图像转换是GAN的一个重要应用,不同于原始GAN结构从一个维度较低(如512x1)的噪声生成图像,图像转换则接受图像级别(如256x256x3)的输入,并在保证云输入图像主要特征(如结构、人脸id)的情况下输出具有其他风格的相同尺寸图像。

DTN
【Domain Transfer Network 】【官方代码】【复现代码】
算法笔记
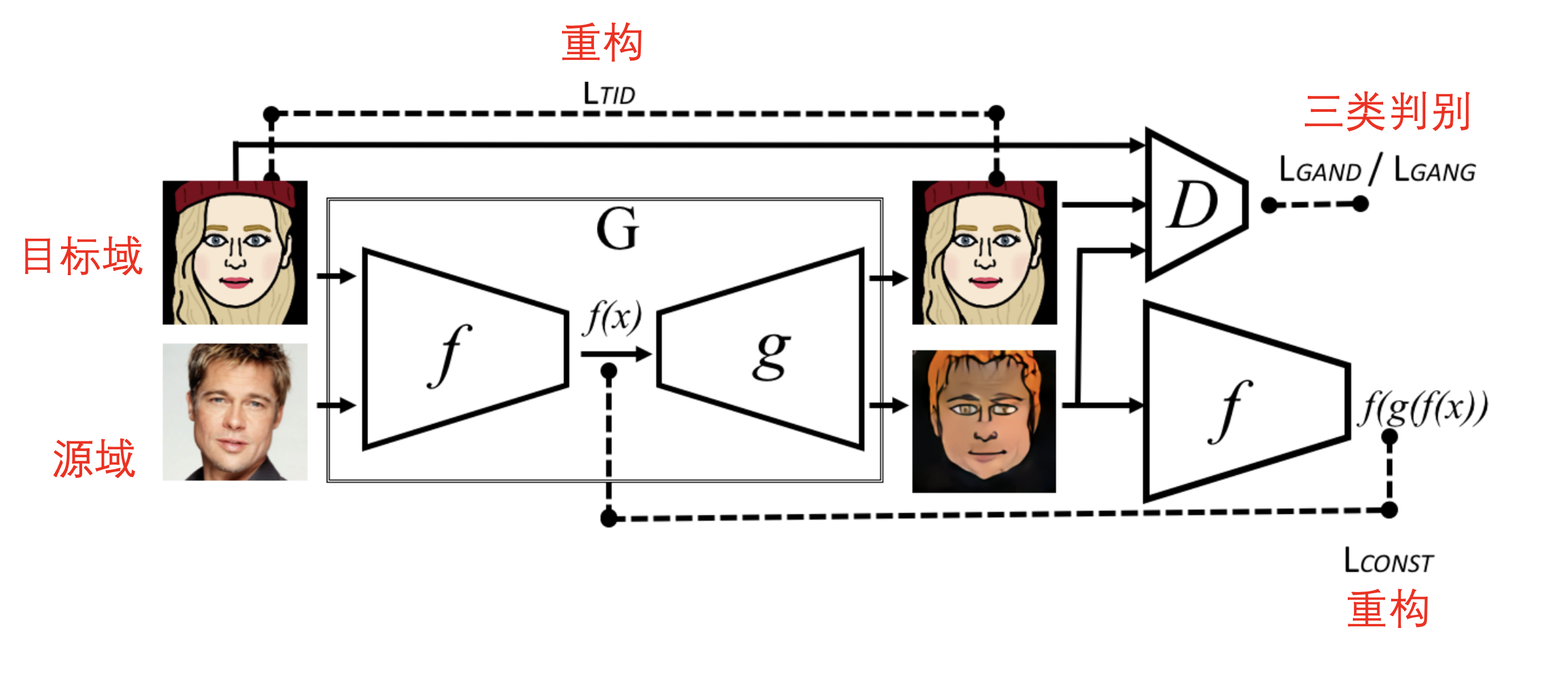
目标任务:将源于的图像S转换到目标域T中,并且在保留源域主要特征(如人脸id)的同时也具有目标域的特征(如卡通特征)。
算法细节:
网络结构:生成器G完成image2image任务,其由特征提取器f和重构器g构成;判别器D为三类判别,判别输入图像是否来自1.目标域真实图像;2.目标域重构生成的图像;3.源域转化生成的图像
网络损失:
其中 表示判别器D共有3个输出概率,判断输入的图像来自三个域的可能性; 则希望将从源域和目标域生成的图像都尽量拉近源域的分布(这里即卡通风格); 和 则为重构损失,希望目标域特征和从目标域生成的风格化图像特征一致,希望从目标域生成的风格化图像和目标域图像一致; 则是GAN中经常会使用到的平滑损失,保证生成图像不过于尖锐。 其他注意事项:
源域的图像是具有类别标签的
特征提取器需要在源域图像和源域标签上进行预训练,使用该预训练进行语义的对齐(比如保证类别不变/人物id不变)
生成效果
这里使用SVHN数据集作为源域、Mnist数据集作为目标域,使用上述DTN算法进行实验和效果复现,将SVHN的数字转换到Mnist风格的数据,并保持数字标签不变。

Pix2Pix
算法笔记
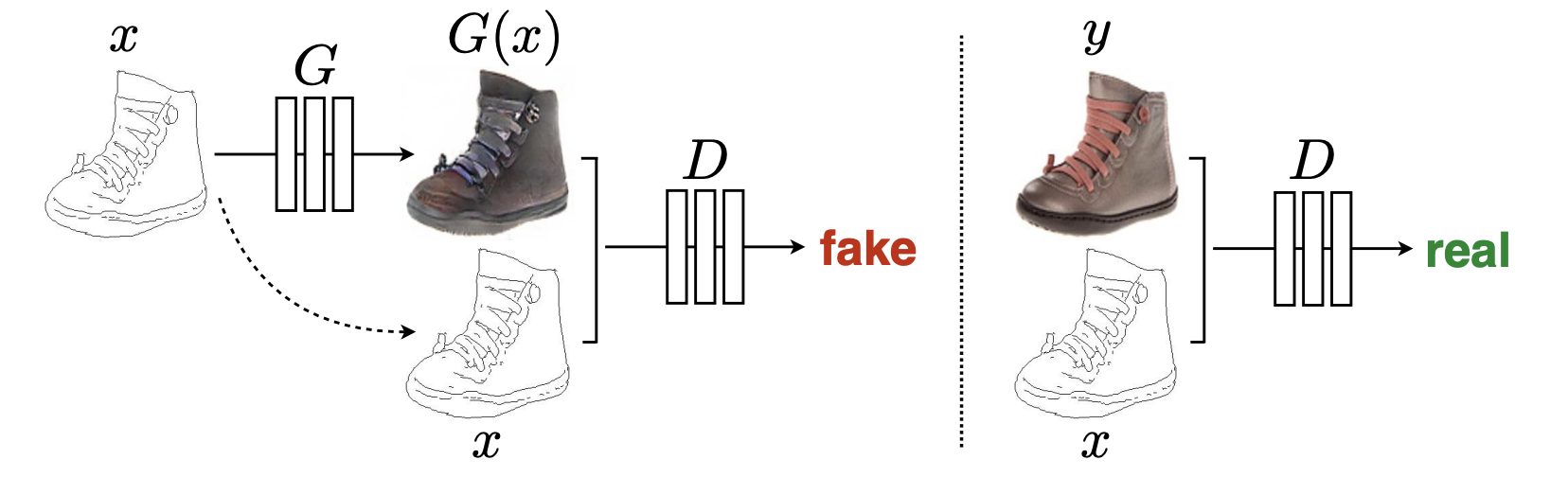
目标任务:其将源域中的图像转换到目标域中对应的图像,保持源域的id引入目标域的风格
算法细节:
训练数据:是一个有监督方法,其在源域中的每个图像均在目标域中存在对应的pair对并且是像素级别对齐的
网络结构: 生成器是一个U-Net形式的生成器,判别器则利用Patch-GAN的方式进行优化,即其鉴别输入图像的每个"Patch"是来自源域或目标域,而并非像一般GAN对图像的整体进行0/1判断,该判别方式对图像的细节进行判别并提升细节生成质量。
