我研究生期间的主要做的是一个商业性质的车牌识别项目,该三个专利也是该项目期间积累下来的一些实践经验,趁着毕业正好整理一下。

【1】一种非二值化和边缘检测的车牌字符图像分割方法
要解决的问题:解决复杂车牌(如存在字符黏连、光照不均)中的字符分割难题
算法输入:车牌的字符区域(最好是高度和字符高度接近的)
算法输出:每个车牌字符的包围框坐标
算法流程:使用一个指定宽度的滑动窗口对图像从左到右进行遍历,每次遍历使用一个二分类的网络判断滑动窗口内是否是属于车牌字符(通常为字母和数字)的概率,最后得到一个字符概率的分布曲线,最后通过非极大值抑制得到最终的字符区域。
训练数据:
训练二分类网络:(判别是否是字母/数字)使用的2类数据------->配合交叉熵分类损失
车牌字符图像 非车牌字符图像 

算法效果与对比:
输入车牌图像和检测结果(包围框) 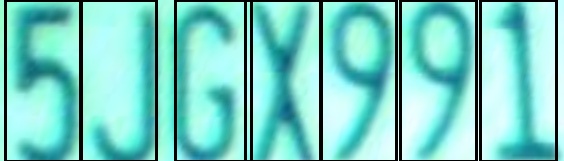

中间结果:字符概率检测结果 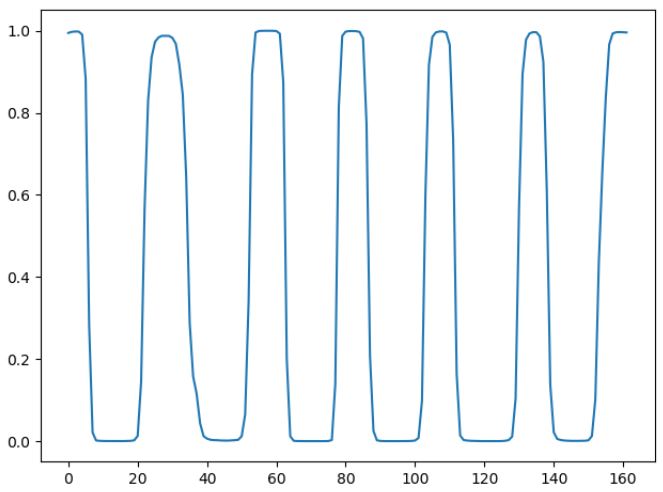
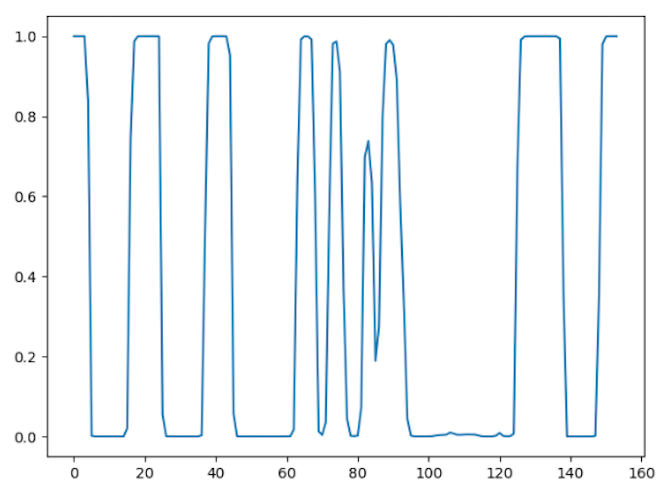
全局二值化(阈值为127) 
均值窗口下的自适应二值化 (窗口半径为11) 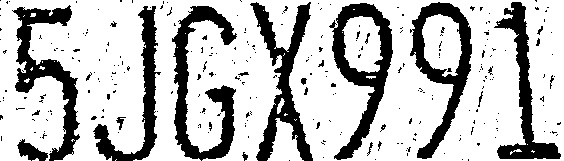
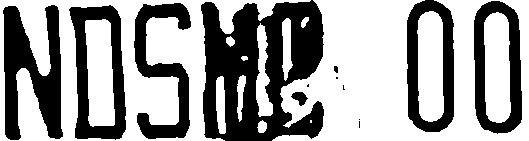
高斯窗口下的自适应二值化 (窗口半径为11) 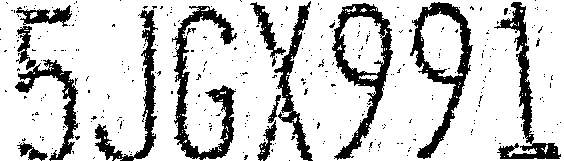

