StyleGAN
先放一张StyleGAN生成人脸的效果图吧,确实真实到无法分辨出他是生成的,效果好到炸裂,以至于学习GAN不熟悉StyleGAN可以说说白学GAN了。

当然除了人脸,StyleGAN在其他物体上的生成效果也是非常炸裂的。

写在前面
StyleGAN对于GAN的发展和推进太重要了,论文的内容很丰富细节也很多,一直没有很好的写作思路,直到看到了这篇博客和他的两篇中文版本:Wooo.zhihu和Yuthon's Blog,发现大家写的太好了,于是近乎全文copy过来当做笔记也方便后面自己查阅,只是加了少量自己的图和理解,也建议 大家去原博客进行阅读。
研究背景
NVIDIA在2017年提出的PGGAN解决了生成高分辨率图像(如1024×1024)的问题。PGGAN的关键创新之处在于渐进式训练,即从训练分辨率非常低的图像(如4×4)的生成器和判别器开始,每次都增加一个更高的分辨率层。
存在的问题:与多数GAN一样,PGGAN控制生成图像特定特征的能力非常有限。这些属性相互纠缠,即使略微调整输入,会同时影响生成图像的多个属性。所以如何将PGGAN改为条件生成模型,或者增强其微调单个属性的能力,是一个可以研究的方向。
解决方法:StyleGAN是NVIDIA继PGGAN之后提出的新的生成网络,其主要通过分别修改每一层级的输入,在不影响其他层级的情况下,来控制该层级所表示的视觉特征。这些特征可以是粗的特征(如姿势、脸型等),也可以是一些细节特征(如瞳色、发色等)。
主要贡献
①借鉴风格迁移,提出基于样式的生成器(style-based generator)。
- 实现了无监督地分离高级属性(人脸姿势、身份)和随机变化(例如雀斑,头发)
- 实现对生成图像中特定尺度的属性的控制。
- 生成器从一个可学习的常量输入开始,隐码在每个卷积层调整图像的“样式”,从而直接控制不同尺度下图像特征的强度。
