研究生期间主要且完整的一个项目是美国的车牌识别项目,在这个项目中也积累了一些经验并且发了一些专利,本篇博客则是整合了这些经验并构建了一个完整的车牌识别流程,有兴趣的也可以直接去看【论文】和【代码】。
要解决的问题
该项目顾名思义就是完成车牌号码识别的目的,但是这里要识别的车牌是美国的车牌号码,它们相比较"蓝底白字"国内车牌来说更加复杂,具体体现在“堆叠字符”、“长度不固定”、“排列无规律”,具体这些车牌的示意图可以见关于车牌识别的三个专利。本项目则能相对来说比较好地解决这些特殊的问题,在此之外本项目对于车牌识别中的“车牌倾斜”、“光照不均”、“模糊”等普遍存在的问题也都有比较好的鲁棒性。
解决方案
整个流程接受任意环境下的车牌图像(如倾斜、光照不均等),然后按照下图所示的流程进行识别:
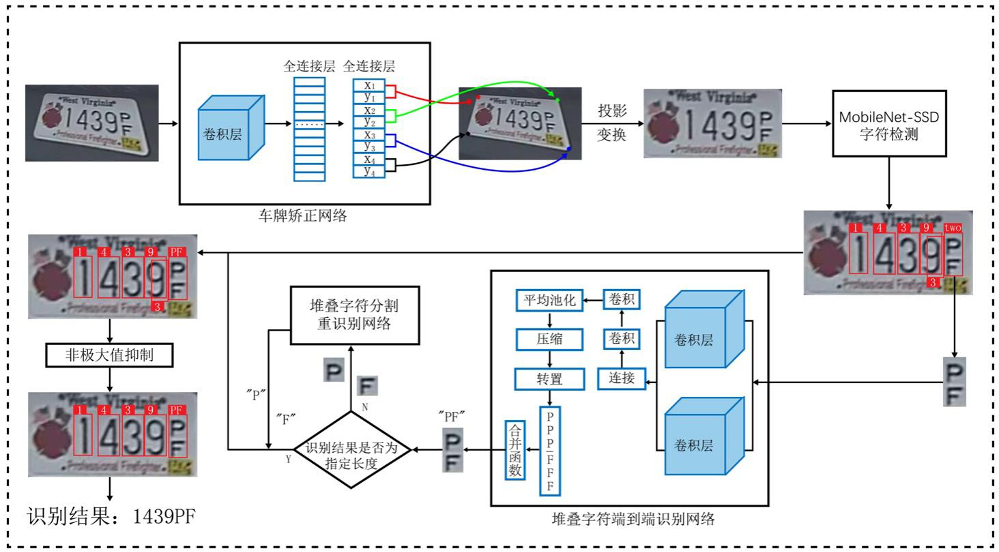
解释下其中需要训练的一些DNN网络:
| 网络名称 | 输入 | 输出 | 解释 |
|---|---|---|---|
| 车牌矫正网络 | 任意车牌图像 | 4个角点的归一化坐标 | 输入仅车牌区域,不包括整个车身 |
| MobileNet-SSD字符检测网络 | 拉正后的车牌图像 | 每个字符的坐标位置和类别 | 类别包括 10类数字+25类字母[排除O]+1类堆叠字符 |
| 堆叠字符端到端识别网络 | 堆叠字符图像 | 堆叠字符识别结果 | 使用CTC损失训练,能识别竖排不定长字符(10类数字+25类字母[排除O]) |
| 堆叠字符分割重识别网络 | 切割好的单个字符 | 单个字符识别结果 | 类别同样包括10类数字+25类字母[排除O] |
实验数据及细节
使用两个含有堆叠字符的美国地区车牌:MD州和WV州用于训练以上所有的网络,数据情况如下:

除了在【解决方案】中介绍的总体识别流程,还有一些各个模块的实验细节需要我们注意,其也能帮助提升整个识别的精度:
- 车牌矫正网络:
- 网络最后的输出层使用tanh激活函数
- 角点随机映射的数据增强:将车牌的四个角点随机映射到其某个半径范围内的任意一个点上,并对车牌进行随机拉伸变换
- 堆叠字符端到端识别网络:
- 字符检测网络使用非极大值抑制做后处理
实验结果
字符分割重识别网络的必要性
可能会产生疑问:既然堆叠字符识别网络就能识别了不定长的字符图像,那么为什么还要分割其中每个字符进行单独的识别,针对这个我做了一个单独的消融实验:

上面的表格首先表明端到端识别比分割识别的效果确实要很多,其次分割识别对端到端识别的结果也能做一个补充修正,而且鉴于端到端识别正确率已经足够高了,所以综合方法的平均耗时也无明显增加,当然如果想要达到流程设计的简洁性,直接去掉分割识别网络我觉得也是可以的。
消融实验
对于【实验细节】中提到的每个可能提升总体识别精度的方案,这里也做了一些消融实验进行验证:

