM的推理采样是一个不断迭代的过程,通常需要和训练中扩散过程相同的步数(DDPM使用1000步)进行去噪,该过程相对来说比较耗时。引用What are Diffusion Models?中的一句话:”One data point from Song et al. 2020: “For example, it takes around 20 hours to sample 50k images of size 32 × 32 from a DDPM, but less than a minute to do so from a GAN on an Nvidia 2080 Ti GPU.”
DDIM则是加速采样的一个有效方法,在介绍DDIM之前,这里先再次回顾Diffusion学习2-理论推导中利用重采样技巧从
- 其中的
就是我们DDPM的网络预测目标,即预测的噪声 。 - 对于起始是纯噪声的图像
我们无法直接获取其对应的 ,但是根据公式(1)我们可以根据 和预测噪声反向推理得到近似重构的 。
于是公式(3-1)就变成了:
- 使用一个原采样时间戳
的一个子序列 进行迭代采样,其中 且S小于原训练的扩散步数T。 - 使用上面利用
和 来逆向推导降噪结果: 。
上述的
加速采样实践
| 配置 | 50步 | 100步 | 200步 | 500步 | 800步 | 1000步 |
|---|---|---|---|---|---|---|
| DDPM |  |
 |
 |
 |
 |
 |
| DDIM(eta=1) |  |
 |
 |
 |
 |
 |
| DDIM(eta=0) |  |
 |
 |
 |
 |
 |
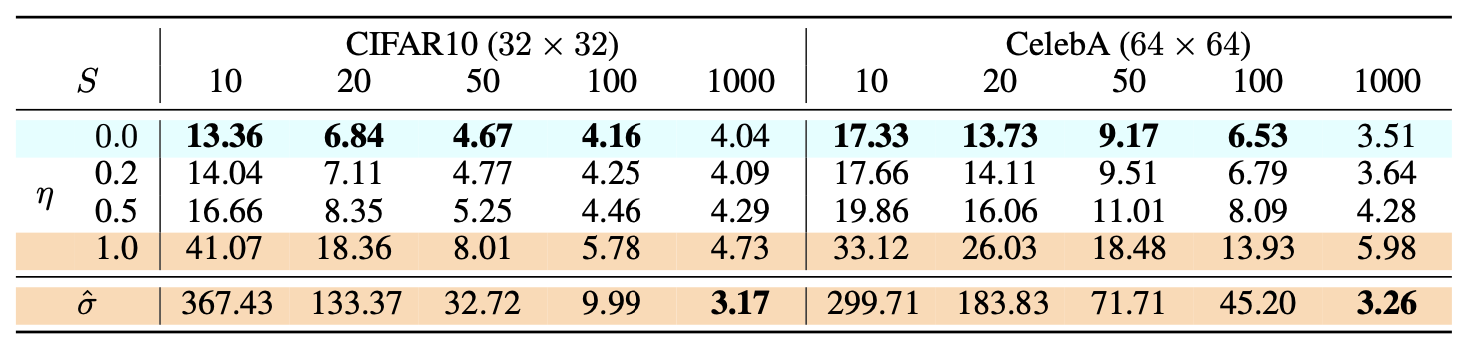
上面的DDPM在采样步数小于训练步数(1000)的时候,使用的是Improved DDPM 中的间隔步长采样。可以看到上面的结果:
- 常规的DDPM采样结果在步数比较小时候基本仍然为纯噪声,虽然在步数逐渐增大(如500和800步)后会逐渐出现生成主体,但是仍然有一层噪声,直到采样步数等于训练时候的去噪步数(1000步)才能生成比较好完全无噪声的图像。
- 使用DDIM算法时候即便在步数很小(50步)时,也已经具有了比较好的生成效果,生成速度能提升至少20倍。
- 从当前实验结果看下来,在DDIM采样中eta=0和eta=1好像并无太大的效果差异。
✅2023.8.24补充
一个思考:为什么DDIM能加速采样过程?
因为经过之前文章的公式(1)和公式(4)其实可以知道,扩散的加噪和去噪过程都是一个马尔科夫链的过程,是一步步迭代的过程,而DDIM的出现则是为了打破这个马尔科夫链过程,其提出了本文章的公式(4),即
更多详细解释可以见zhihu.李Nik。
Conditional Generation
之前实践的一些方法包括原始DDPM论文的生成过程都是随机的,那么有没有可能对生成的结果进行控制呢?比如生成我们想要的类别?答案肯定是可以的!
预备小知识点
首先回顾一下一个高斯分布
Classifier Guidance
为了控制图像的生成的生成,比如控制生成的图像是我们要的类别,那么通常的做法就是可以对输入的含噪声图像添加类别信息

【其中Algorithm2中获取
Classifier-Free Guidance
解决的问题
Ho & Salimans, 2021在论文中指出使用,Classifier Guidance 用来控制Diffusion生成类别具有以下问题:
- Classifier guidance combines the score estimate of a diffusion model with the gradient of an image classifier and thereby requires training an image classifier separate from the diffusion model.
- It also raises the question of whether guidance can be performed without a classifier.
- classifier-guided diffusion sampling can be interpreted as attempting to confuse an image classifier with a gradient-based adversarial attack.
总的来说就是Classifier需要额外引入一个预先训练好的分类器
算法核心
核心内容其实比较简单,就是使用一个近似的项来逼近公式(4)中的
其中