②实现了对隐空间(latent space)较好的解耦。
- 生成器将输入的隐码z嵌入一个中间的隐空间W。因为输入的隐空间Z必须服从训练数据的概率密度,这在一定程度上导致了不可避免的纠缠,而嵌入的中间的隐空间W不受这个限制,因此可以被解耦。
③提出了两个新的量化隐空间解耦程度的方法
- 感知路径长度和线性可分性。与传统的生成器体系结构相比,新的生成器允许更线性、更解耦地表示不同的变化因素。
④提出了新的高质量的人脸数据集(FFHQ,7万张1024×1024的人脸图片)
网络结构
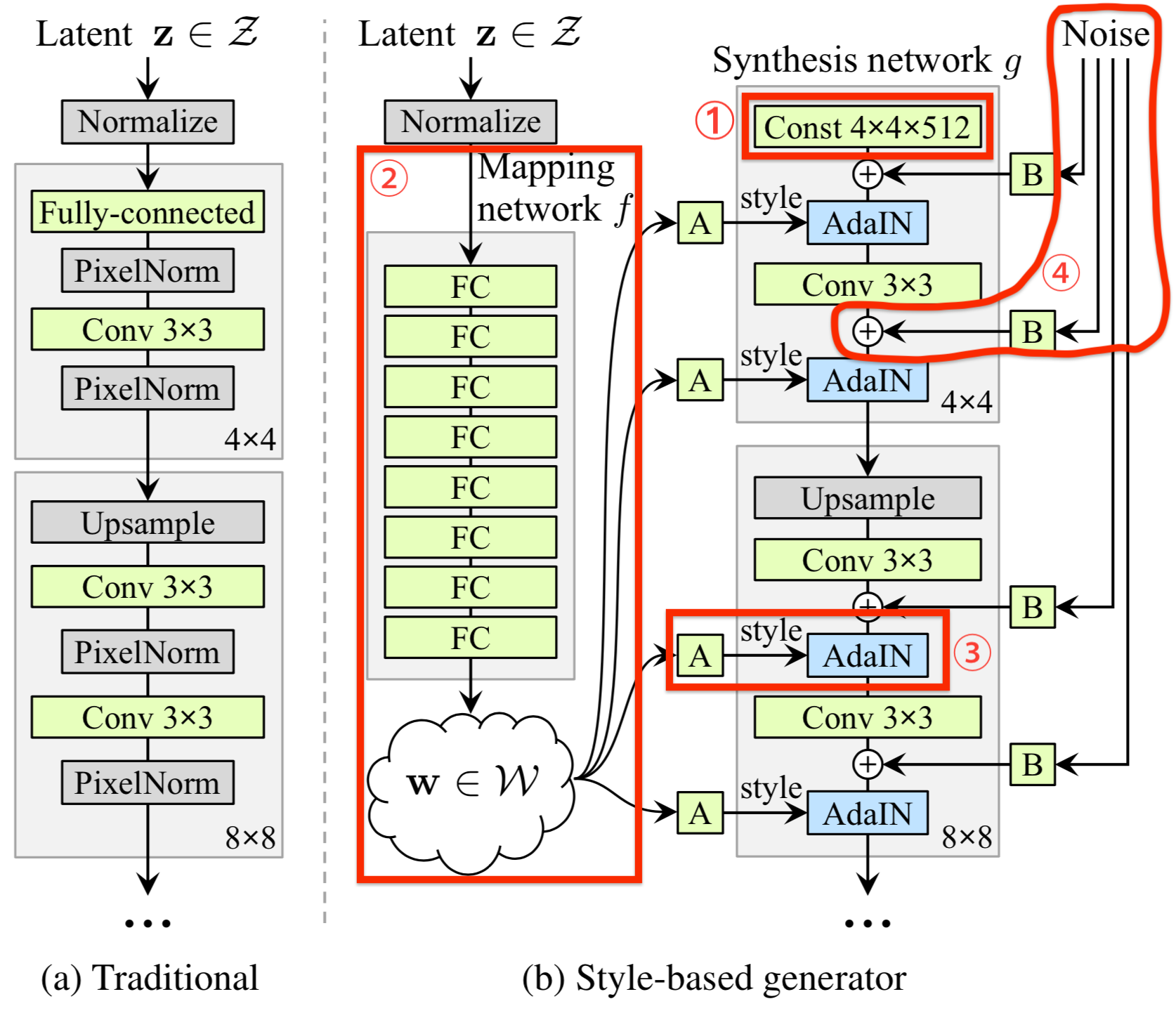
StyleGAN的生成器(b)有18层,每个分辨率有两个卷积层(4,8,16...1024),整个网络的主要特点包括:
① 移除了传统的输入(remove traditional input)
传统的生成器(a)使用latent code(随机输入)作为生成器的初始输入;StyleGAN抛弃了这种设计,将一个常数张量(Const Tensor)作为生成器的初始输入。首先可以降低由于初始输入取值不当而生成出一些不正常的照片的概率(这在GANs中非常常见),另一个好处是它有助于减少特征纠缠,保证生成结果不受Const Tensor影响而是由不同分辨率下的"style"来控制不同细粒度的特征。
② 映射网络(Mapping Network)
映射网络由8个全连接层组成,其输出w与输入z大小相同(512×1)。映射网络的目标是将输入向量z编码为中间向量w,中间向量w的不同元素控制不同的视觉特征。
使用输入向量z控制视觉特征的能力是有限的,它必须遵循训练数据的概率密度。例如,如果黑色头发的人的图像在数据集中更常见,那么更多的输入值将映射到该特性。因此该模型无法将输入向量z的一部分(向量中的元素)映射到特征,这种现象称为特征纠缠。