Canny边缘检测(threshold1=80,threshold=160) 
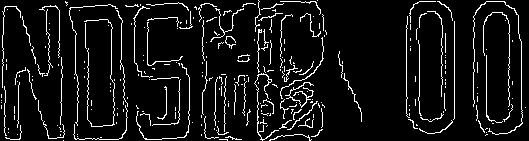
Sobel边缘检测 (窗口半径为3,dx=1,dy=0) 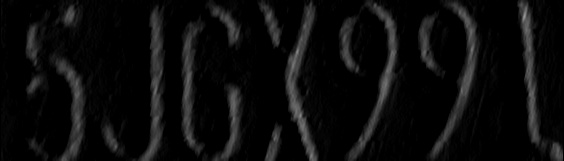

Laplacian边缘检测 (窗口半径为3) 

【2】一种基于深度学习的倾斜车牌矫正和不定长车牌识别方法
要解决的问题:倾斜扭曲严重的车牌矫正和号码长度不定的车牌识别
算法输入:整个车牌区域,已经预训练好的车牌号码区域检测网络
算法输出:车牌的四个角点坐标(用于矫正)、不定长车牌号码的识别结果
算法流程: 任意车牌送入角点预测网络得到四个角点坐标后进行投影变换拉正车牌,然后使用已经预训练好的车牌号码字符检测网络并抠出得到纯字符区域,将该字符区域送入不定长车牌号码识别网络得到最终结果
训练数据:
角点预测网络:使用整个车牌区域图片和其四个角点的归一化后坐标(x,y)------->配合MSE损失
不定长车牌号码识别 :使用仅字符区域图像和其对应的车牌号码(如"ABCDEF") ------->配合CTC损失
角点预测网络训练图片 不定长车牌识别网络训练图片 




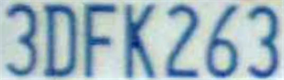
算法效果:
角点预测网络 不定长车牌识别网络 



特别说明:上表右列中蓝色框为预训练好的车牌号码检测网络输出的结果
【3】一种基于深度学习的含堆叠字符的车牌识别方法
要解决的问题:含有竖排堆叠字符的车牌号码识别
算法输入:车牌图像(可支持含竖排堆叠字符的特殊车牌)、已经预训练好的车牌号码字符检测网络(具体到每个字符,可识别"26个大写字母+10个数字+堆叠字符类")
算法输出:完整的车牌号码识别结果
算法流程:使用车牌车牌号码字符检测网络得到当前车牌中的每个字符和类别,对于其中检测到的"堆叠字符类",将该部分图像区域抠出后送入堆叠字符识别网络进行识别
训练数据:
竖排堆叠字符识别网络:使用竖排堆叠字符(含2个字符/3个堆叠字符)及对应的结果(如"AB"/“CD”) ------->配合CTC损失

算法效果:
 |
 |
|---|---|
 |
 |
 |
 |
总结
相对于为常见的车牌识别中可能存在的问题(如"倾斜扭曲"、"光照不均"),上述这些车牌识别起来更加有难度,主要体现在"堆叠字符"、"不定长号码"、"底纹黏连",上述专利则针对上述存在的通用问题或特殊问题为切入点,逐渐优化提升这些车牌识别的精度。