输入形式:生成器和判别器是一个cGAN的形式,即其接受源域和目标域的pair对进行生成/判别
网络损失:
算法应用:灰度图上色、线稿图上色、分割语义图转照片
生成效果
与CycleGAN不同,Pix2Pix算法是一个单向转换算法,如果需要在两个域互相转换,需要独立训练各自的(生成器、判别器)
 |
 |
|---|
CycleGAN
算法笔记
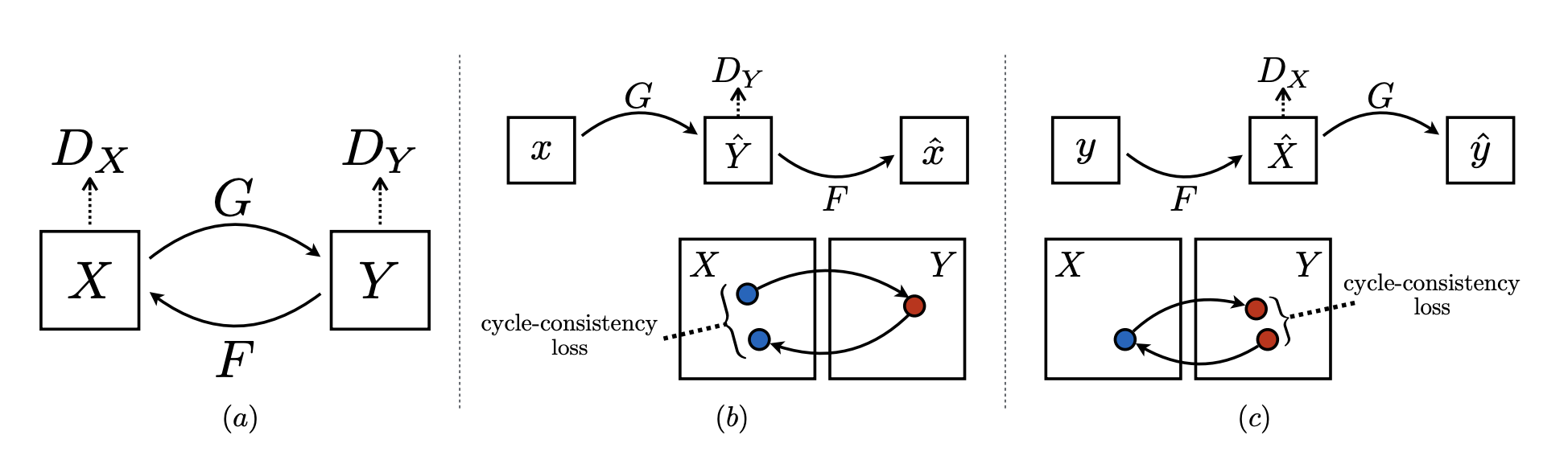
算法目标:两个域的图像互相是对方的目标域,完成两个域之间的相互转换
算法细节:
训练数据:该算法是一个无监督算法,两个域之间的图像不存在对应关系
网络结构:两个域
和 互为目标域切存在各自的生成器和判别器,分别负责将图像从 转向 和从 转向 ,当然地也存在两个判别器判断输入图像是否是来自 或 域 网络损失:
其中 表示从 域到 域的生成器和从 域到 域的生成器,中 表示循环一致性损失,也是CycleGAN实现在无监督方案下完成图像转换的核心,其核心思想是通过两个生成器将某个域图像转到另一个域再转换回自己域的时候,得到自己本身。