但是通过映射网络,该模型可以生成一个不需要跟随训练数据分布的向量w,并且可以减少特征之间的相关性(即实现解耦、特征分离)。
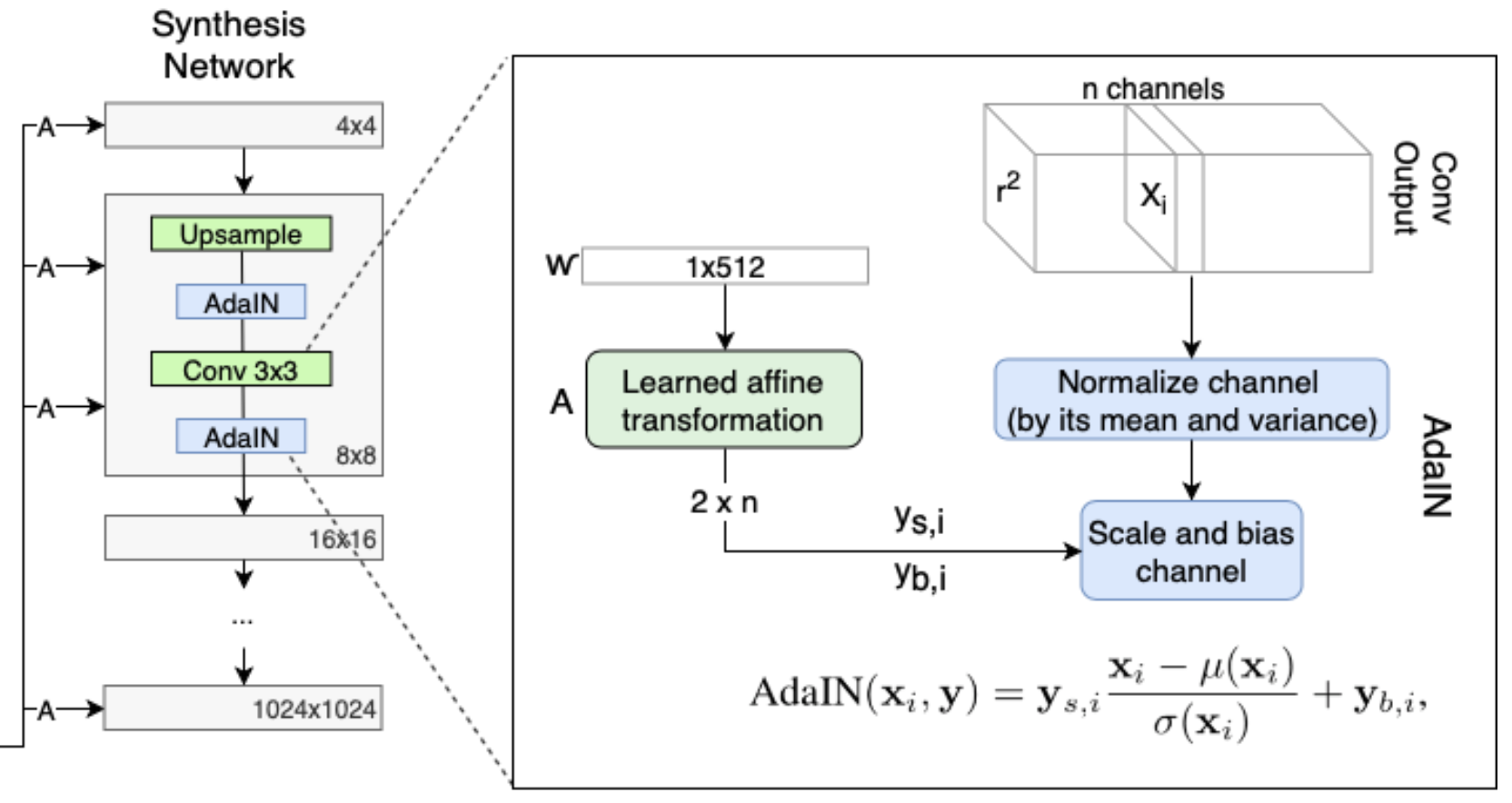
③ 样式模块(style modules,AdaIN,自适应实例归一化)
如下图所示:512×1大小的W隐向量经过广播(Broadcast)后变成18个512×1大小的向量(统称为W+空间(
))作为每一个可学习的仿射变换(A)的输入,具体计算过程如下: 3×3卷积得到的张量,每个样本张量的每个通道
独立地进行归一化(其实就是Instance Norm),即: 每个可学习的仿射变换A(全连接结构)将广播后对应的512×1大小的w向量转化为AdaIN的平移和缩放因子
该缩放因子对于每个通道都单独有一个 然后对每个通道
分别使用放射变换A中学习到的的平移和缩放因子 进行尺度和平移变换得到最终结果:
(其实上述AdaIN过程就是风格迁移中使用的算法,只不过原本AdaIN是使用风格图计算尺度缩放因子和平移因子,而这里是通过隐向量w经过放射变换A学习得到的) 上述过程可视化表示为:
④ 随机变化(Stohastic variation,通过加入噪声为生成器生成随机细节)
人脸上有很多细节可以看作是随机的,比如头发的精确位置,这些小且碎的随机特征能使图像更真实,也增加了输出的多样性。将这些小特征插入GAN图像的常用方法是向原本的输入向量中添加随机噪声,然后通过输入层输入生成器。然而,在很多情况下,控制噪声效果是很棘手的,因为特征纠缠现象,在原本的输入向量中即便是略微改变噪声会导致图像的其他特征受到影响。
