LeNet
- LeNet是最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。 这个模型是由AT&T贝尔实验室的研究员Yann LeCun在1989年提出的(并以其命名),目的是识别图像中的手写数字。
- 利用卷积、池化、激活函数、全连接层等操作提取特征(这也奠定了后续所有卷积神经网络的基本特性)
- 卷积操作实现参数共享,相比较全连接操作大大降低了参数量
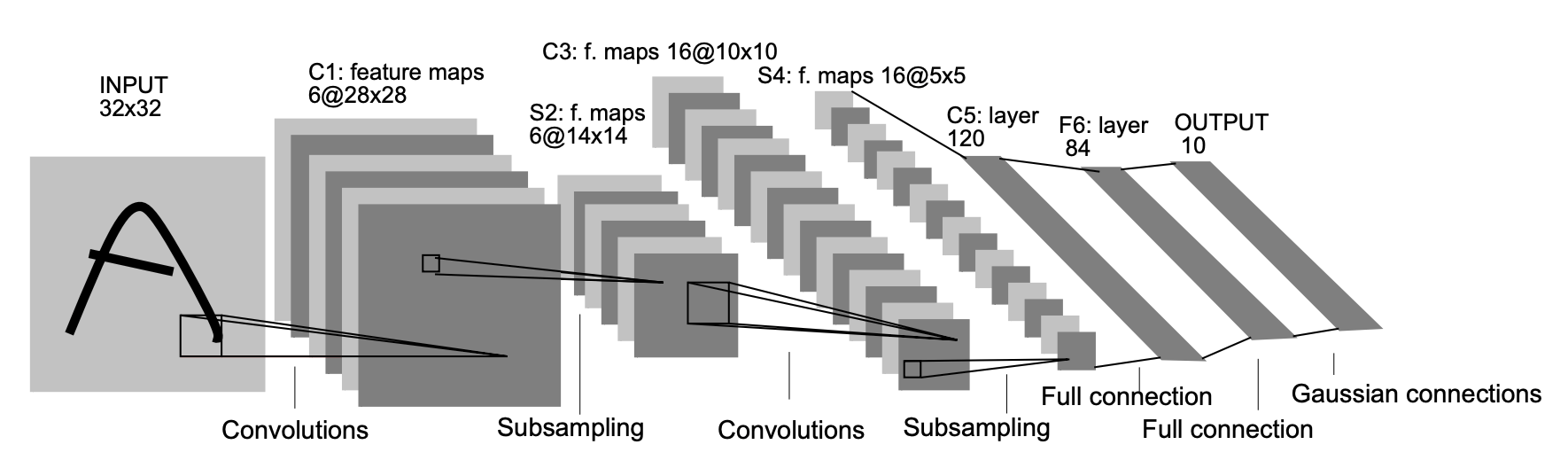
- LeNet又名LeNet5,是因为在LeNet网络中使用的均是 5×5 的卷积核,如下图所示:
AlexNet
AlexNet在2012年ImageNet挑战赛中取得了轰动一时的成绩,它首次证明了学习到的特征可以超越SIFT、HOG、Bags of Visual Words等手工设计的特征,同时也首次使用两个显存为3GB的NVIDIA GTX580 GPU实现了快速卷积运算,成为首个在GPU硬件上训练和运行的深度神经网络。
网络创新点:
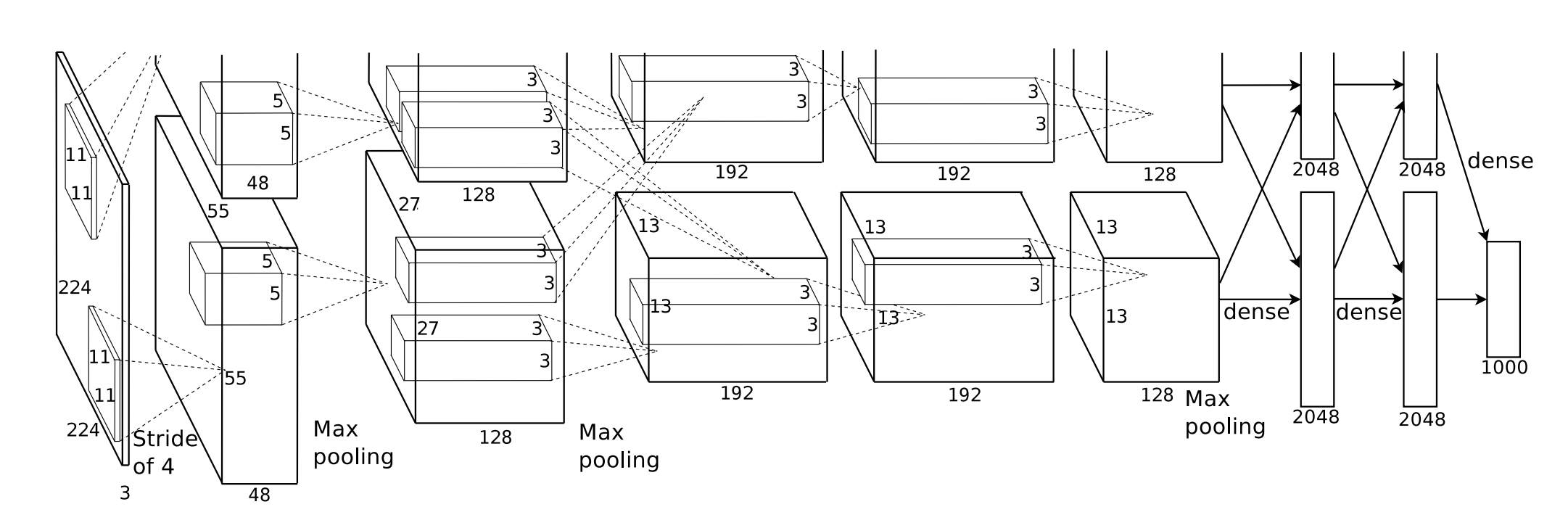
相比较于LeNet,AlexNet网络要深得多,其由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
抛弃Sigmoid或者tanh等非线性函数,改用非线性激活函数:ReLU
使用多种数据扩充技术:随机裁剪、对RGB空间做PCA
重叠池化 (Overlapping Pooling):在池化的时候,每次移动的步长小于池化的窗口长度,一定程度上可以避免过拟合
Dropout: 随机丢弃一些神经元节点,防止网络过拟合
局部响应归一化(LRN),求通道维度上近邻区域像素值的和:
多GPU训练:每个GPU中放置一半神经元,将网络分布在两个GPU上并行计算
VGG
- VGG由牛津大学的视觉几何组(Visual Geometry Group)。通过设定通用且小巧的子模块并循环使用这些子模块,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构