生成效果
 |
 |
|---|
其他同类算法
和CycleGAN同期出了两篇论文-DiscoGAN和DualGAN,这两篇论文的核心思想和上面的非常接近,甚至连损失函数都是基本一致的,即使用两个域的GAN损失和重构损失,具体算法示意图如下:
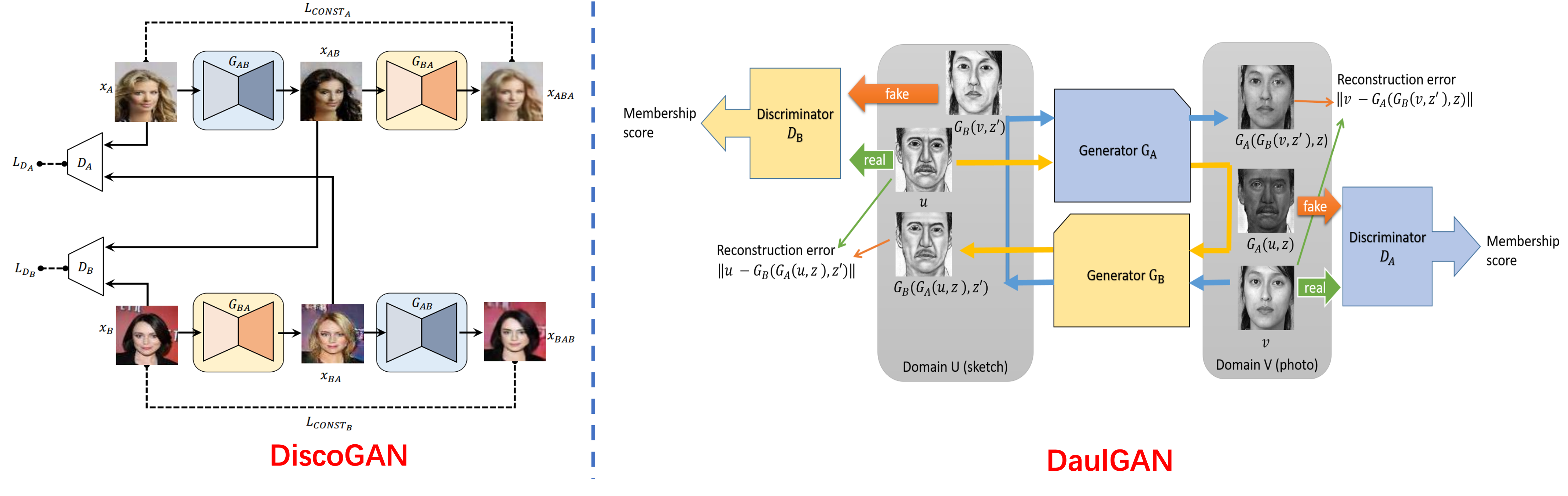
三者在网络结构上会略有不同:
| 生成器 | 判别器 | |
|---|---|---|
| CycleGAN | 采用感知损失(perceptual loss) 的风格迁移架构,有 Residual Block并且也用了 instance normalization | PatchGAN局部判别 |
| DiscoGAN | 和 DCGAN 比较相似,是和简单的 Conv-DeConv 结构 | 也是和DCGAN一样使用简单的结构 |
| DualGAN | 采用和 Pix2Pix相同的 U-Net 对称结构,同时也包含了 Residual Block以及WGAN损失 | PatchGAN局部判别 |