StyleGAN则并非在常量输入(Const 4×4×512),也不是在隐向量z或者w中添加噪声,而是额外在每个分辨率下的特征图上添加一个不同尺度的单通道高斯噪声,然后在卷积之后、AdaIN之前将高斯噪声加入生成器网络中。B使用可学习的缩放参数scale对输入的高斯噪声进行变换,然后将噪声图像广播到所有的通道上(分别加到每个通道上,每个通道对应一个可学习的scale参数)。
其他细节
随机变化(Stochastic variation)

(b)使用相同latent code,不同噪声作为输入;整体特征是相似的,比如面部等,但是细节比如头发的形状有较大的不同;(c)是100个不同的随机噪声输入产生的图像的标准差,较亮部分是标准差较大的部分(受不同的噪声输入影响较大的部分,头发等部分),而面部姿势等高级特征不受随机变化的影响。显示了在相同底层图像输入但不同噪声实现的随机变化。噪声只影响随机方面,而保留了整体结构和身份、面部等高级特征。

上图说明了将随机变化应用于不同的层的效果(将噪声输入不同层)。(a)将噪声加入了所有层;(b)没有噪声;(c)在精细层(fine layers,64-1024)加入噪声;(d)在粗糙层(coarse layer,4-32)加入噪声。粗糙的噪声导致头发大规模卷曲,背景特征更大,而细小的噪声则使头发卷曲更细,背景细节更细,皮肤毛孔更细。
样式混合(Style mixing)
不同分辨率下的w控制不同细粒度的人脸特征,使用Style
Mixing技术可以将将两张不同图像的风格混合,具体是对两个
- 粗糙分辨率(
)的W向量(512×1)控制最终人脸的高级特征(如姿势、头发整体轮廓、脸的形状和眼镜等) - 在中间层(
)的W向量(512×1))控制最终人脸的较小尺度的面部特征(如头发的样式、眼睛的闭合等) - 在精细分辨率(
)的W向量(512×1))控制最终人脸更低的面部特征(如光线,色调等)
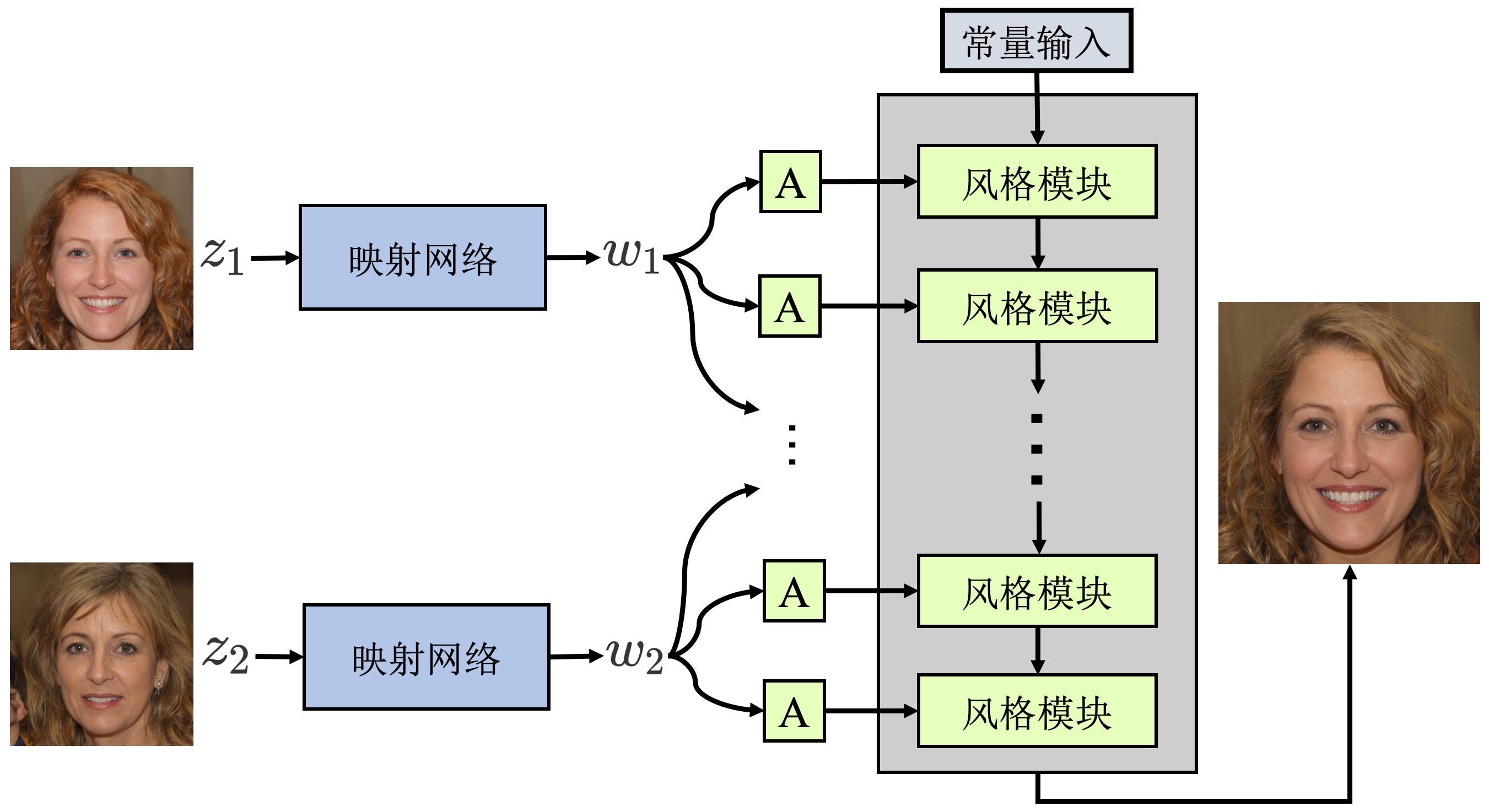
Style Mixing 的过程如上图比较清晰的介绍,组合