- 探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能。其可以看成是加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。
- 网络由5层卷积层、3层全连接层和softmax输出层构成,层与层之间使用max-pooling,所有隐层的激活单元都采用ReLU函数。
- 卷积核分解:使用小卷积核减少参数量:
- 两个3x3卷积的感受野和一个5x5卷积的感受野一样,参数比较:
- 三个3x3卷积的感受野和一个7x7卷积的感受野一样,参数比较:
- 两个3x3卷积的感受野和一个5x5卷积的感受野一样,参数比较:
- 卷积过程中,下采样时通道数量翻倍
Inception系列
Inception系列又称GoogleNet
InceptionV1
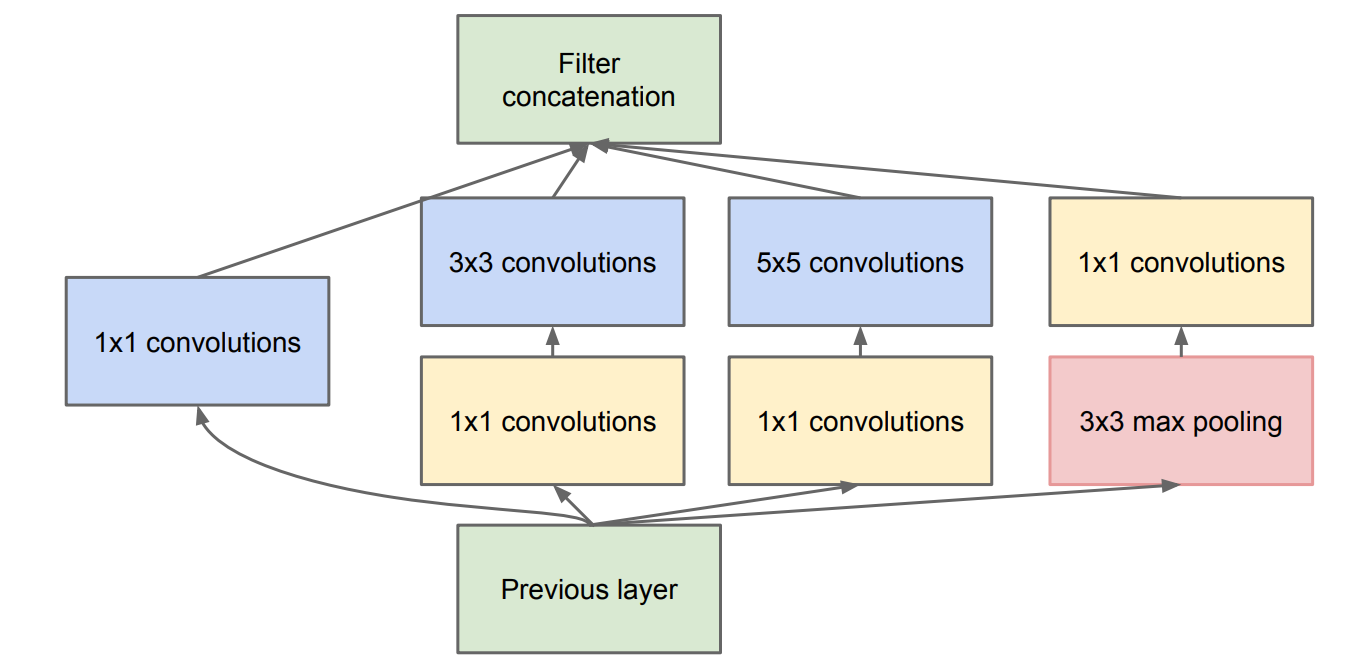
InceptionV1认为不同尺寸的卷积核组合是有好处的,使用不同大小的卷积核能够获取不同大小的感受野。其引入了Inception模块,即在同一层级上运行多个尺寸的卷积核。
挖掘了1 1卷积核的作用,减少了参数
Inception模块在 3x3 和 5x5 卷积层之前添加额外的 1x1 卷积层,来限制输入信道的数量,如下:
InceptionV2
InceptionV2吸取VGG的想法,同样使用卷积核分解,使用连续小卷积代替大卷积,如将
卷积分解为两个 卷积。 增加Batch Normalization,减少了Internal Covariate Shift(内部神经元的数据分布发生变化),使每一层的输出都规范化到一个
的高斯
InceptionV3
- InceptionV3和InceptionV2来自同一篇论文,其最大创新是Factorization
into small convolutions方法,即将
的卷积核尺寸分解为 和 两个卷积,不仅节约了参数,而且加速运算并减轻了过拟合,同时增加了一层非线性扩展了模型表达能力,这种非对称的卷积结构拆分,可以处理更多、更丰富的空间特征,增加特征多样性),但是如果在模型的前期就使用这种分解,特征的表达效果不好,建议在中间大小的feature maps(比如size在12到20之间)。 - 标签平滑: 添加到损失公式的一种正则化项,旨在阻止网络对某一类别过分自信,即阻止过拟合