我这里对DiscoGAN和DualGAN也做了简单复现,放一下效果吧:
| 线稿转彩图 | 彩图转线稿 | |
|---|---|---|
| DiscoGAN复现效果 |  |
 |
| DaulGAN复现效果 |  |
 |
CartoonGAN
算法笔记
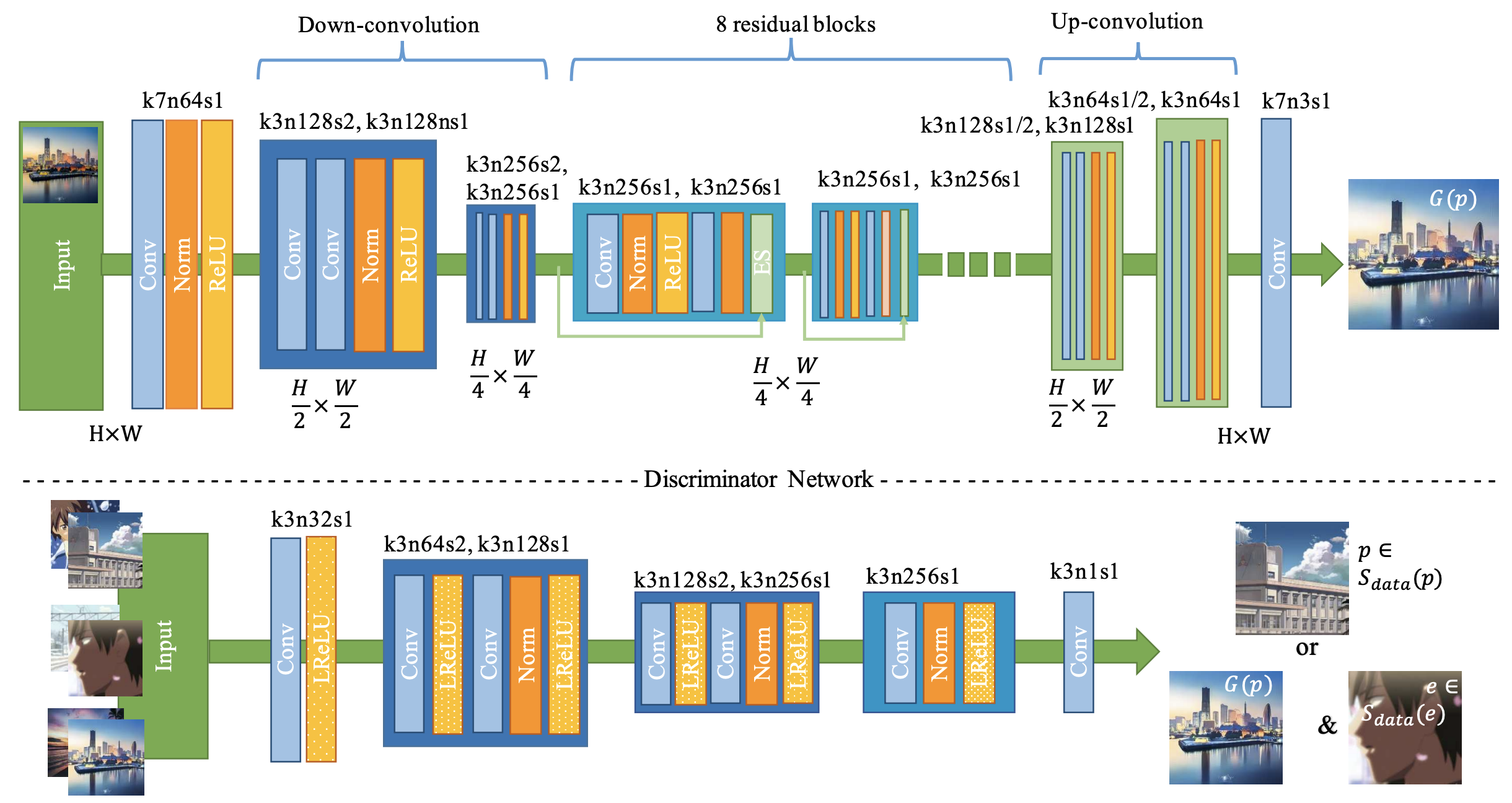
算法目标:将真实图像转换为卡通风格的图像,同时保留原图的结构信息
算法细节:
训练数据:无需成对的(真实图片,卡通图片)数据集
算法先验:卡通片通常具有比较清晰的边界,所以这里的判别器会判断来自三个域中的哪一个域(真实图像、模糊边界的卡通图像、真实的卡通图像)
网络损失:
其中判别器输出三类预测结果,其将真实照片和模糊了边界的卡通图像都当做是"假"图像,后者损失能够迫使生成器的结果具有像卡通图一样更加清晰的轮廓边界;其中 表示内容损失,保证生成的卡通图像能够保持原图的语义信息。 训练策略:随机的网络初始化容易让GAN生成崩塌,这里作者提出了"Initialization phase",即只使用(4-2)的内容损失进行预训练,然后再加上对抗损失一起训练。