正则化-混合正则化(mixing regularization)
为了进一步鼓励styles的局部化(减小不同层之间样式的相关性),本文对生成器使用混合正则化。
具体方法:对给定比例的训练样本(随机选取)使用样式混合的方式生成图像。在训练过程中,使用两个随机隐码z(latent code)而不是一个,生成图像时,在合成网络中随机选择一个点(某层),从一个隐码切换到另一个隐码(其实就是Style Mixing)。具体来说,通过映射网络运行两个潜码z1、z2,并让对应的w1、w2控制样式,使w1在交点前应用,w2在交点后应用。
这种正则化技术防止网络假设相邻样式是相关的,随机切换确保网络不会学习和依赖于级别之间的相关性。
截断技巧(Truncation trick in W)
考虑到训练数据的分布,低密度区域(头发细节、皮肤纹理等)很少被表示,因此生成器很难学习该区域。通过对隐空间进行强制截断虽然会对生成图像的多样性造成损失,但是可以提升生成影像的平均质量。对中间隐码W进行截断,迫使W接近平均值,具体步骤:
在训练之后,通过多个输入z经过映射网络生成的隐向量w,得到均值
生成新图像时,将原输入Z得到的隐向量W与均值
进行插值: 其中 ,然后将得到的 送入到放射变化A进行生成 可以看到
越接近于0,则生成的图像越接近"中间脸",等于0时,那么无论输入任何Z,都得到的是相同的结果(多样性降低)
量化隐空间(latent space)耦合度
本篇论文同时提出了两种用于量化隐空间耦合度的指标
感知路径长度(Perceptual path length)
线性可分性( Linear separabilit)
这两个指标我平时用的比较少,而且我可能更加关注主观视觉效果,这里就不对这个指标展开介绍了,如果有兴趣可以去看这里或者原论文。
训练细节和超参数