- 使用了辅助分类器,把梯度有效的传递回去,不会有梯度消失问题,加快了训练
- 网络的输入从224改成了299
InceptionV4
- InceptionV4综合了一下前三个版本的优势(其实就是使用了不同的 Inception Block),然后设计了很多的 Inception Block最后堆叠成一个更大的网络。
- 其次其还引入了残差结构,提升网络训练稳定性和效果
ResNet系列
提出背景:网络层数的增加可以有效的提升准确率没错,但如果到达一定的层数后,训练的准确率就会下降了,因此如果网络过深的话,会变得更加难以训练
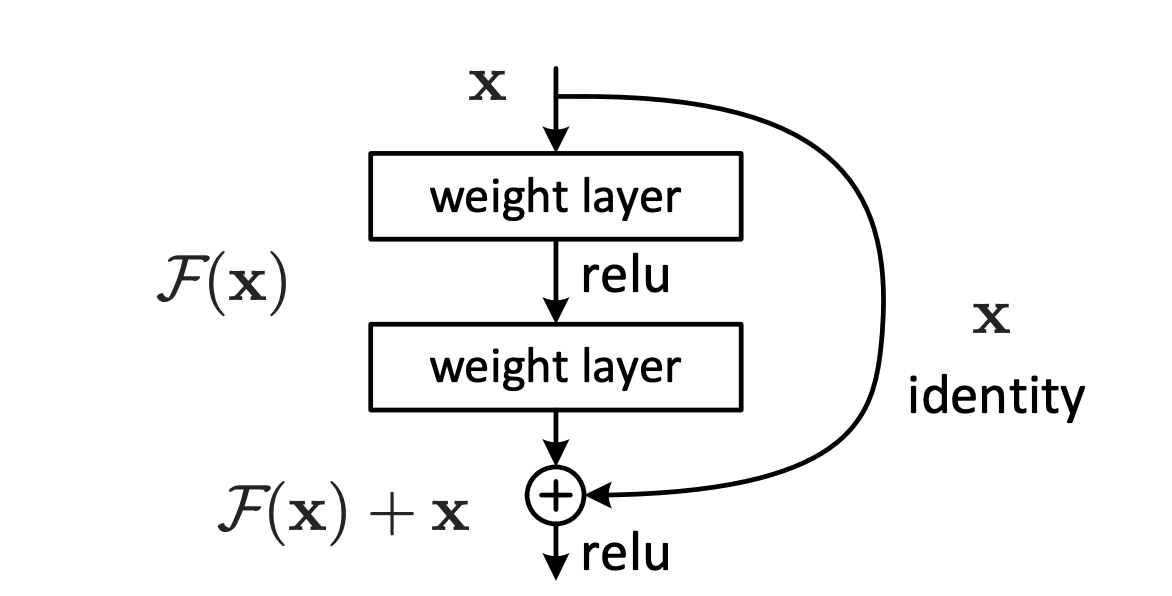
核心假设:假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(Identity mapping,也即y=x,输出等于输入), 这样就相当于只是增加了网络的深度,起码误差不会增加,也表明这种情况下更深的网络不应该带来训练集上误差的上升。
优势:
- 解决更深层网络带来不了精度提升的问题
- 加快梯度的的前向传播,避免梯度消失
理论推导:
一个残差模块的输出
- 浅层的特征可以毫无损失地前向传递到深层,而一般堆叠式神经网络的深层特征是由一系列矩阵相乘得到的,仅仅只与前一层的输入有关。
- 反向传播时,损失对深层的梯度(即
)可以毫无保留的传递到浅层 不会一直为-1,这也就保证了不会发生梯度消失的问题
以上好处都是建立在左边的“identity”分支完全恒等映射的,没有任何系数。这样就要求我们:
- 不轻易改变”Identity“分支的值,也就是输入与输出一致
- addition之后不再跟上改变信息分布的层
假设“identity”分支不是恒等,而是有一个系数
如果
说明不是恒等映射,那么就会导致信息传递的问题。
ResNetV2
ResNetV2主要针对原ResNet1中的残差分支做了一些分析:
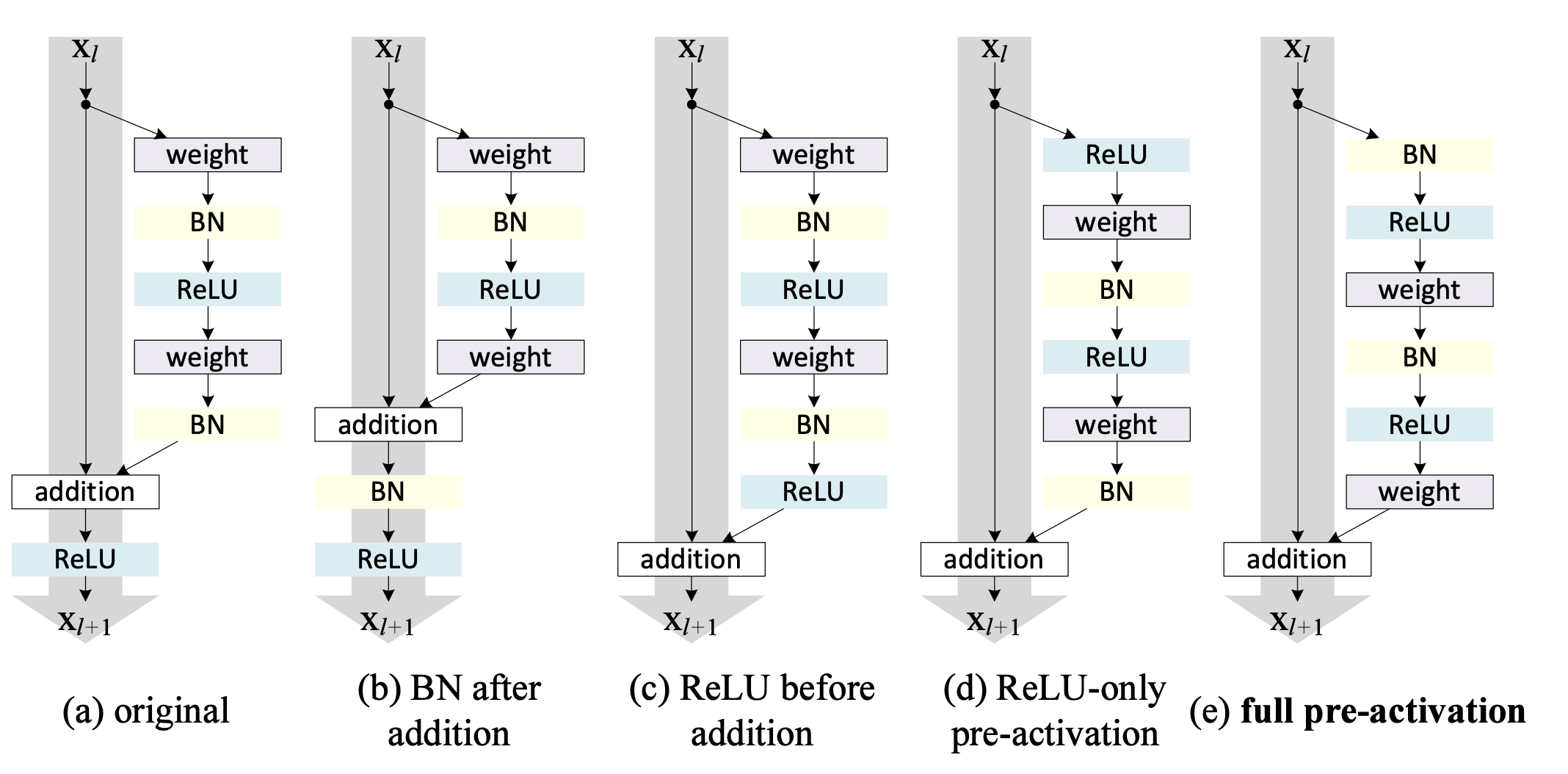
图(a)为ResNetV1的残差模块,特点:
- BN和ReLU在Weight(即卷积操作)的后面
- 相加后,最后的ReLU在addition的后面
图(b)的问题:
相比较于图(a),其将右侧残差模块的"BN"提到"addition"之后。会导致BN改变了左侧“identity”分支的分布,影响了信息的传递,在训练的时候会阻碍loss的下降。
图(c)的问题: 其采用ReLU作为残差分支的结尾,导致右侧的残差分支的结果永远非负,这样前向的时候输入会单调递增,从而会影响特征的表达能力。
图(a)~图(c)都是后置激活,即"BN"和"Relu"在卷积之后
图(c)和图(d)则是前置激活,即"Relu"在卷积之前。两者的区别在于Weight操作相比较于"BN"的位置顺序。经过实验证明:BN层作为pre-activation,起到了正则化的作用。
所以图(e)是ResNetV2的残差结构,其相比较于ResNetV1(图a)特点为:
- Relu放在addition之前,成为残差分支 的专有(尽量不改变"identity"分支,将其恒等地传递下去)
- 采用前置激活,将"BN"和"Relu"放在卷积之前,起到了正则化的作用
SENet
SENet作为ImageNet2017的冠军模型,它并非一个特定结构的网络模型,而是提出了一即插即用的模块-SE Block,该模块利用了注意力机制的思想,通过一个分支内的全连接预测每层特征图的权重,然后对每层特征求加权平均作为最终模块的输出。
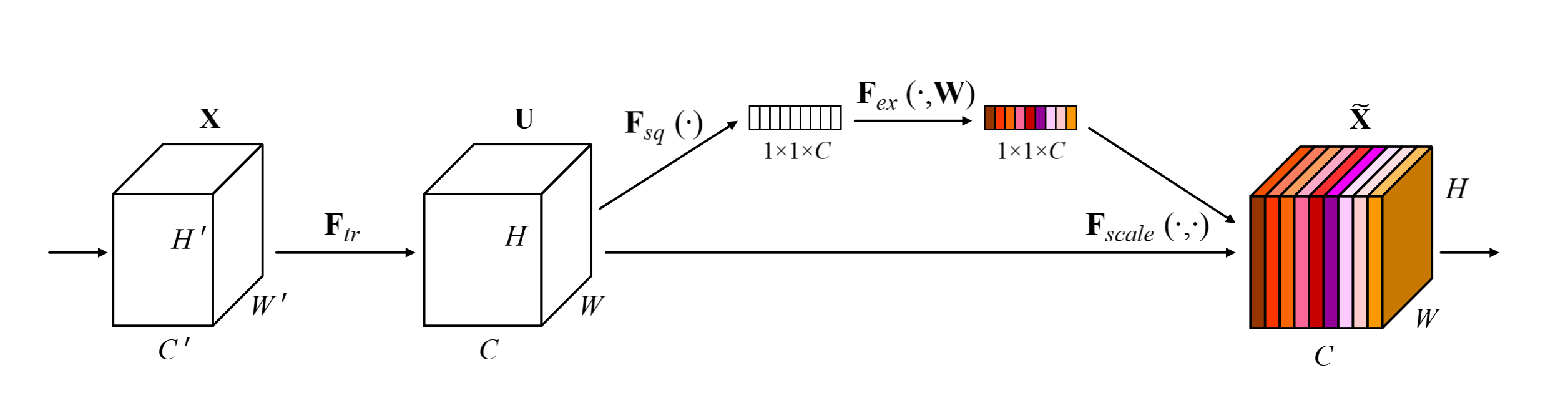
:Squeeze操作,顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的channal数相等【即尺寸从(h,w,c)变成(1,1,c)】。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用。 :Excitation操作,是一个类似于循环神经网络中门的机制。通过参数来为每个特征通道生成权重,其中参数被学习用来显式地建模特征通道间的相关性。 :Scale操作,将Excitation操作输出的权重看做是进过特征选择后的每个特征channal的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定然后和原输入对应通道相乘即可 (算一种attention机制)。