生成效果

其他同类算法
在CartoonGAN后又出现了很多对真实图像卡通画的技术,其中比较有代表性是AnimeGAN和White-box-Cartoonization。
SRGAN
算法笔记
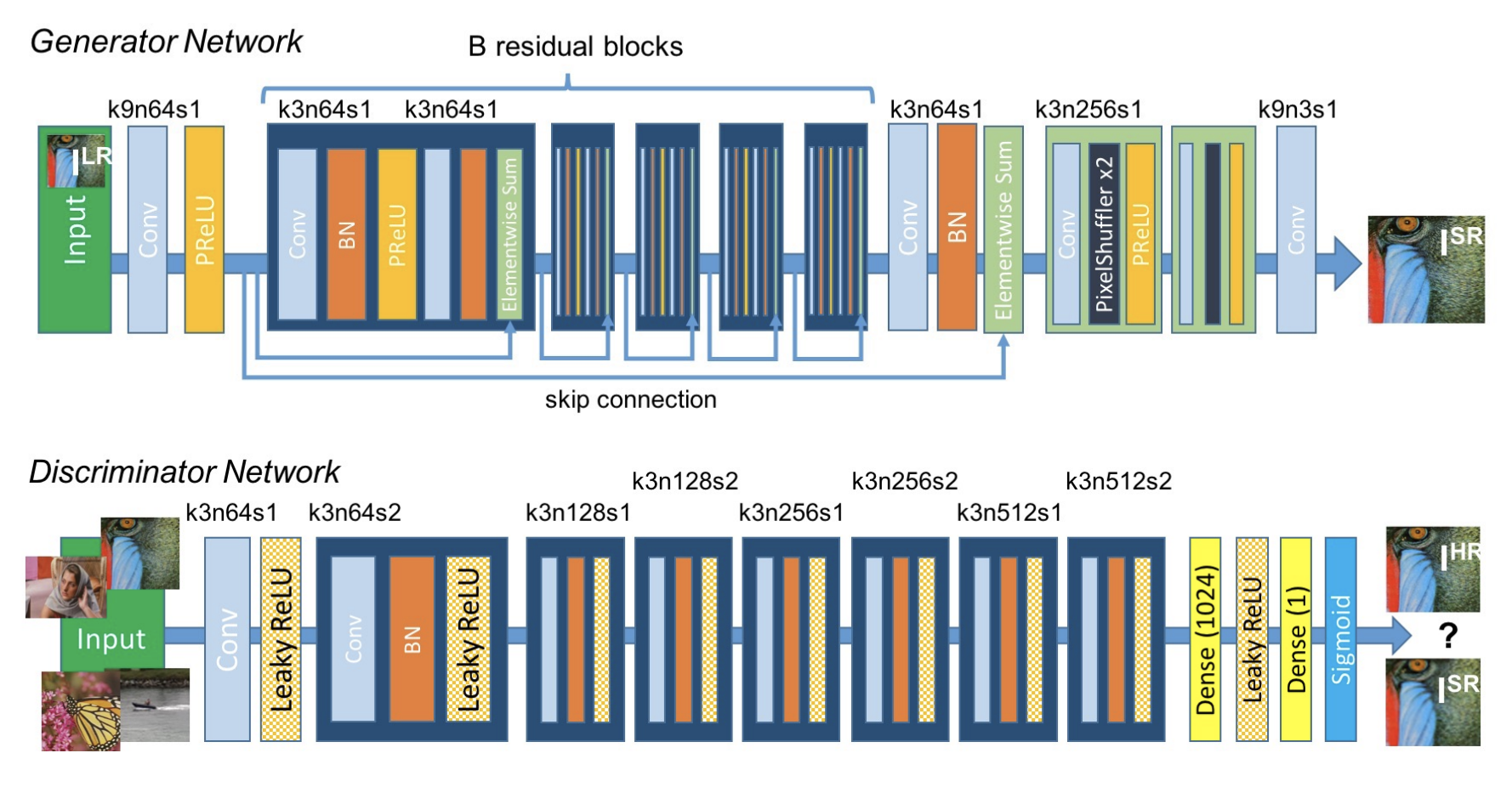
算法细节:
算法目标:对图像做超分,即在提升分辨率的同时保持清晰度
损失函数:
其中 分别表示低分辨率和高分辨率的图像,(5-2)表示在vgg特征图上计算内容损失,这相比直接在像素空间计算MSE能够避免图像模糊。
生成效果
| 低分辨率图 | 直接4倍上采样 | SR结果 | GT |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
其他同类算法
SRGAN作为使用GAN进行图像超分的开山之作,其思想和实现都简单有效,后续在此基础上又出现了较多同样使用GAN做图像超分的算法,比较有代表性的有ESRGAN和Real-ESRGAN