StyleGAN使用8个Tesla V100 gpu对CelebA-HQ和FFHQ数据集进行为期一周的训练。在TensorFlow中实现。
不同配置config B-F在两个数据集使用不同的损失函数
CELEBA-HQ数据集使用WGAN-GP;
FFHQ数据集上如下图所示,使用非线性饱和损失,WGAN-GP+R1正则化(γ=10),使用该损失的FID值比WGAN-GP减小的时间更长,所以使用更长的训练时间
基于样式的生成器使用leak ReLU,
,所有卷积层使用相同学习率;特征图(卷积核)数量与PGGAN相同; 映射网络的学习率每两层降低一次
(映射网络深度变大时,训练不稳定)。 权重使用高斯(0,1)随机初始化;除了样式计算
的偏置初始化1,其余偏置和噪声的尺度因子初始化为0. 没有使用batch normalization、dropout
在上采样/下采样中使用线性插值采样替换 PGGAN中的最近邻插值
结论
基于样式的生成器,能生成更高质量的高分辨率图像。
实现了无监督地分离高级属性(人脸姿势、身份)和随机变化(例如雀斑,头发),实现对生成图像中特定尺度的属性的控制。通过style控制高级属性,通过不同层的style实现对不同尺度的特征的控制;通过噪声控制随机变化
降低了隐空间的耦合性。通过映射网络生成中间隐空间(intermediate latent space),中间隐空间降低了输入隐空间的纠缠
提出两种新的量化隐空间耦合性的指标-感知路径长度和线性可分性
对高级属性与随机效应的分离以及中间隐空间的线性的研究,提高了对GAN合成的理解和可控性
参考文献
StyleGAN2
研究背景

分析其中的原因,作者认为是生成器故意的规避实例归一化,通过产生强大、区域的峰值来主导数值的方式来达到目的。原StyleGAN(我们称为StyleGANv1)使用的AdaIN操作中含有Instance Norm操作,对每个张量的每个通道进行独立的独立的归一化,会导致上述图中所显示的"水滴状"伪影。