从上面表格中也不难看出,车牌矫正网络和堆叠字符识别网络对于最终的识别精度有着最大的效果提升,而其他各个小细节也有着不同程度的提升效果。
此外得益于每个网络设计的简洁性,整个流程在CPU下的平均耗时也控制在43ms左右。
对比现有的方案

PS: 上述对比结果有效到该项目完成时期-2021年5月
结果可视化
这里罗列了一些实验结果的可视化效果:

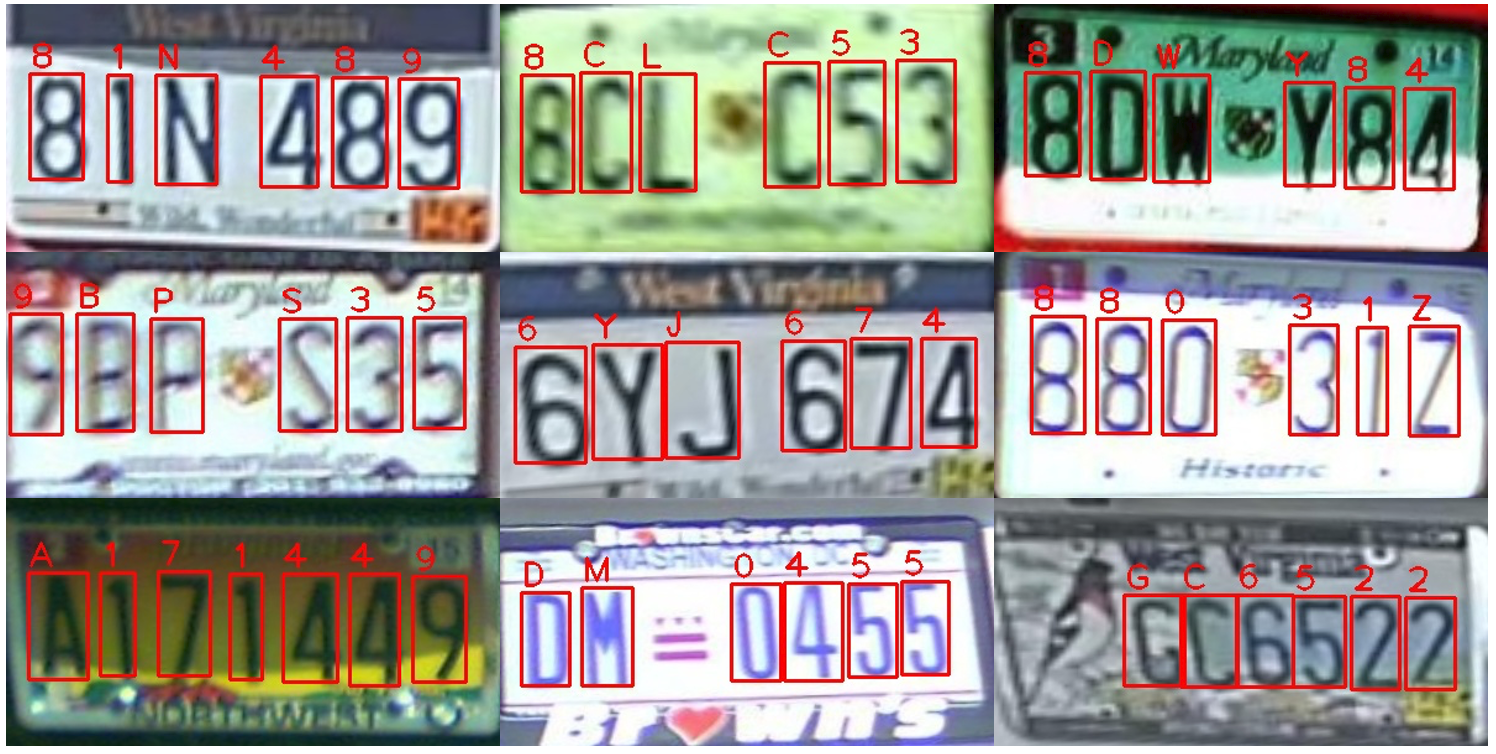
PS:为保证显示的美观性,上述车牌均是被矫正网络拉伸后的结果,原始车牌可能是存在不同程度的倾斜、扭曲。
总结
借鉴一下【论文】中的结束语: 本文从车牌识别应用的通用性角度考虑,提出了基于深度学习的含堆叠字符的车牌识别方法。该方法先通过一个卷积 神经网络定位车牌四个角点,并在投影矫正后的车牌上进行车牌识别,极大提高了对扭曲、倾斜车牌的识别鲁棒性;其次,针对车牌识别应用中含堆叠字符的特殊车牌,本文设计并提出了 一个基于 CTC损失的卷积神经网络,通过不依赖字符分割的 方式对竖排堆叠字符进行整体的端到端识别,提高了含堆叠字 符车牌的识别准确度。