MobileNet系列
MobileNetV1
MobileNetsV1核心是提出了可分离卷积,即将普通的卷积操作拆分成Depthwise+Pointwise两部分:
- Depthwise:每个通道对应一个单层的卷积核单独进行卷积操作
- Pointwise:1x1卷积,跨通道操作能够融合多通道特征
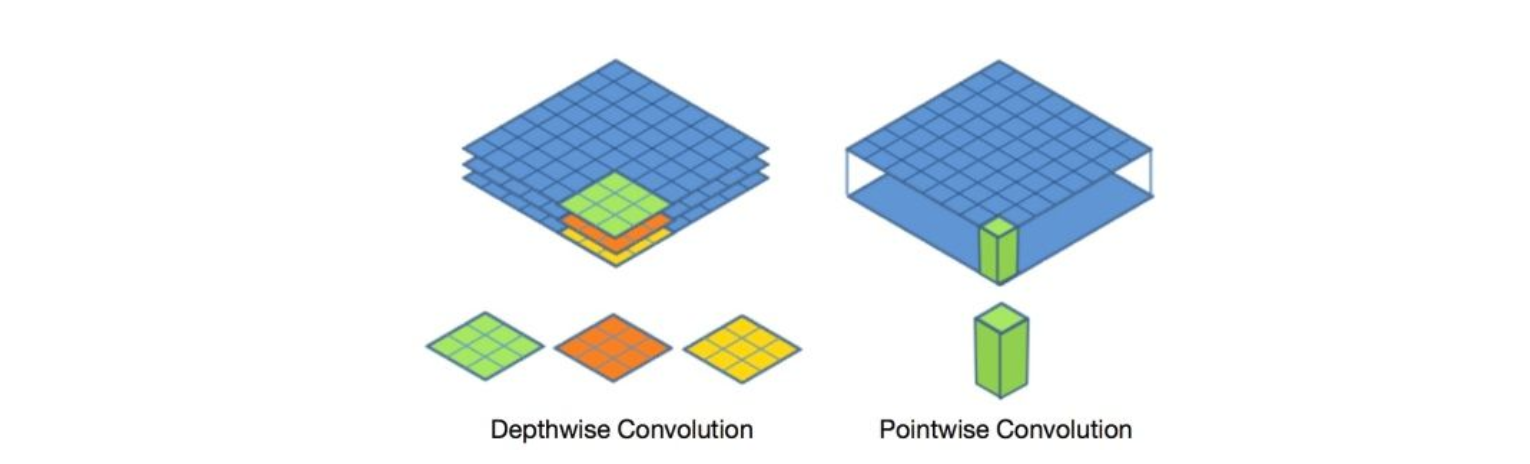
参数量和计算量比较:
假设卷积步长作为1,输入特征和输出特征的空间分辨率(宽高)都是
,两者的通道数分别为 和 ,传统卷积核的尺寸为 。 传统卷积:
- 参数量:卷积核完整尺寸为
,共 个,所以参数量为 。 - 计算量:每次卷积的计算量等于卷积核尺寸
,每层channle需要计算 ,共需要计算得到 层输出特征,所以一次输出到输入的完整计算量为 。
- 参数量:卷积核完整尺寸为
可分离卷积:
- 参数量:Depthwise的卷积核尺寸
,共M个所以参数量为 ,Pointwise的卷积核尺寸为 ,共 个所以参数量为 ,所以完整的可分离卷积参数量为 - 计算量:Depthwise的计算量为
,Pointwise的计算量为 ,所以完整的可分离卷积计算量为 。
- 参数量:Depthwise的卷积核尺寸
比值:
参数量之比:
计算量之比: 当 比较大(一般输出特征图通道为64、128之类)时,深度可分离卷积的参数量和计算量都只有原传统卷积的 ,比如卷积核常见为3时候,可分离卷积的参数量和计算量能够降到原来的 。
原论文中给出了两个超参:
- 宽度乘数:所有层的通道数(channel) 乘以
$$参数(四舍五入),模型大小近似下降到原来的
倍,计算量下降到原来的 倍。 - 分辨率乘数:输入层的 分辨率(resolution) 乘以
,参数 (四舍五入),等价于所有层的分辨率乘 ,模型大小不变,计算量下降到原来的 倍。
- 宽度乘数:所有层的通道数(channel) 乘以
$$参数(四舍五入),模型大小近似下降到原来的
MobileNetV2