StyleGANv1回顾
在讨论StyleGANv2之前,先来回顾下StyleGANv1的具体结构。如下图所示,左图是原StyleGANv1论文中的原网络架构,右图将其中的AdaIN模块展开两个部分,即代表Instance
Norm的"Norm mean/std"和重新归一化的"Mod
mean/std",其中
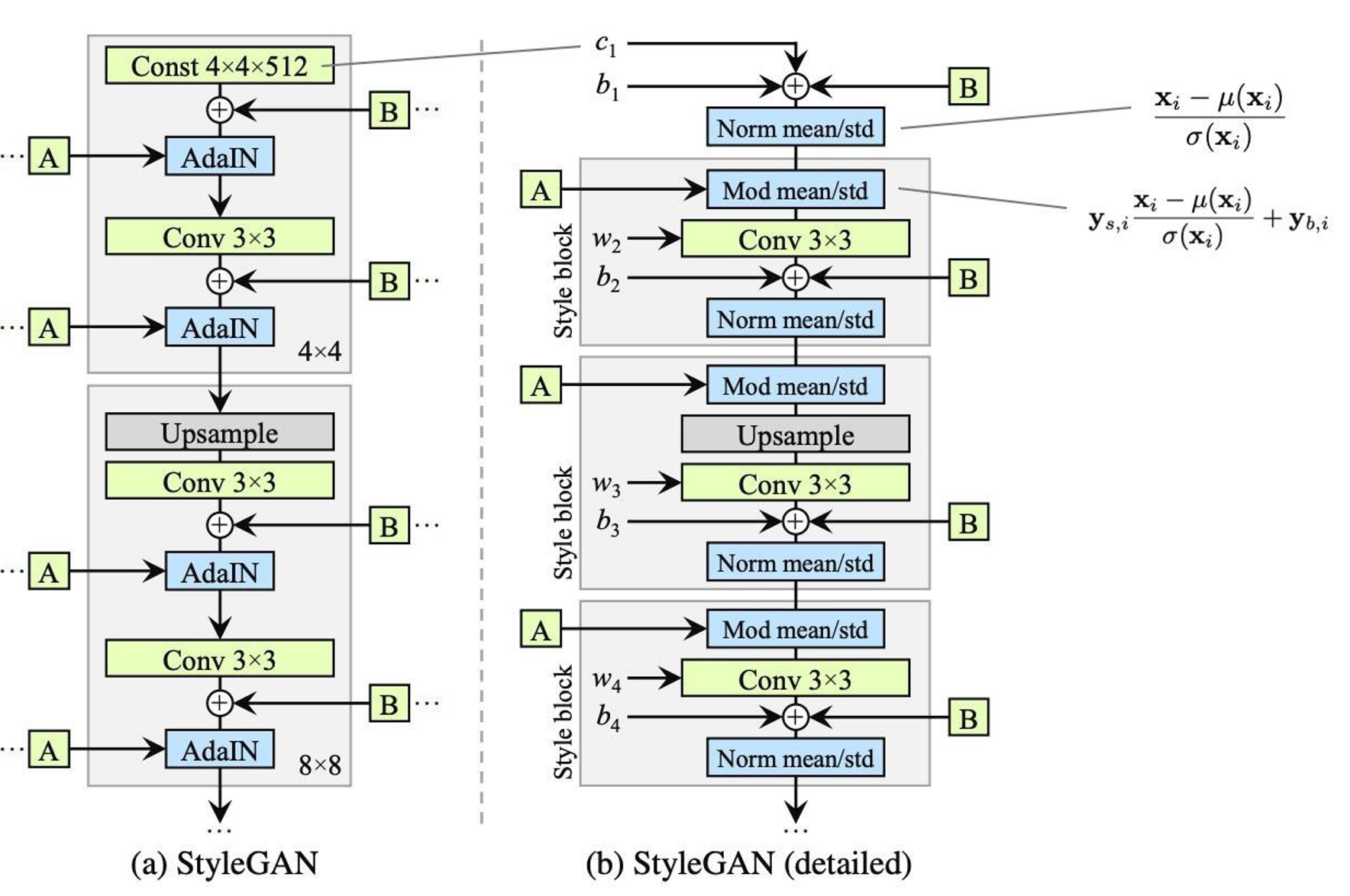
StyleGANv2的网络改进
去除Instance Norm
经过研究背景可知,为了避免出现"水滴状"的伪影,需要去掉AdaIN的Instance Norm操作,StyleGANv2中的具体做法为:
- 去掉在常量输入(Const 4×4×512)层的Instance Norm操作和添加噪声操作
- 后面所有的归一化(即"Norm mean/std" 和"Mod mean/std")均去掉取均值的操作变成"Norm std"(实例归一化模块) 和和"Mod std"(调制模块)
- 将添加噪声的操作移除出"Style block"模块(提示:StyleGANv1中添加噪声均是在每次"Norm mean/std"之前,而这里变成放在其之后进行)这样,一个style block由一个调制模块、卷积模块和一个实例归一化模块构成
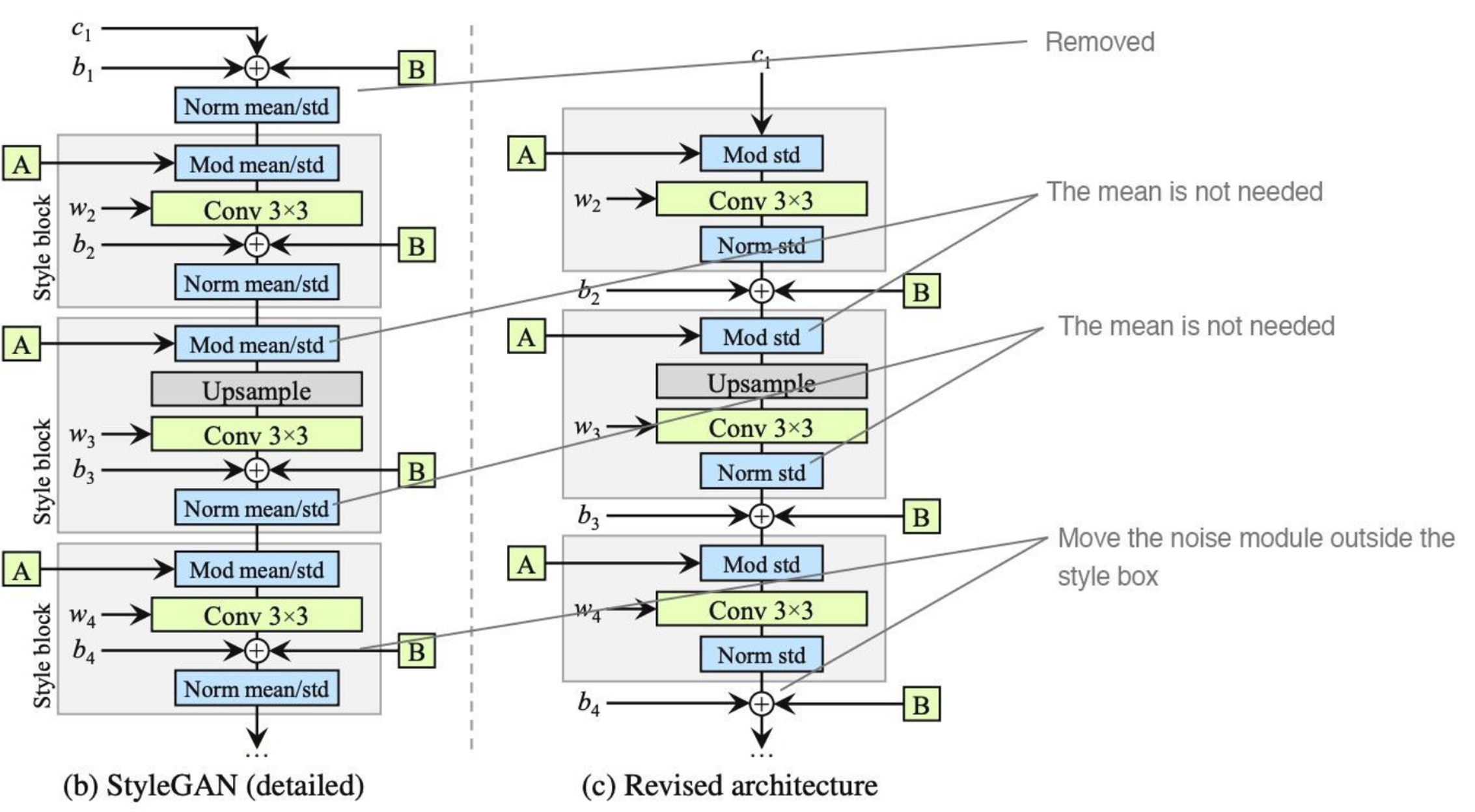
ps:上图(c)中的
权重解调(weight demodulation)
接着,为了简化网络结构,StyleGAN引入了权重解调模块,具体地改进如下:
因为去掉均值操作后, "Mod std"其实就是对激活张量中每个通道的特征值分别成
倍的缩放,且这个激活张量后面要经过3×3卷积操作(只是与卷积核 相乘,还没添加偏置),这里两部操作就可以合并成一步,即仿射变换缩放参数 与卷积核 相乘,即: 之后考虑到原本经过3×3卷积(还未添加偏置)后,特征张量要输入进"Norm std"进行归一化操作,"Mod std"(调制模块)和卷积模块之后,输出激活有着如下的标准偏差形式:
即对新的卷积核
做一个归一化: 其中,加入一个小的 ,以避免数值不稳定。 之后用最新的卷积核
与激活张量进行卷积操作,要注意的是,尽管第二部方法与Instance Norm还是有区别的,但是其能够将输出的特征张量归一化到单位方差内达到与Instance Norm相类似的效果
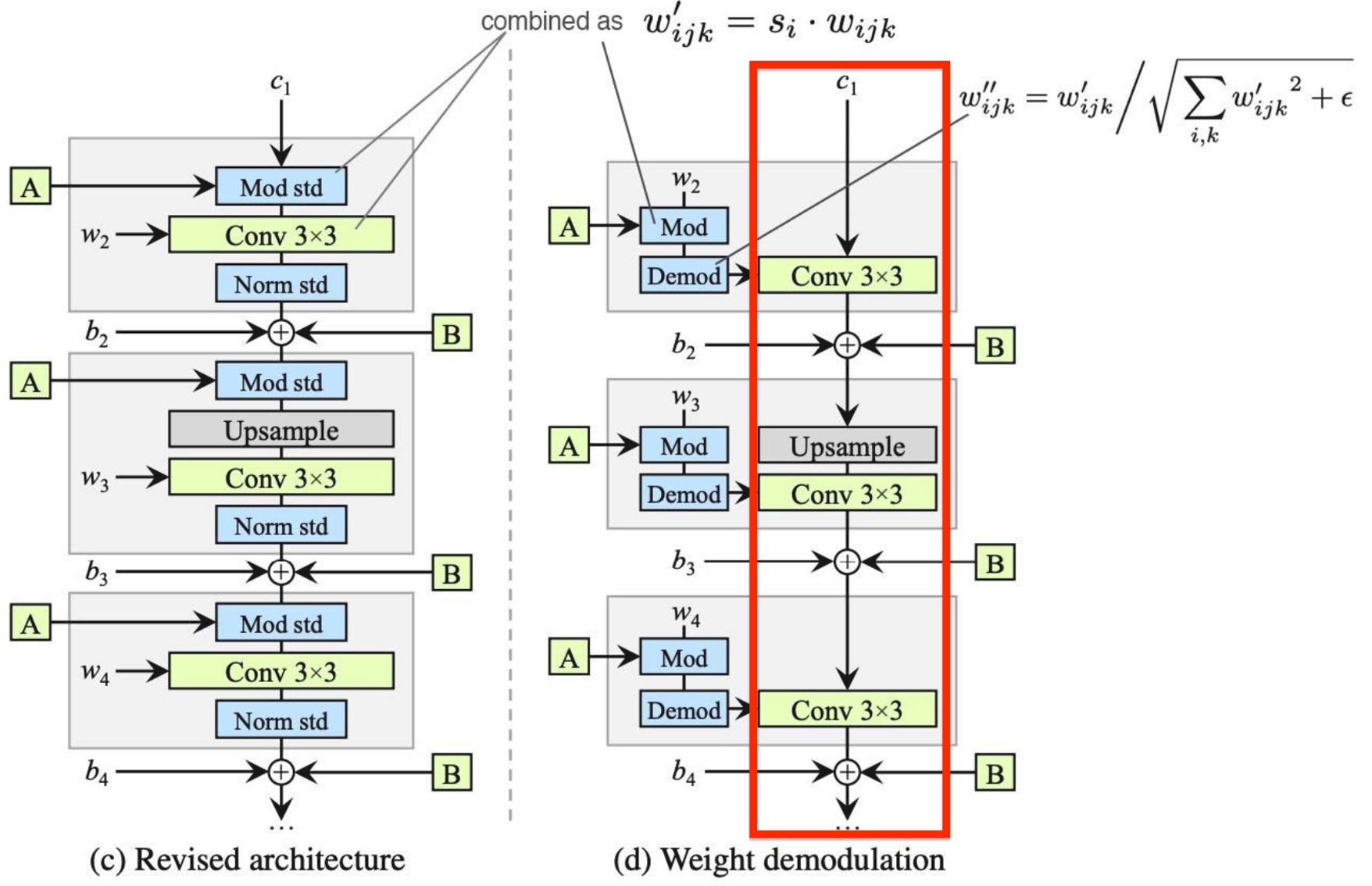
上述过程其实就是将(c)中整个style
block简化成了一个简单卷积层,只是其中的卷积核权重基于放射变换的缩放因子
重要细节补充-局部编辑
其实从上述改变后网络最终的结构可以看出,权重解调过程其实就是将原本AdaIN的两个归一化步骤分别融合到卷积操作的卷积核上面了。如果只看上图中红色框中,可以发现原始的常量输入(Const 4×4×512)在生成器网络中其实就只经过了上采样和卷积过程,所以StyleGANv2有个重要潜在的特性是:对网络中间的某个激活张量某个局部区域内的激活值调整时,完全不会影响到其他区域的变化,很适合做局部编辑。
✅ 2021.4.10 补充
该篇博客则讨论了使用StyleGAN这种特性进行局部属性编辑的引用 。
其他细节
上面其实就是StyleGANv2最重要的结构改变,当然论文中还提到了如下几个重要的技术,我也不多做介绍了,感兴趣可以自己去看哈~
Lazy regularization
Path length regularization
Progressive growing revisited
Alternative network architectures