MobileNetsV2发现ReLU函数会导致信息丢失,尤其在输入维度是2,3时,输出和输入相比丢失了较多信息;但是在输入维度是15到30时,输出则保留了输入的较多信息。这就是说我们在使用Relu函数时,当输入的维度较低时,会丢失较多信息,因此可以很简单地想到两种思路,一是把Relu激活函数替换成别的,二是通过升维将输入的维度变高除了继承。MobileNetsV2为了解决该问题则提出了具有线性瓶颈的逆残差结构(Inverted Residuals and Linear Bottlenecks),该结构的特点是:
- Inverted Residuals:较于ResNet中先降维再升维,MobileNetV2采用先升维再降维(防止降维后的特征损失)
- Linear Bottlenecks:深度可分离卷积的1x1卷积不跟上Relu6函数,而是直接的线性映射(避免ReLU或者Relu6在channel数较低时造成较大的信息损耗)
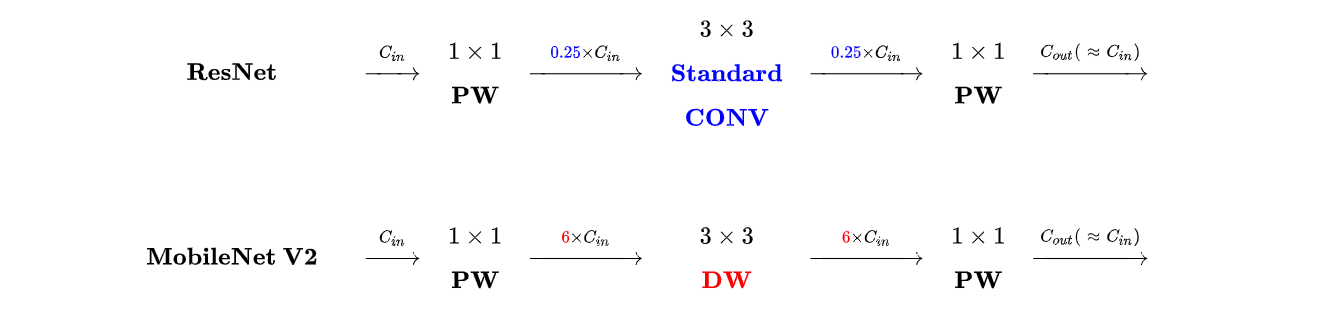
拓展:
MobileNetV3
MobileNetsV3使用NAS技术在一堆预设的网络结构中选择效果更好的网络设计,然后其也引入了SE模块提升网络效果:
深度可分离卷积+具有线性瓶颈的逆残差结构+轻量级注意力模型(SE模块)
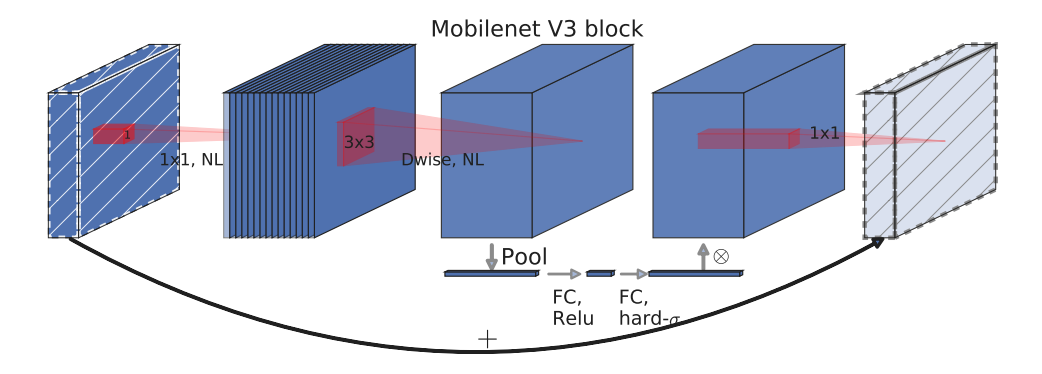
使用h_swish激活函数,能够有效提高网络精度:
ShuffleNet系列
ShuffleNetV1
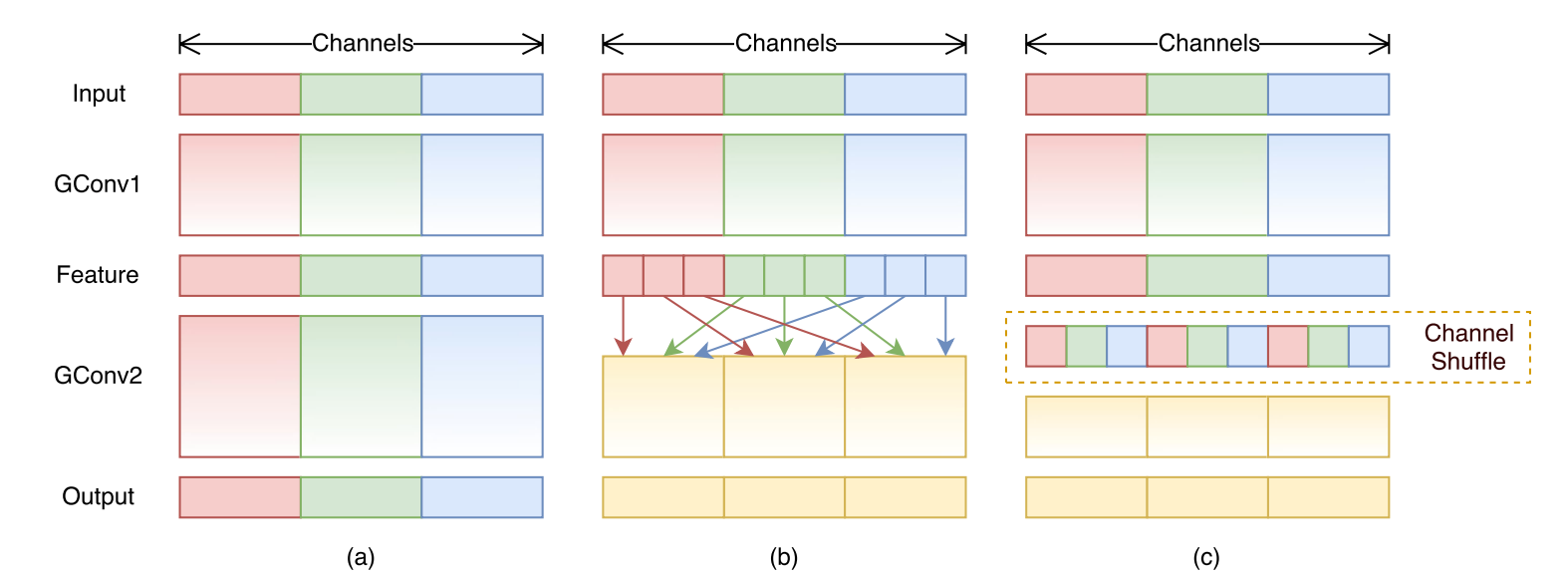
ShuffleNetV1提出了组卷积的概念,其实MobileNets中使用的深度可分离卷积中的Depthwise Convolution就是一种比较特殊的组卷积(组数=输入通道数),但是其问题在于是包含密集的1x1 Pointwise Convolution会消耗大量的计算资源。
但是!!如果把Pointwise Convolution去掉,又会产生另一个问题:每个通道各自卷积导致其他通道完全没有关系。其实一般的组卷积(group Convolution)也会有这种问题,即每个组之间的特征图都是各自提取特征的,和其他通道不相关,这样会降低网络的特征提取能力。(也是就是为什么Depthwise Convolution后面要跟上Pointwise Convolution的原因:要进行特征融合!!)。
为了达到跨通道通信的目的,可以在组卷积后得到整体特征图上打乱通道顺序,让来自同一组特征在这一次组卷积中进入不同的组,从而达到特征融合或者特征通信的目的,示意如下:
ShuffleNetV1的基本单元:
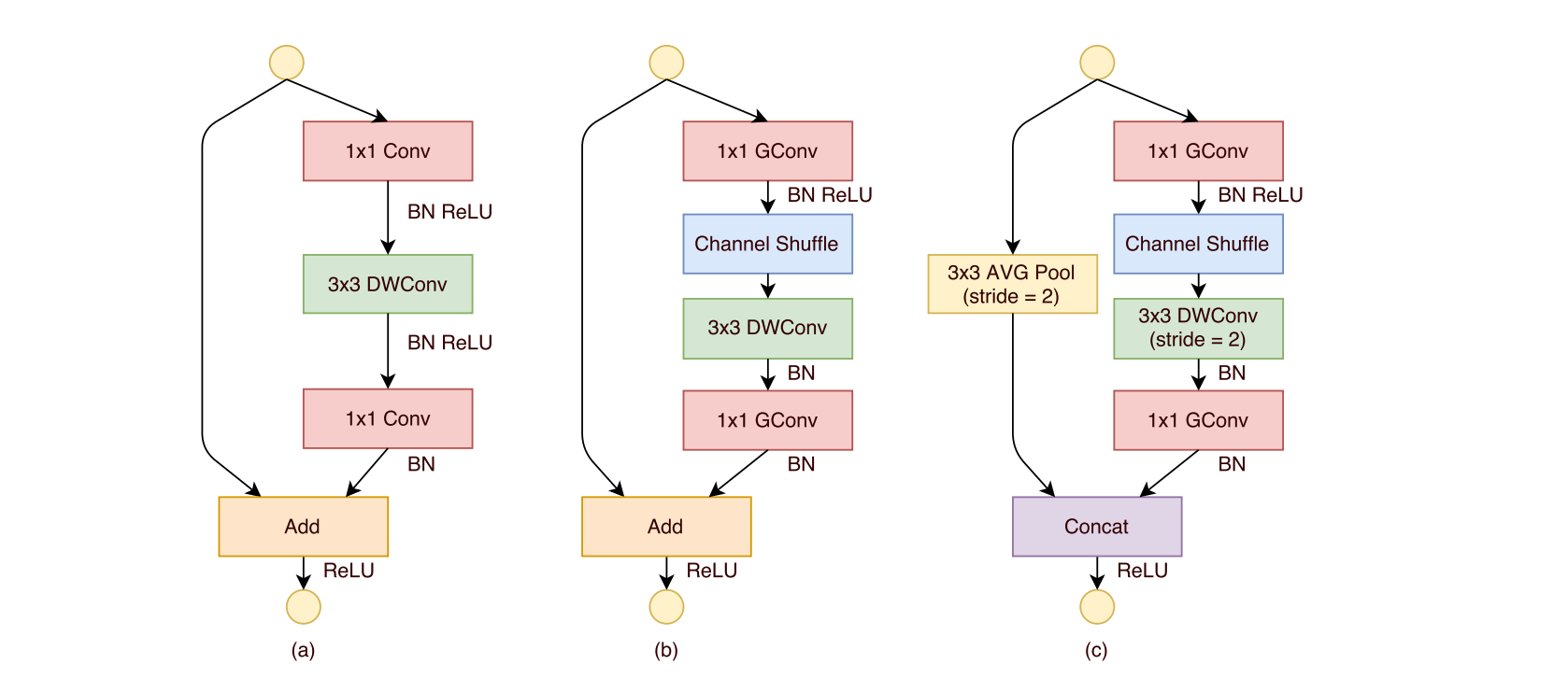
- 图(a)为基本ResNetV1配上深度可分离卷积构成的轻量级结构,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的Depthwise Convolution,这里的3x3卷积是称为瓶颈层(Bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
- 图(b)展示了ShuffleNetV1的改进思路:将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个Channel Shuffle操作保证组通讯。值得注意的是3x3卷积后面没有增加Channel Shuffle,一个Channel Shuffle操作是足够了。还有就是3x3的Depthwise Convolution之后没有使用ReLU激活函数。
- 图(c)展示了其他两点改进:1.对原输入采用stride=2的3x3 平均池化,在Depthwise卷积处取stride=2保证其和左侧支路的特征尺寸相同。2.特征图与输出进行通道拼接而不是相加。
综上来说,ShuffleNetV1的核心就是:组卷积+通道打乱,Pytorch实现通道打乱也比较简单:
def channel_shuffle(x, groups):
# x[batch_size, channels, H, W]
batch, channels, height, width = x.size()
channels_per_group = channels // groups # 每组通道数
x = x.view(batch, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batch, channels, height, width)
return x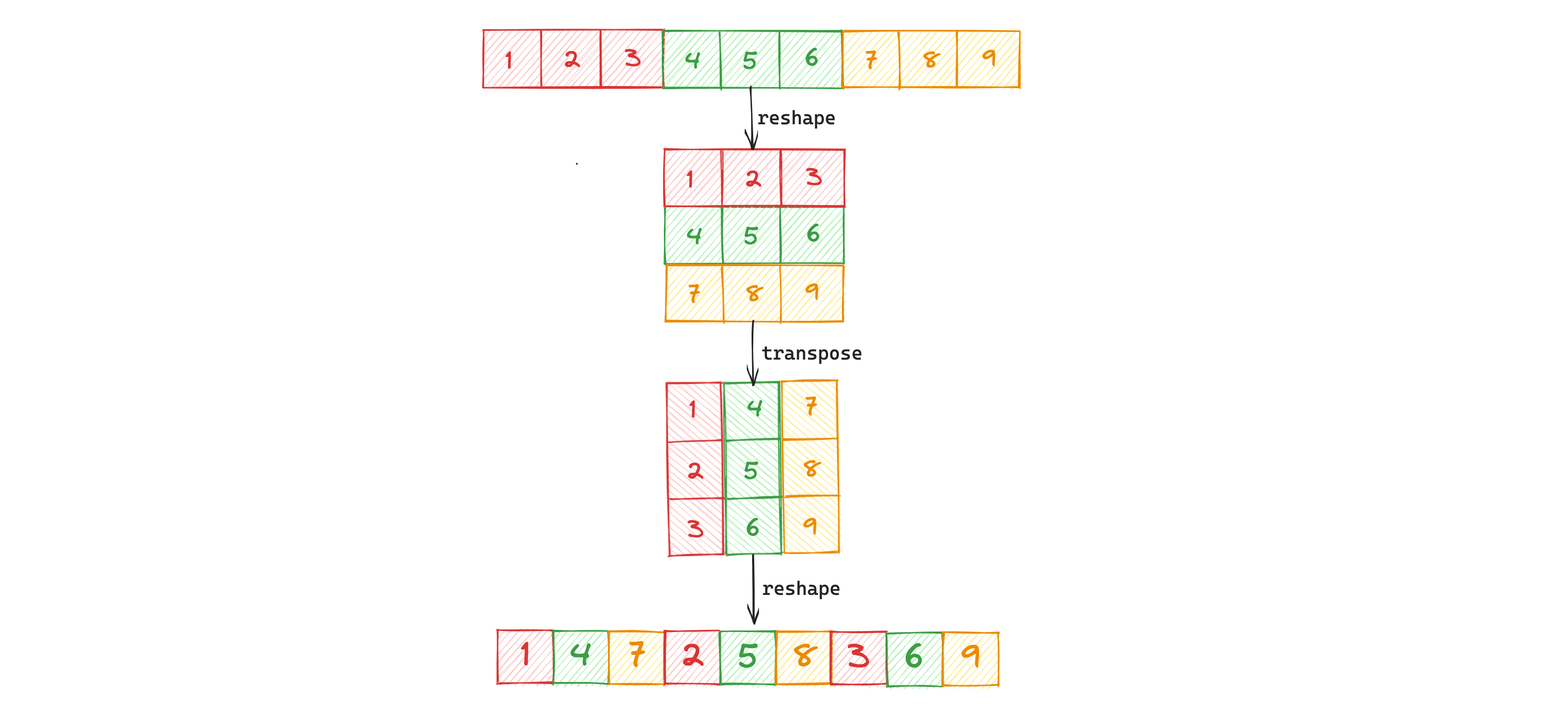
ShuffleNetV2
ShuffleNetV2在保留ShuffleNetV1的组卷积和通道打乱两个核心思想下,做了一些改进:
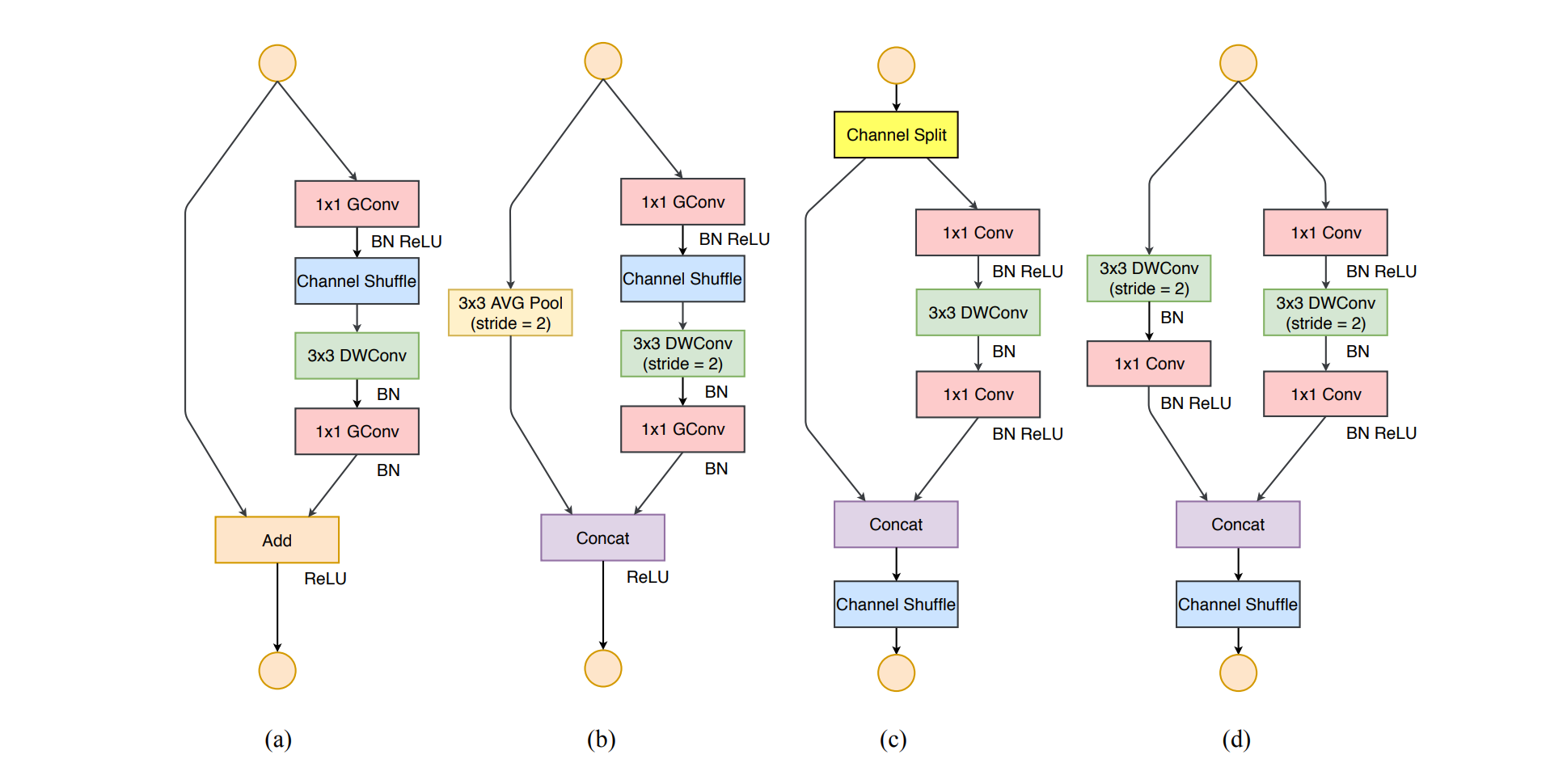
图(a)和图(b)是原ShuffleNetV1的单元结构,图(c)和图(d)是ShuffleNetV2中对应V1的改动。
从图(a)和图(c)的对比可以看出:
- c结构在单元开始处增加了一个channel split操作,这个操作将输入特征的通道分成c-c’和c’,c’在文章中采用c/2,即输入特征图一分为二分别进入不同分支。
- c中取消了1*1卷积层中的group操作(其实前面的channel split其实已经算是变相的group操作了)
- channel shuffle的操作移到了concat后面,因为第一个1*1卷积层没有group操作,所以在其后面使用channel shuffle也没有太大必要
- 将element-wise add操作替换成concat
DenseNet
DenseNet规定其每个层与其它每个层之间都已连接,相当于更密集的ResNet(只有相邻层有跳跃连接)。该网络对于每一层,使用前面所有层的特征映射作为输入,并且使用其自身的特征映射作为所有后续层的输入。
- DenseNet由多个Desne Block组成。每个Dense Block中的特征图尺寸相同且进行"密集连接",如下所示为一个完整的Dense Block。
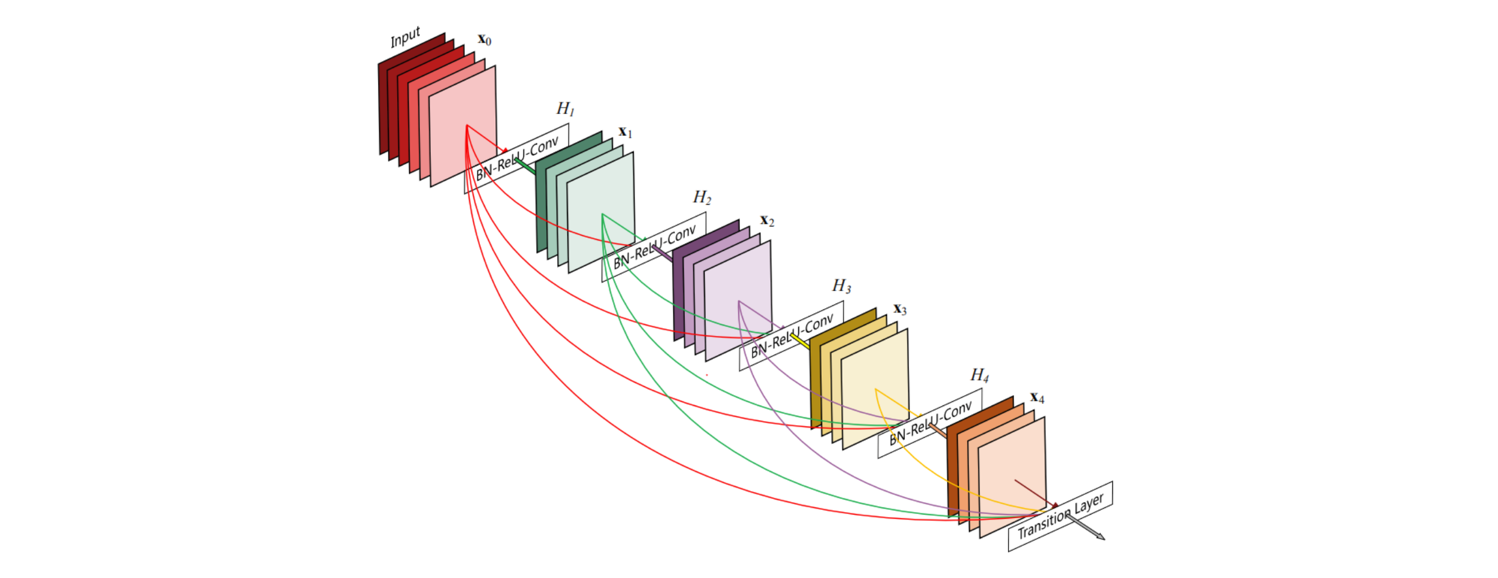
- 为了处理相邻Dense Block的特征图大小不相等,该网络提出了Transition layer,具体做法是采用1×1 Conv和2×2平均池化作为相邻 Dense Block 之间的Transition layer,在最后一个 Dense Block 的末尾,执行一个全局平均池化,然后附加一个Softmax分类器进行分类任务。
参考: